Summaries of all papers discussed in the survey paper on autonomous vision.
It is very likely that we have missed several highly important works. Therefore, we appreciate every feedback from the community on what we should add. If you have comments, please send an E-Mail to . We will take every comment into consideration for the next version of the survey paper.
Taxonomy
Toogle the topics (colorized) to show only literature from the selected categories and click on papers (black) to get details.
Zoom and move around with normal map controls. For a simple list of topics click on the list tab.
Created using D3.js
Summaries
Sort literature according to: Title | Author | Conference | Year
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
IJRR 2016
Carlevaris-Bianco2016IJRR | |||
| Object Detection State of the Art on KITTI | |||
|
Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monocular image[scholar]
|
CVPR 2017
Chabot2017CVPR | ||
| Object Tracking State of the Art on MOT & KITTI | |||
|
Online Multi-object Tracking Using CNN-Based Single Object Tracker with Spatial-Temporal Attention Mechanism[scholar]
|
ICCV 2017
Chu2017ICCV | ||
| Object Tracking State of the Art on MOT & KITTI | |||
|
FAMNet: Joint Learning of Feature, Affinity and Multi-dimensional Assignment for Online Multiple Object Tracking[scholar]
|
ARXIV 2019
Chu2019ARXIV | ||
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
2018 IEEE Conference on Computer Vision and Pattern Recognition 2018
Huang2018CVPRa | |||
| Sensors Camera Models | |||
|
The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and SLAM[scholar]
|
IJRR 2017
Mueggler2017IJRR | ||
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
Workshop of Computer Vision (WVC) 2017
Pereira2017WVC | |||
| Datasets & Benchmarks Synthetic Data Generation using Game Engines | |||
|
ACM Multimedia Open Source Software Competition 2017
Qiu2017ACM | |||
| Object Tracking State of the Art on MOT & KITTI | |||
|
Tracklet Association Tracker: An End-to-End Learning-based Association Approach for Multi-Object Tracking[scholar]
|
ARXIV 2018
Shen2018ARXIV | ||
| Multi-view 3D Reconstruction Problem Definition | |||
|
Proc. of the ISPRS Workshop Land Surface Mapping and Characterization Using Laser Altimetry 2001
Vosselman2001ISPRS | |||
| Object Tracking Methods | |||
|
Efficient track linking methods for track graphs using network-flow and set-cover techniques[scholar]
|
CVPR 2011
Wu2011CVPRb | ||
| Semantic Segmentation State of the Art on Cityscapes | |||
|
Dense Relation Network: Learning Consistent and Context-Aware Representation for Semantic Image Segmentation[scholar]
|
ICIP 2018
Zhuang2018ICIP | ||
| Semantic Segmentation Methods | |||
|
ECCV 2012
Alvarez2012ECCV | |||
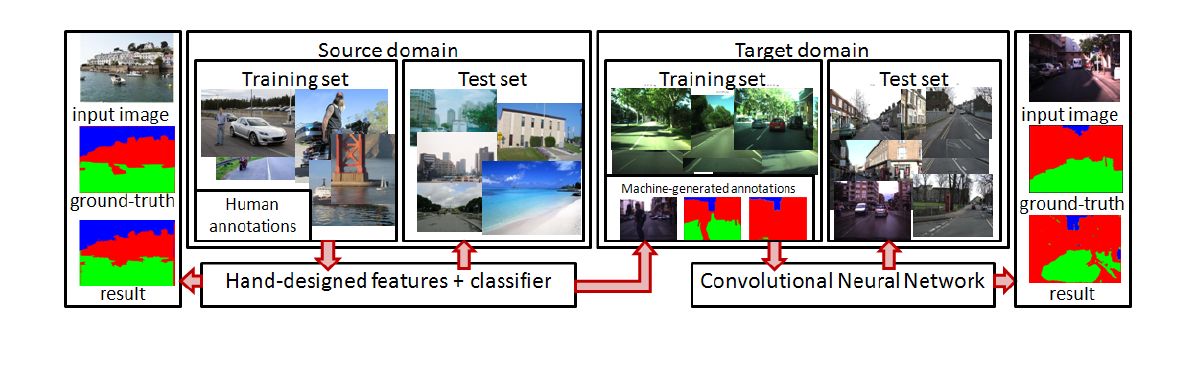
- Recovering the 3D structure of the road scenes
- Convolutional neural network to learn features from noisy labels to recover the 3D scene layout
- Generating training labels by applying an algorithm trained on a general image dataset
- Train network using the generated labels to classify on-board images (offline)
- Online learning of patterns in stochastic random textures (i.e. road texture)
- Texture descriptor based on a learned color plane fusion to obtain maximal uniformity in road areas
- Offline and online information are combined to detect road areas in single images
- Evaluation on a self-recorded dataset and CamVid
| Semantic Segmentation Methods | |||
|
TITS 2011
Alvarez2011TITS | |||

- Identifying road pixels is a major challenge due to the intraclass variability caused by lighting conditions. A particularly difficult scenario appears when the road surface has both shadowed and nonshadowed areas
- Proposes a novel approach to vision-based road detection that is robust to shadows
- Contributions:
- Uses a shadow-invariant feature space combined with a model-based classifier
- Proposes to use the illuminant-invariant image as the feature space
- This invariant image is derived from the physics behind color formation in the presence of a Planckian light source, Lambertian surfaces, and narrowband imaging sensors.
- Sunlight is approximately Planckian, road surfaces are mainly Lambertian, and regular color cameras are near narrowband
- Evaluates on self-recorded data
| Stereo Methods | |||
|
JMLR 2016
Zbontar2016JMLR | |||
- Matching cost computation by learning a similarity measure on patches using a CNN
- Siamese network with normalization and cosine similarity in the end
- Fast architecture and accurate architecture (+fully connected layers)
- Binary classification of similar and dissimilar pairs
- Sampling negatives in the neighbourhood of the positive
- Margin loss
- A series of post-processing steps:
- cross-based cost aggregation, semiglobal matching, a left-right consistency check, subpixel enhancement, a median filter, and a bilateral filter
- The best performing on KITTI 2012, 2015 datasets
| Optical Flow Methods | |||
|
JMLR 2016
Zbontar2016JMLR | |||
- Matching cost computation by learning a similarity measure on patches using a CNN
- Siamese network with normalization and cosine similarity in the end
- Fast architecture and accurate architecture (+fully connected layers)
- Binary classification of similar and dissimilar pairs
- Sampling negatives in the neighbourhood of the positive
- Margin loss
- A series of post-processing steps:
- cross-based cost aggregation, semiglobal matching, a left-right consistency check, subpixel enhancement, a median filter, and a bilateral filter
- The best performing on KITTI 2012, 2015 datasets
| Semantic Segmentation Methods | |||
|
CVPR 2010
Alvarez2010CVPR | |||
- Visionbased road detection
- Current methods:
- Based on low-level features only
- Assuming structured roads, road homogeneity, and uniform lighting conditions
- Information at scene, image and pixel level by exploiting sequential nature of the data
- Low-level, contextual and temporal cues combined in a Bayesian framework
- Contextual cues as horizon lines, vanishing points, 3D scene layout and 3D road stages
- Robust to varying imaging conditions, road types, and scenarios (tunnels, urban and high-way)
- Combined cues outperforms all other individual cues.
| Optical Flow Methods | |||
|
IJCV 1989
Anandan1989IJCV | |||
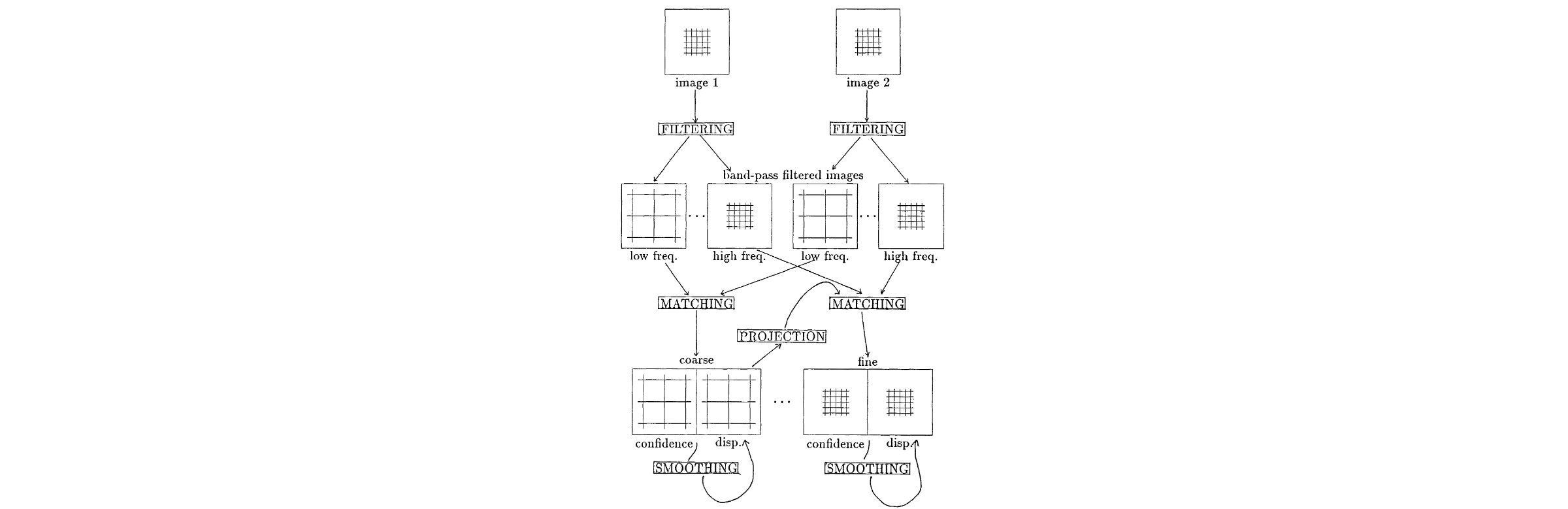
- Hierarchical computational framework for dense displacements fields from image pairs
- Based no a scale-based separation of image intensity information
- Rough estimates are firstly obtained from large-scale intensity information
- Refinement using intensity information at smaller scales
- Additionally a direction-dependent confidence measure is proposed
- Smoothness constraint propagates information with high confidence to neighbors with low confidence
- Computations are pixel-parallel, uniform across the image and based on information in a small neighborhood
- Demonstration on real images and two more hierarchical gradient-based algorithms are shown to be consistent with the framework besides the proposed one
| Object Tracking Methods | |||
|
CVPR 2010
Andriluka2010CVPR | |||

- 3D pose estimation from image sequences using tracking by detection
- Methods so far worked well in controlled environments but struggle with real world scenarios
- Three staged approach
- Initial estimate of 2D articulation and viewpoint of the person using an extended 2D person detector
- Data association and accumulation into robust estimates of 2D limbs positions using a HMM based tracking approach
- Estimates used as robust image observation to reliably recover 3D pose in a Bayesian framework using hGPLVM as temporal prior
- Evaluation on HumanEva II and a novel real world dataset TUD Stadtmitte for qualitative results
| Object Tracking Methods | |||
|
CVPR 2008
Andriluka2008CVPR | |||
- Combining detection and tracking in a single framework
- Motivation:
- People detection in complex street scenes, but with frequent false positives
- Tracking for a particular individual, but challenged by crowded street scenes
- Extension of a state-of-the-art people detector with a limb-based structure model
- Hierarchical Gaussian process latent variable model (hGPLVM) to model dynamics of the individual limbs
- Prior knowledge on possible articulations
- Temporal coherency within a walking cycle
- HMM to extend the people-tracklets to possibly longer sequences
- Improved hypotheses for position and articulation of each person in several frames
- Detection and tracking of multiple people in cluttered scenes with reoccurring occlusions
- Evaluated on TUD-Campus dataset
| Object Tracking Datasets | |||
|
CVPR 2008
Andriluka2008CVPR | |||
- Combining detection and tracking in a single framework
- Motivation:
- People detection in complex street scenes, but with frequent false positives
- Tracking for a particular individual, but challenged by crowded street scenes
- Extension of a state-of-the-art people detector with a limb-based structure model
- Hierarchical Gaussian process latent variable model (hGPLVM) to model dynamics of the individual limbs
- Prior knowledge on possible articulations
- Temporal coherency within a walking cycle
- HMM to extend the people-tracklets to possibly longer sequences
- Improved hypotheses for position and articulation of each person in several frames
- Detection and tracking of multiple people in cluttered scenes with reoccurring occlusions
- Evaluated on TUD-Campus dataset
| Object Tracking Methods | |||
|
CVPR 2011
Andriyenko2011CVPR | |||

- Existing methods limit the state space, either by per-frame non-maxima suppression or by discretizing locations to a coarse grid
- Contributions:
- Target locations are not bound to discrete object detections or grid positions, therefore defined in case of detector failure, and that there is no grid aliasing
- Proposes that convexity is not the primary requirement for a good cost function in the case of tracking.
- New minimization procedure is capable of exploring a much larger portion of the search space than standard gradient methods
- Evaluates on sequences from terrace1,terrace2, VS-PETS2009, TUD-Stadtmitte datasets
| Object Tracking Methods | |||
|
CVPR 2012
Andriyenko2012CVPR | |||
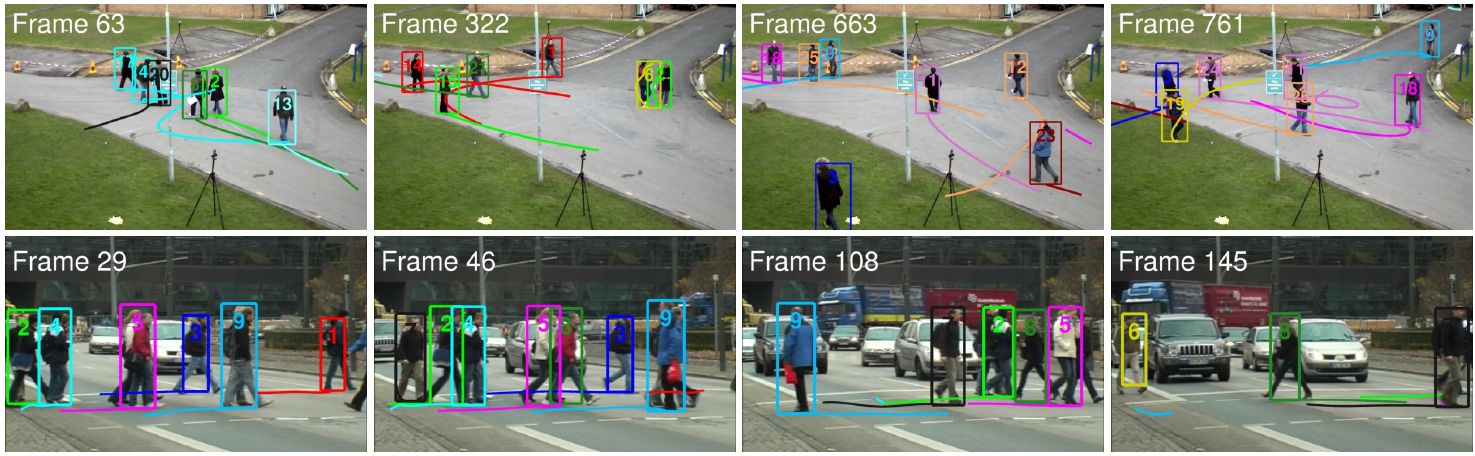
- Multi-target tracking consists of the discrete problem of data association and the continuous problem of trajectory estimation
- Both problems were tackled separately using precomputed trajectories for data association
- Discrete-continuous optimization that jointly addresses data association and trajectory estimation
- Continuous trajectory model using cubic B-splines
- Discrete association using a MRF that assigns each observation to a trajectory or identifies it as outlier
- Combined formulation with label costs to avoid too many trajectories
- Evaluation on the TUD datasets
| Mapping, Localization & Ego-Motion Estimation Problem Definition | |||
|
COMPUTER 2010
Anguelov2010COMPUTER | |||

- Google Street View captures panoramic imagery of streets in hundreds of cities in 20 countries
- Technical challenges in capturing, processing, and serving street-level imagery
- Developed sophisticated hardware, software and operational processes
- Pose estimation using GPS, wheel encoder, and inertial with an online Kalman-filter-based algorithm
- Camera system consisting of 15 small cameras using 5 MP CMOS
- Laser range data is aggregated and simplified by fitting a coarse mesh
- Supports 3D navigation
| Mapping, Localization & Ego-Motion Estimation Mapping | |||
|
COMPUTER 2010
Anguelov2010COMPUTER | |||
- Google Street View captures panoramic imagery of streets in hundreds of cities in 20 countries
- Technical challenges in capturing, processing, and serving street-level imagery
- Developed sophisticated hardware, software and operational processes
- Pose estimation using GPS, wheel encoder, and inertial with an online Kalman-filter-based algorithm
- Camera system consisting of 15 small cameras using 5 MP CMOS
- Laser range data is aggregated and simplified by fitting a coarse mesh
- Supports 3D navigation
| Semantic Instance Segmentation Methods | |||
|
CVPR 2014
Arbelaez2014CVPR | |||
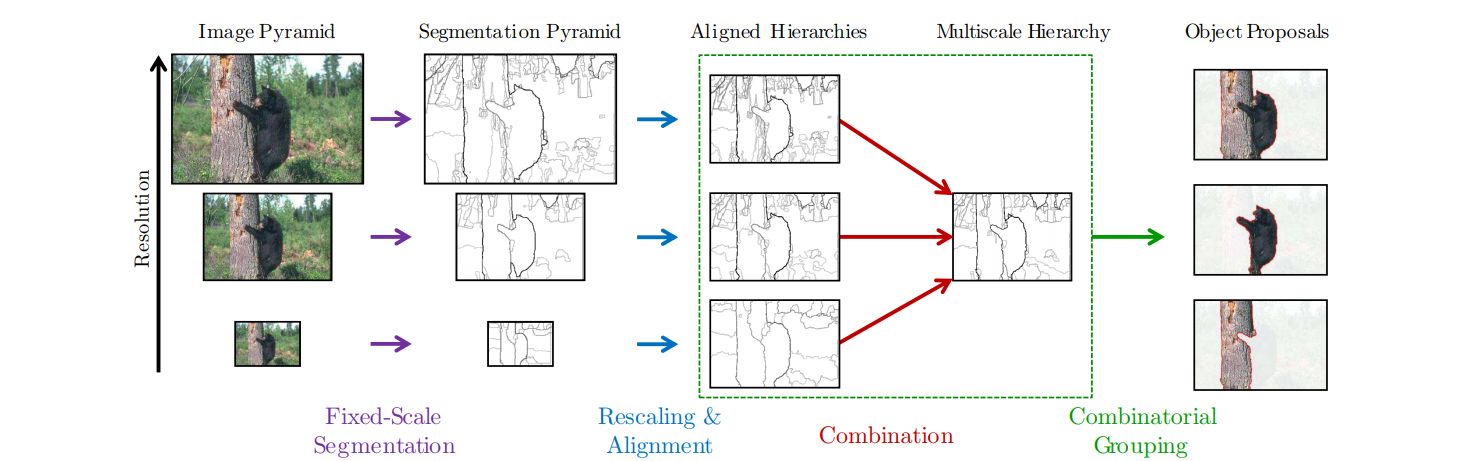
- Previous Proposal-based instance segmentation methods extract class-agnostic proposals which are classified as an instance of a certain semantic class in order to obtain pixel-level instance masks.
- This paper proposes a high-performance hierarchical segmenter that makes effective use of multiscale information.
- Propose a grouping strategy that combines multiscale regions into highly-accurate object candidates by exploring efficiently their combinatorial space
- The Region proposal method proposed in this paper can be directly used as instance segments.
- Demonstrate performance on BSDS500, VOC12 datasets.
| Semantic Instance Segmentation Methods | |||
|
CVPR 2017
Arnab2017CVPR | |||
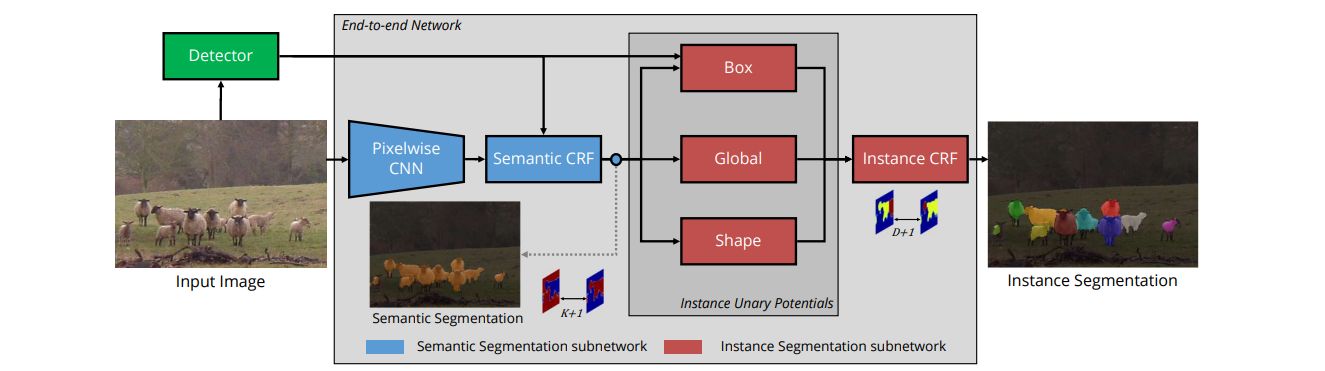
- Propose an Instance Segmentation system that produces a segmentation map where each pixel is assigned an object class and instance identity label.
- Most previous approaches adapt object detectors to produce segments instead of boxes.
- In contrast, their method is based on an initial semantic segmentation module, which feeds into an instance subnetwork.
- This subnetwork uses the initial category-level segmentation, along with cues from the output of an object detector, within an end-to-end CRF to predict instances.
- The end-to-end approach requires no post-processing and considers the image holistically, instead of processing independent proposals.
- Therefore, unlike some previous work, a pixel cannot belong to multiple instances.
- Demonstrate performance on cityscapes, PASCAL VOC and Semantic Boundaries Dataset (SBD) datasets.
| Semantic Segmentation Methods | |||
|
ICCVWORK 2007
Badino2007ICCVWORK | |||
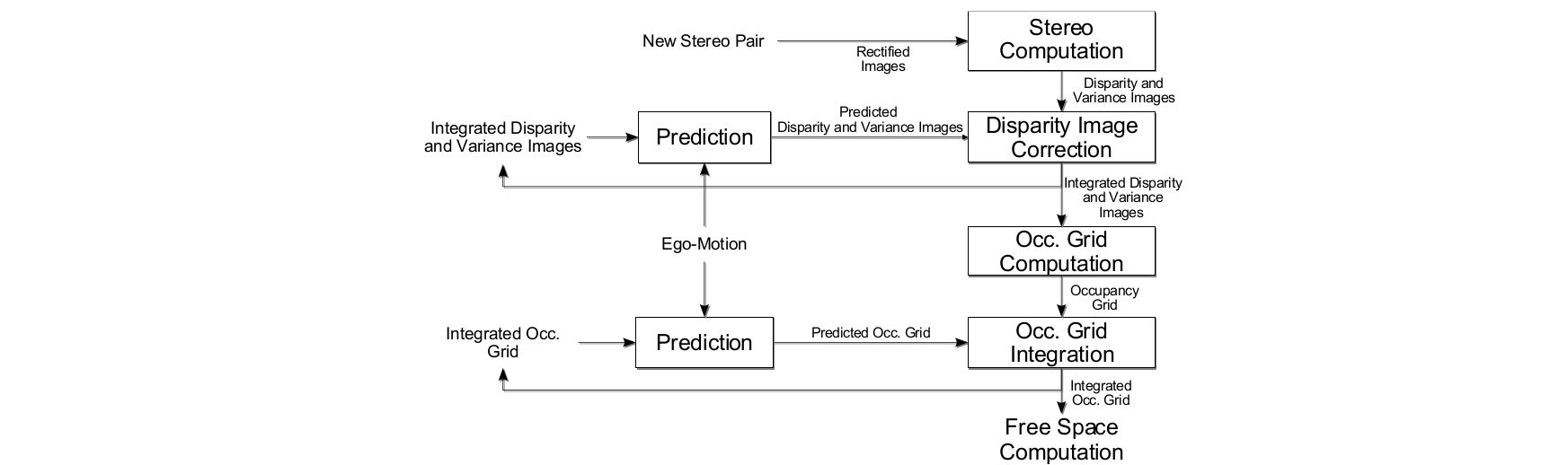
- The free space is the world regions where navigation without collision is guaranteed
- Contributions:
- Presents a method for the computation of free space with stochastic occupancy grids
- Stereo measurements are integrated over time reducing disparity uncertainty.
- These integrated measurements are entered into an occupancy grid, taking into account the noise properties of the measurements
- Defines three types of grids and discusses their benefits and drawbacks
- Applies dynamic programming to a polar occupancy grid, to find the optimal segmentation between free and occupied regions
- Evaluates on stereo sequences introduced in the paper
| Semantic Segmentation Methods | |||
|
DAGM 2009
Badino2009DAGM | |||
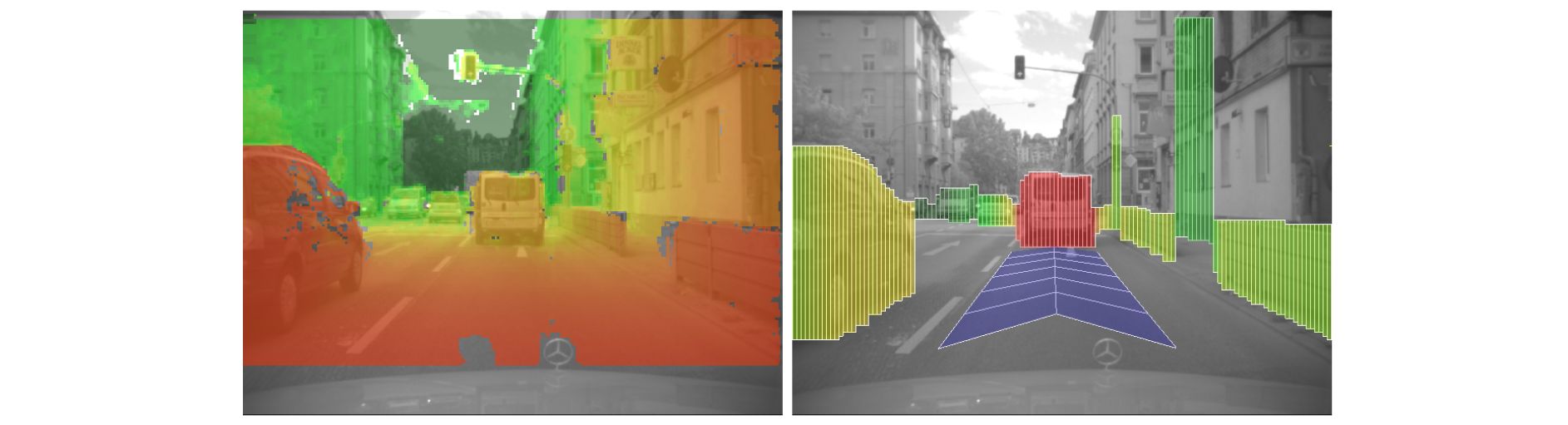
- Motivation: Develop a compact, flexible representation of the 3D traffic situation that can be used for the scene understanding tasks of driver assistance and autonomous systems
- Contributions:
- Introduces a new primitive, a set of rectangular sticks called stixel for modeling 3D scenes
- Each stixel is defined by its 3D position relative to the camera and stands vertically on the ground, having a certain height
- Each stixel limits the free space and approximates the object boundaries
- Stochastic occupancy grids are computed from dense stereo information
- Free space is computed from a polar representation of the occupancy grid
- The height of the stixels is obtained by segmenting the disparity image in foreground and background disparities
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
ICRA 2012
Badino2012ICRA | |||

- Autonomous vehicles must be capable of localizing in GPS denied situations
- Topometric localization which combines topological with metric localization
- Build compact database of simple visual and 3D features with GPS equipped vehicle
- Whole image SURF descriptor, a vector containing gradient information of entire image
- Range mean and standard deviation descriptor
- Localization using a Bayesian filter to match visual and range measurements to the database
- Algorithm is reliable across wide environmental change, including lighting difference, seasonal variations
- Evaluation using a vehicle with mounted video cameras and LIDAR
- Achieving an average localization accuracy of 1 m on an 8 km route
| Mapping, Localization & Ego-Motion Estimation Datasets | |||
|
ICRA 2012
Badino2012ICRA | |||
- Autonomous vehicles must be capable of localizing in GPS denied situations
- Topometric localization which combines topological with metric localization
- Build compact database of simple visual and 3D features with GPS equipped vehicle
- Whole image SURF descriptor, a vector containing gradient information of entire image
- Range mean and standard deviation descriptor
- Localization using a Bayesian filter to match visual and range measurements to the database
- Algorithm is reliable across wide environmental change, including lighting difference, seasonal variations
- Evaluation using a vehicle with mounted video cameras and LIDAR
- Achieving an average localization accuracy of 1 m on an 8 km route
| Semantic Segmentation Methods | |||
|
IJCV 2014
Badrinarayanan2014IJCV | |||
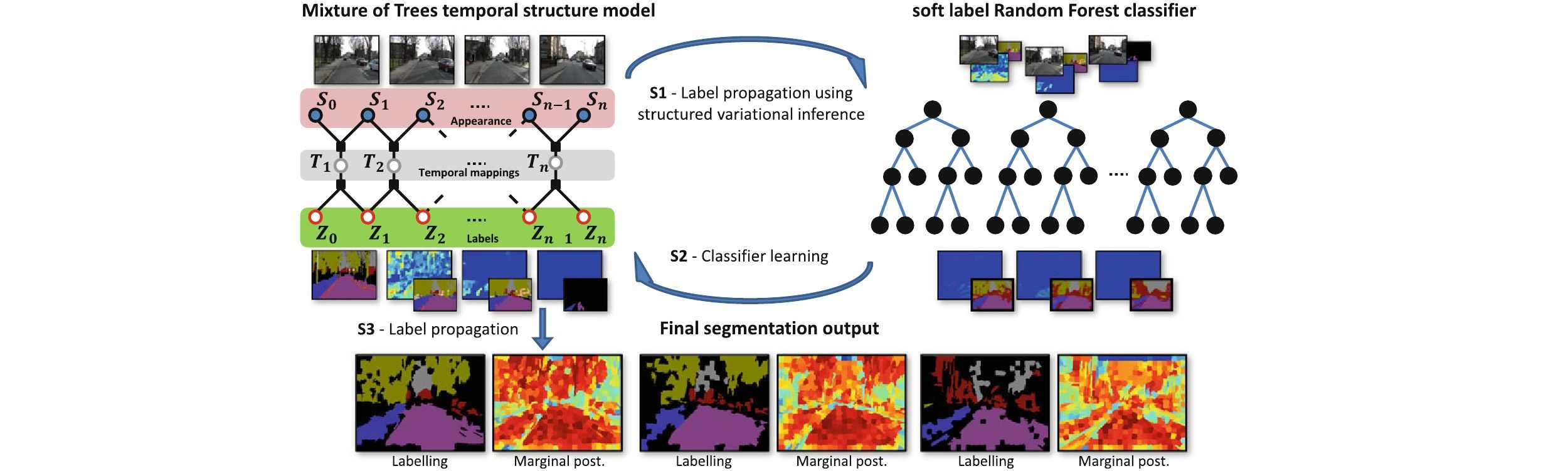
- Mixture of trees probabilistic graphical model for semi-supervised video segmentation
- Each component represents a tree structured temporal linkage between super-pixels from first to last frame
- Variational inference scheme for this model to estimate super-pixel labels and the confidence
- Structured variational inference without unaries to estimate super-pixel marginal posteriors
- Training a soft label Random Forest classifier with pixel marginal posteriors
- Predictions are injected back as unaries in the second iteration of label inference
- Inference over full video volume which helps to avoid erroneous label propagation
- Very efficient in term of computational speed and memory usage and can be used in real time
- Evaluation using the challenging SegTrack dataset (binary segmentation), CamVid driving video dataset(multi-class segmentation)
| Semantic Segmentation Methods | |||
|
CVPR 2010
Badrinarayanan2010CVPR | |||

- Labelling of video sequences is expensive
- Hidden Markov Model for label propagation in video sequences
- Using a limited amount of hand labelled pixels
- Optic Flow based, image patches based, semantic regions based label propagation
- Short sequences naive optic flow based propagation is sufficient otherwise more sophisticated models necessary
- Evaluation by training Random forest classifier for video segmentation with ground truth and data from label propagation
| Optical Flow Methods | |||
|
ECCV 2016
Bai2016ECCV | |||

- Optical flow for autonomous driving
- Assumptions
- Static background
- Small number of rigidly moving objects
- Foreground/background segmentation using semantic segmentation network in combination with 3D object detection
- Propose a siamese network with product layer that learns flow matching with uncertainty
- Restrict the flow matches to lie on its epipolar line
- Slanted plane model for background flow estimation
- Evaluation on KITTI 2015
| Optical Flow State of the Art on KITTI | |||
|
ECCV 2016
Bai2016ECCV | |||
- Optical flow for autonomous driving
- Assumptions
- Static background
- Small number of rigidly moving objects
- Foreground/background segmentation using semantic segmentation network in combination with 3D object detection
- Propose a siamese network with product layer that learns flow matching with uncertainty
- Restrict the flow matches to lie on its epipolar line
- Slanted plane model for background flow estimation
- Evaluation on KITTI 2015
| Optical Flow Discussion | |||
|
ECCV 2016
Bai2016ECCV | |||
- Optical flow for autonomous driving
- Assumptions
- Static background
- Small number of rigidly moving objects
- Foreground/background segmentation using semantic segmentation network in combination with 3D object detection
- Propose a siamese network with product layer that learns flow matching with uncertainty
- Restrict the flow matches to lie on its epipolar line
- Slanted plane model for background flow estimation
- Evaluation on KITTI 2015
| Datasets & Benchmarks | |||
|
IJCV 2011
Baker2011IJCV | |||
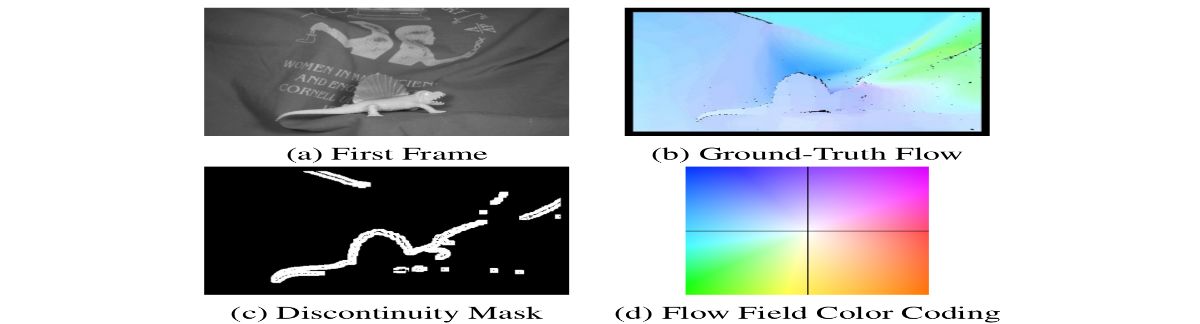
- Presents a collection of datasets for the evaluation of optical flow algorithms
- Contributes four types of data to test different aspects of optical flow algorithms:
- Sequences with nonrigid motion where the ground-truth flow is determined by tracking hidden fluorescent texture
- Realistic synthetic sequences - addresses the limitations of previous dataset sequences by rendering more complex scenes with significant motion discontinuities and textureless regions
- High frame-rate video used to study interpolation error
- Modified stereo sequences of static scenes for optical flow
- Evaluates a number of well-known flow algorithms to characterize the current state of the art
- Extendes the set of evaluation measures and improved the evaluation methodology
| Datasets & Benchmarks Computer Vision Datasets | |||
|
IJCV 2011
Baker2011IJCV | |||
- Presents a collection of datasets for the evaluation of optical flow algorithms
- Contributes four types of data to test different aspects of optical flow algorithms:
- Sequences with nonrigid motion where the ground-truth flow is determined by tracking hidden fluorescent texture
- Realistic synthetic sequences - addresses the limitations of previous dataset sequences by rendering more complex scenes with significant motion discontinuities and textureless regions
- High frame-rate video used to study interpolation error
- Modified stereo sequences of static scenes for optical flow
- Evaluates a number of well-known flow algorithms to characterize the current state of the art
- Extendes the set of evaluation measures and improved the evaluation methodology
| Optical Flow Problem Definition | |||
|
IJCV 2011
Baker2011IJCV | |||
- Presents a collection of datasets for the evaluation of optical flow algorithms
- Contributes four types of data to test different aspects of optical flow algorithms:
- Sequences with nonrigid motion where the ground-truth flow is determined by tracking hidden fluorescent texture
- Realistic synthetic sequences - addresses the limitations of previous dataset sequences by rendering more complex scenes with significant motion discontinuities and textureless regions
- High frame-rate video used to study interpolation error
- Modified stereo sequences of static scenes for optical flow
- Evaluates a number of well-known flow algorithms to characterize the current state of the art
- Extendes the set of evaluation measures and improved the evaluation methodology
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
ICM 2011
Bansal2011ICM | |||
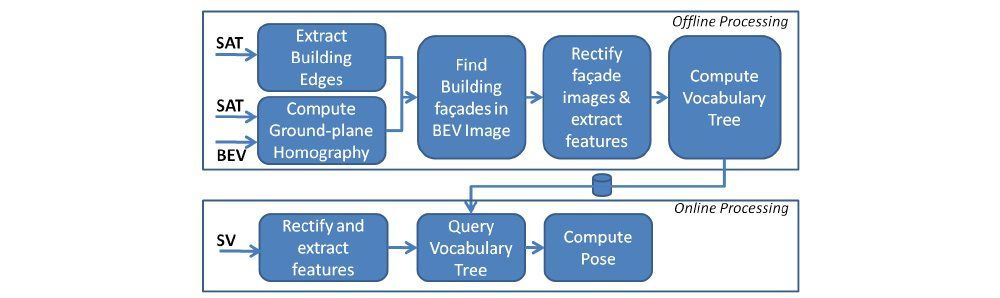
- Aerial image databases are widely available while image from the ground of urban areas is limited
- Localization of ground level images in urban areas using a database of satellite and oblique aerial images
- Method for estimating building facades by extracting line segments from satellite and aerial images
- Correspondence of building facades between aerial and ground images using statistical self-similarity with respect to other patches on a facade
- Position and orientation estimation of ground images
- Qualitative results on a region around Ridieu St. in Ottawa, Canada with BEV, Panoramio imagery and Google Street-view screen-shots
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
CVPR 2013
Bao2013CVPR | |||
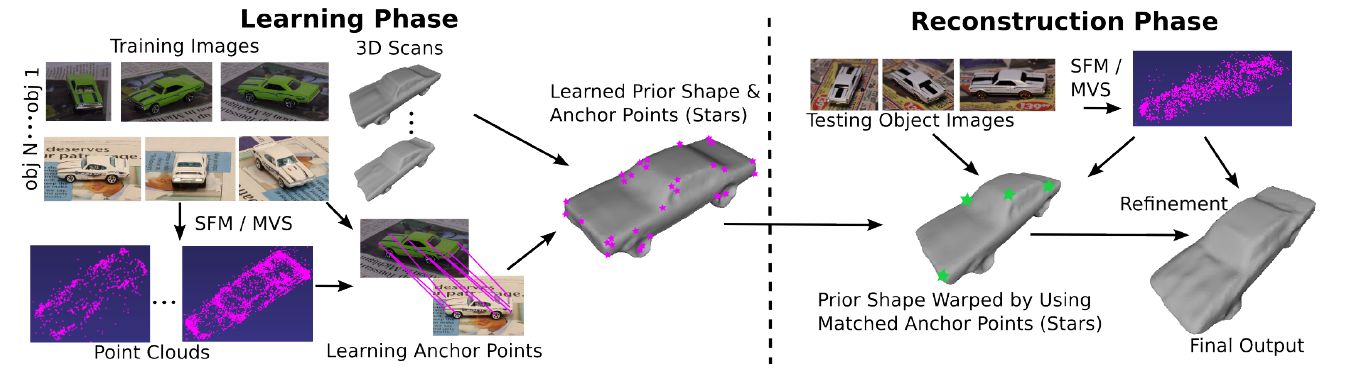
- Dense reconstruction incorporating semantic information to overcome drawbacks of traditional multiview stereo
- Learning a prior comprised of a mean shape and a set of weighted anchor points
- Training from of 3D scans and images of objects from various viewpoints
- Robust algorithm to match anchor points across instances enables learning a mean shape for the category
- Shape of an object modelled as warped version of the category mean with instance-specific details
- Qualitative and quantitative results on a small dataset of model cars using leave-one-out
| Object Detection Methods | |||
|
CVPR 2012
Benenson2012CVPR | |||
- Fast and high quality pedestrian detection
- Two new algorithmic speed-ups:
- Exploiting geometric context extracted from stereo images
- Efficiently handling different scales
- Object detection without image resizing using stixels
- Similar to Viola and Jones: scale the features not the images, applied to HOG-like features
- Detections at 50 fps (135 fps on CPU+GPU)
- Evaluated on INRIA Persons and Bahnhof sequence
| Object Detection Methods | |||
|
ECCV 2014
Benenson2014ECCV | |||
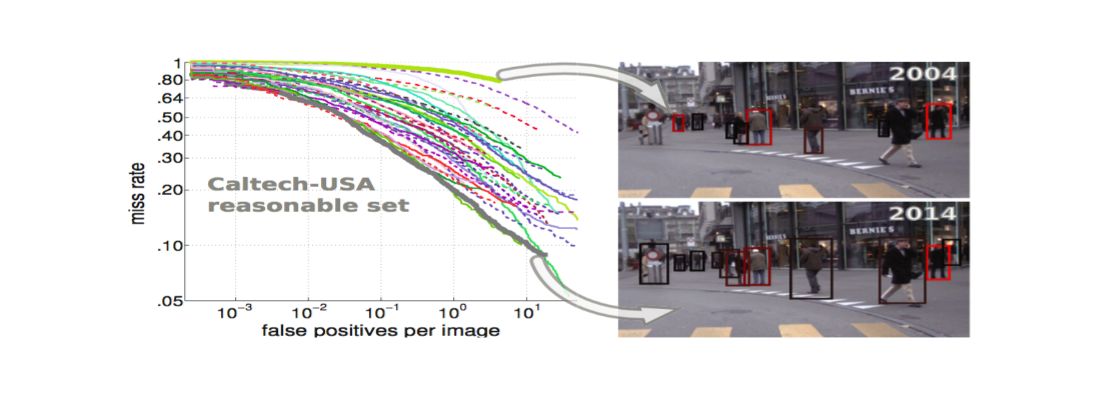
- Aim is to review progress over the last decade of pedestrian detection, & try to quantify which ideas had the most impact on final detection quality
- Evaluates on Caltech-USA, INRIA and KITTI datasets for comparing methods
- Conclusions:
- There is no conclusive empirical evidence indicating that whether non-linear kernels provide meaningful gains over linear kernel
- The 3 families of pedestrian detectors (DPMs, decision forests, deep networks) are based on different learning techniques, their results are surprisingly close
- Multi-scale models provide a simple and generic extension to existing detectors. Despite consistent improvements, their contribution to the final quality is minor
- Most of the progress can be attributed to the improvement in features alone
- Combining the detector ingredients found to work well (better features, optical flow, and context) shows that these ingredients are mostly complementary
| Object Detection Datasets | |||
|
ECCV 2014
Benenson2014ECCV | |||
- Aim is to review progress over the last decade of pedestrian detection, & try to quantify which ideas had the most impact on final detection quality
- Evaluates on Caltech-USA, INRIA and KITTI datasets for comparing methods
- Conclusions:
- There is no conclusive empirical evidence indicating that whether non-linear kernels provide meaningful gains over linear kernel
- The 3 families of pedestrian detectors (DPMs, decision forests, deep networks) are based on different learning techniques, their results are surprisingly close
- Multi-scale models provide a simple and generic extension to existing detectors. Despite consistent improvements, their contribution to the final quality is minor
- Most of the progress can be attributed to the improvement in features alone
- Combining the detector ingredients found to work well (better features, optical flow, and context) shows that these ingredients are mostly complementary
| History of Autonomous Driving | |||
|
IV 2011
Bertozzi2011IV | |||

- Presents the details and preliminary results of VIAC, the VisLab Intercontinental Autonomous Challenge, a test of autonomous driving along an unknown route from Italy to China
- The onboard perception systems can detect obstacles, lane markings, ditches, berms and indentify the presence and position of a preceding vehicle
- The information on the environment produced by the sensing suite is used to perform different tasks, such as leader-following, stop & go, and waypoint following
- All data have been logged, including all data generated by the sensors, vehicle data, and GPS info
- This data is available for a deep analysis of the various systems performance, with the aim of virtually running the whole trip multiple times with improved versions of the software
- This paper discusses some preliminary results and figures obtained by the analysis of the data collected during the test
| History of Autonomous Driving | |||
|
RAS 2000
Bertozzi2000RAS | |||
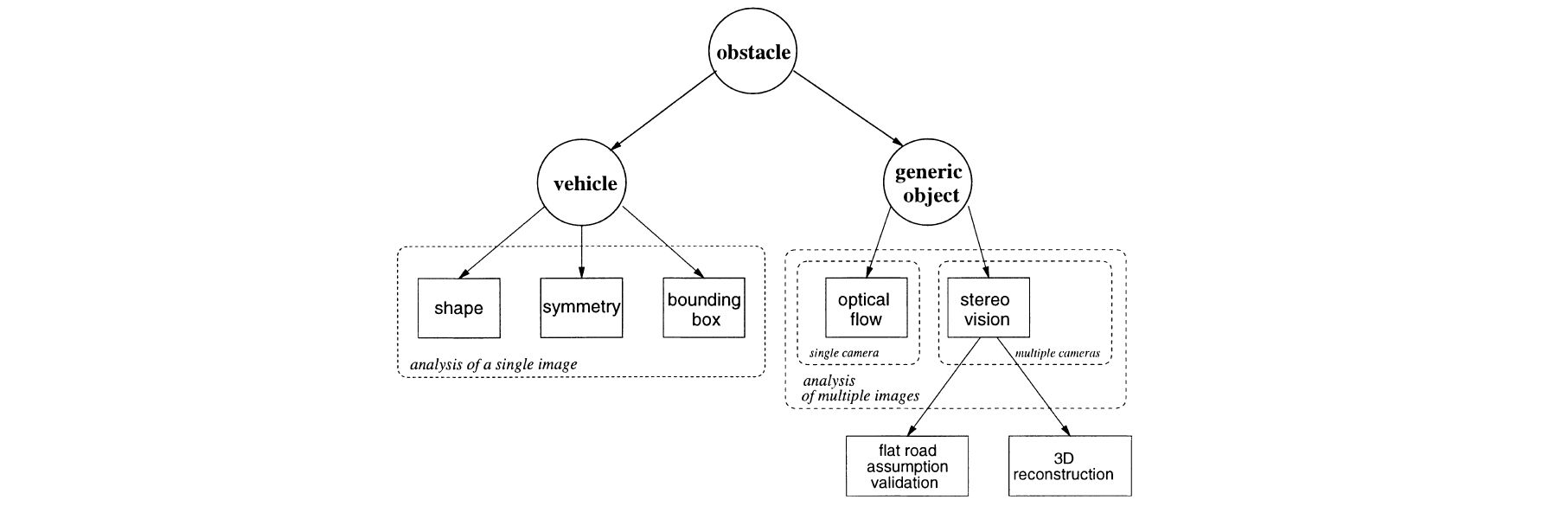
- Survey on the most common approaches to the challenging task of Autonomous Road Following
- Computing power not a problem any more
- Data acquisition still problematic with difficulties like light reflections, wet road, direct sunshine, tunnels, shadows.
- Enhancement of sensor's capabilities and performance need to be addressed
- Full automation of traffic is technically feasible
- Legal aspects related to the responsibility and the impact of automatic driving on human passengers need to be carefully considered
- Automation will be restricted to special infrastructure for now and will be gradually extended to other key transportations areas as shipping
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
ECCV 2002
Bhotika2002ECCV | |||
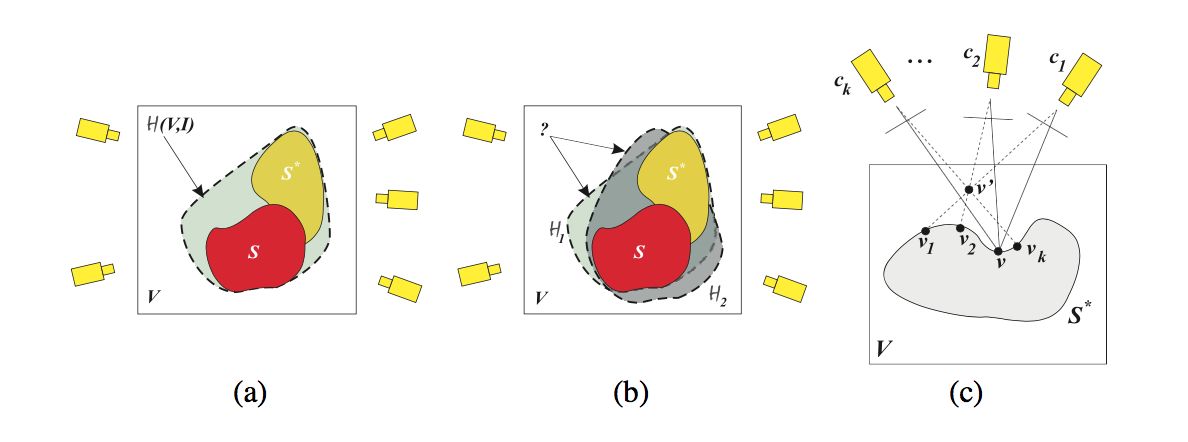
- Probabilistic 3D shape reconstruction based on mathematical definitions of visibility, occupancy, emptiness, and photo-consistency
- Understanding stereo ambiguities
- Probabilistic treatment of visibility
- Algorithm-independent analysis of occupancy
- Handling sensor and model errors
- Explicit distinction between shape ambiguity (multiple reconstruction solutions given noiseless images) and uncertainty (due to noise and modeling errors)
- {it Photo Hull Distribution}: all photo-consistent shapes with a probability
- A stochastic algorithm to draw samples from the Photo Hull Distribution with convergence properties
| Optical Flow Methods | |||
|
ICCV 1993
Black1993ICCV | |||
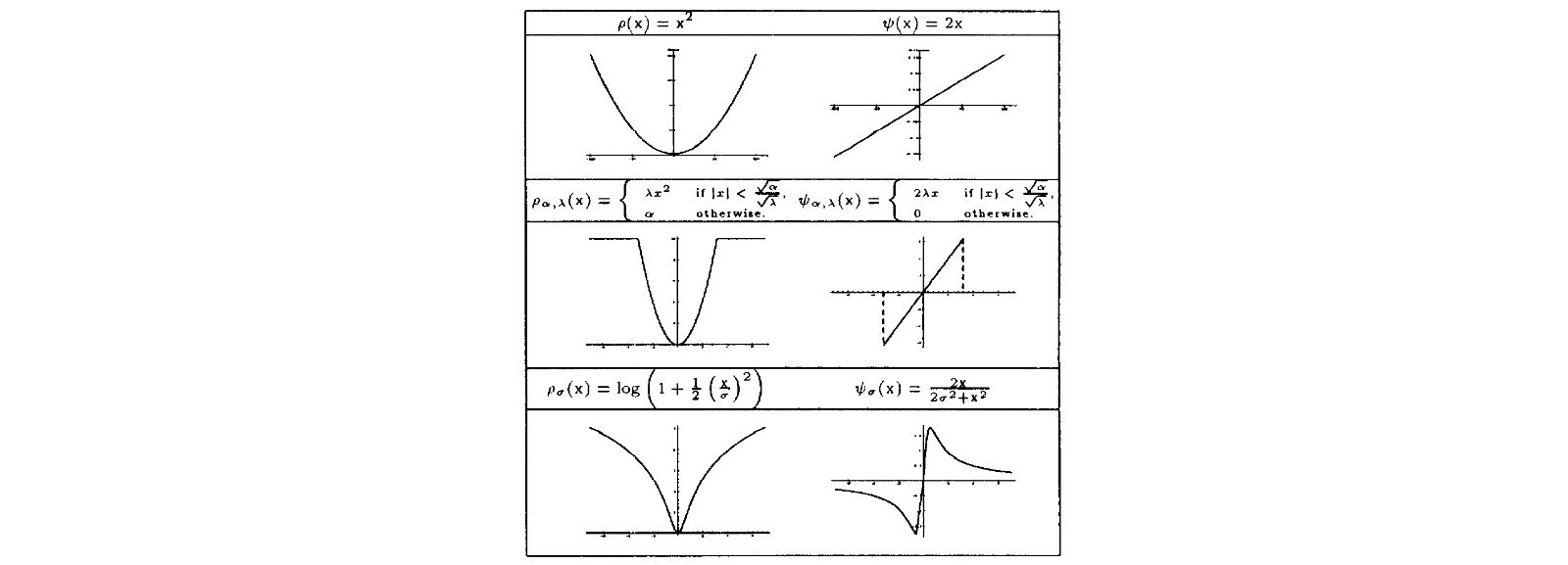
- Pioneering work in optical flow computation
- Addresses violations of the brightness constancy in Optical Flow formulation
- Proposes a new framework based on robust estimation
- Show relationship between robust estimation and line process approaches to deal with spatial discontinuities
- Generalize the notion of a line process to that of an outlier process
- Develop Graduated Non-Convexity algorithm for recovering optical flow and motion discontinuances
- Demonstrate the robust formulation on synthetic data and natural images
| Optical Flow Discussion | |||
|
ICCV 1993
Black1993ICCV | |||
- Pioneering work in optical flow computation
- Addresses violations of the brightness constancy in Optical Flow formulation
- Proposes a new framework based on robust estimation
- Show relationship between robust estimation and line process approaches to deal with spatial discontinuities
- Generalize the notion of a line process to that of an outlier process
- Develop Graduated Non-Convexity algorithm for recovering optical flow and motion discontinuances
- Demonstrate the robust formulation on synthetic data and natural images
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
CVPR 2016
Blaha2016CVPR | |||
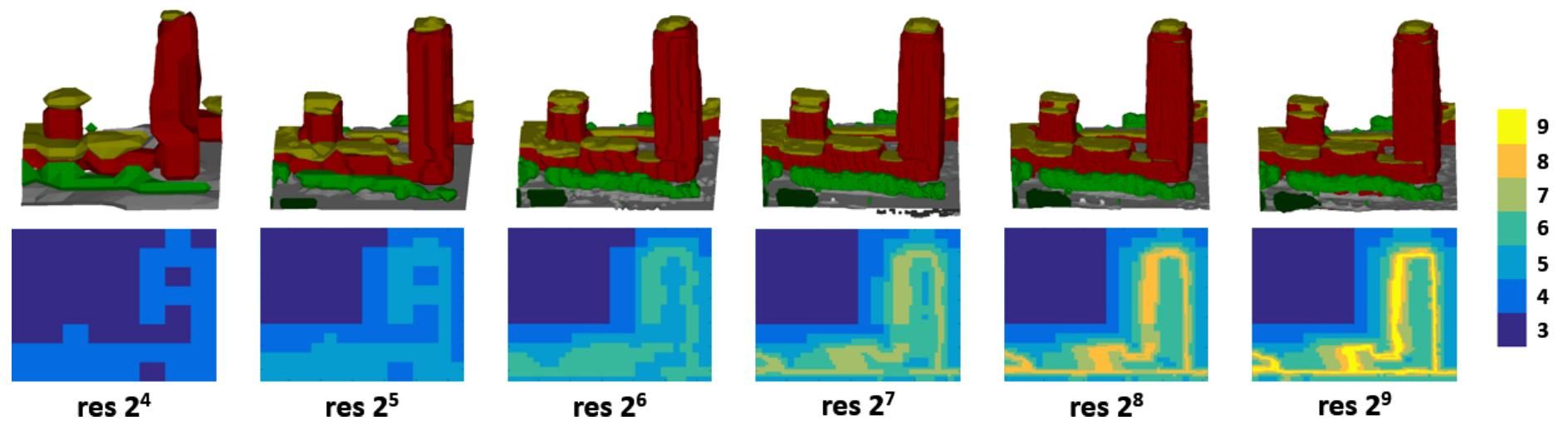
- Joint formulation of semantic segmentation and 3D reconstruction enables to use class-specific shape priors
- State-of-the-art could not scale to large scenes because of run time and memory
- Extension of an expensive volumetric approach
- Hierarchical scheme using an Octree structure
- Refines only in regions containing surfaces
- Coarse-to-fine converges faster because of improved initial guesses
- Saves 95 computation time and 98 memory usage
- Evaluation on real world data set from the city of Enschede
| Object Detection Methods | |||
|
ECCV 2016
Bogo2016ECCV | |||
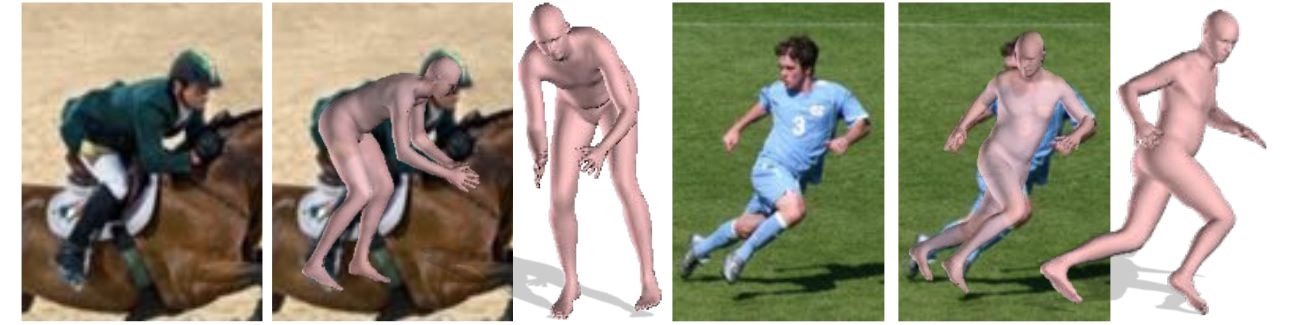
- Describes the first method to automatically estimate the 3D pose of the human body as well as its 3D shape from a single unconstrained image
- Estimates a full 3D mesh and shows that 2D joints alone carry a surprising amount of information about body shape
- First uses a CNN-based method, DeepCut, to predict the 2D body joint locations
- Then fits a body shape model, called SMPL, to the 2D joints by minimizing an objective function that penalizes the error between the projected 3D model joints and detected 2D joints
- Because SMPL captures correlations in human shape across the population, robust fitting is possible with very little data
- Evaluates on Leeds Sports, HumanEva, and Human3.6M datasets
| History of Autonomous Driving | |||
|
ARXIV 2016
Bojarski2016ARXIV | |||
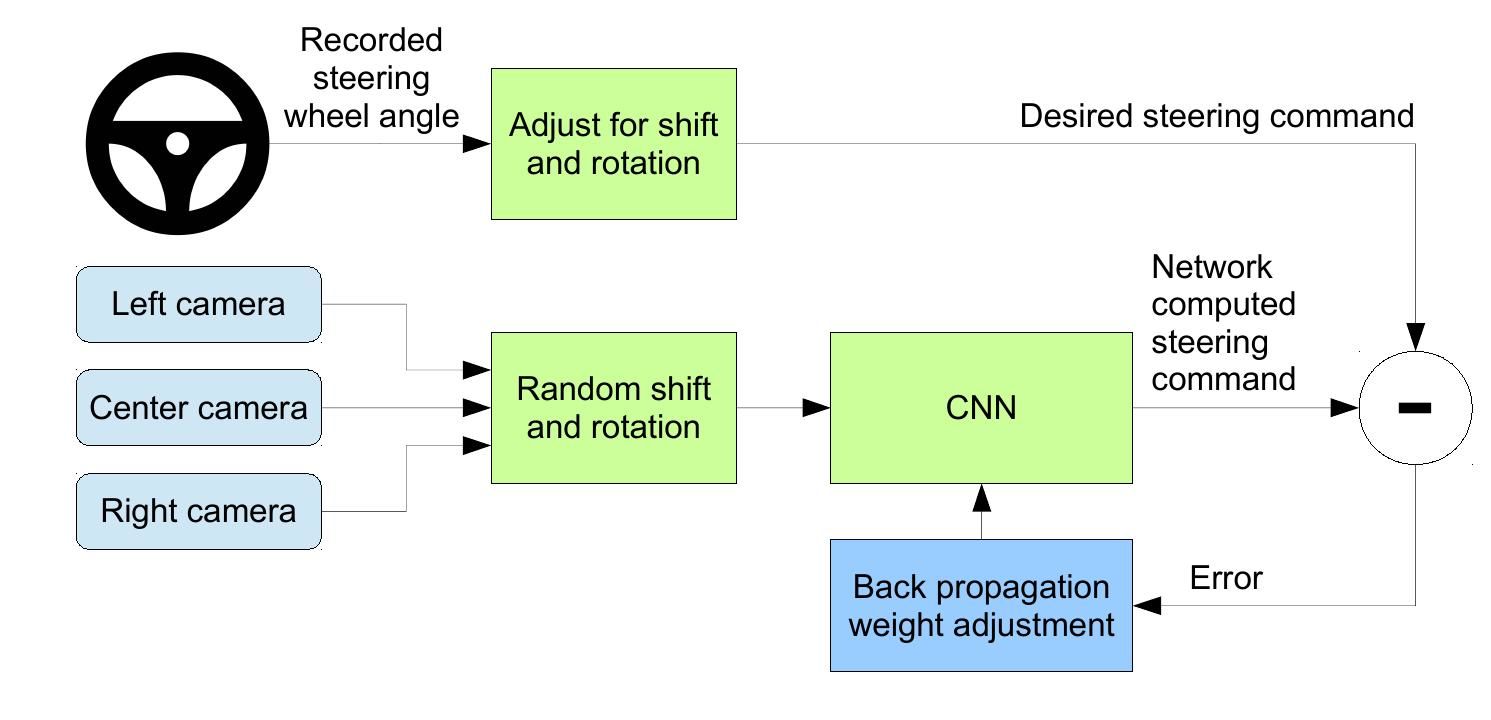
- Convolutional Neural Network that learns vehicle control using images
- Left and right images are used for data augmentation to simulate specific off-center shifts while adapting the steering command
- Approximated viewpoint transformations assuming points below horizon lie on a plane and above are infinitely far away
- The final network outputs steering commands for the center camera only
- Tested with simulations and with the NVIDIA DRIVE PX self-driving car
| End-to-End Learning for Autonomous Driving Methods | |||
|
ARXIV 2016
Bojarski2016ARXIV | |||
- Convolutional Neural Network that learns vehicle control using images
- Left and right images are used for data augmentation to simulate specific off-center shifts while adapting the steering command
- Approximated viewpoint transformations assuming points below horizon lie on a plane and above are infinitely far away
- The final network outputs steering commands for the center camera only
- Tested with simulations and with the NVIDIA DRIVE PX self-driving car
| History of Autonomous Driving | |||
|
JFR 2006
Braid2006JFR | |||

- TerraMax is an autonomous vehicle based on Koshkosh Truck's Medium Tactical Vehicle Replacement Truck platform
- One of the five vehicles able to successfully pass the 132 miles DARPA Grand Challenge desert race
- Detailed description of the Intelligent Vehicle Management System which includes vehicle sensor management, navigation, and vehicle control system
- Informations on path planer, obstacle detection and behavior management
- Vehicle's vision system was provided by University of Parma
- Oshkosh Truck Corp. provided project management, system integration, low level controls hardware, modeling and simulation support and the vehicle
| Stereo Methods | |||
|
JIS 2010
Bredies2010JIS | |||
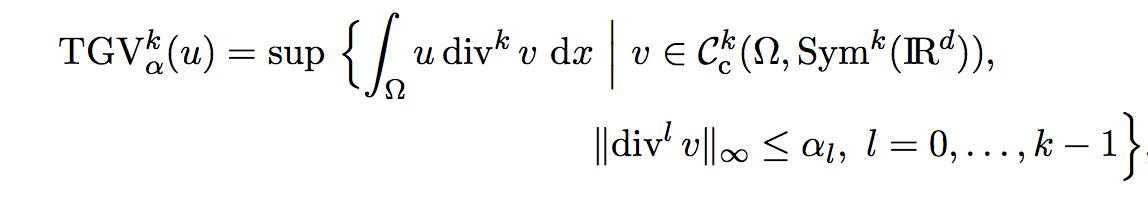
- The concept of Total Generalized Variation (TGV) as a regularization term
- Motivation: problems with the
- norm-of-squares terms due to outliers
- bounded variation semi-norm due to piece-wise constant modeling (stair-casing effect)
- Essential properties of TGV:
- generalized higher-order derivatives of the function
- shared properties with TV, for example rotational invariance but different for functions which are not piece-wise constant
- convexity and weak lower semi-continuity
- Experiments on denoising problem
- Regularization on different regularity levels without stair-casing effect
| Optical Flow Methods | |||
|
JIS 2010
Bredies2010JIS | |||
- The concept of Total Generalized Variation (TGV) as a regularization term
- Motivation: problems with the
- norm-of-squares terms due to outliers
- bounded variation semi-norm due to piece-wise constant modeling (stair-casing effect)
- Essential properties of TGV:
- generalized higher-order derivatives of the function
- shared properties with TV, for example rotational invariance but different for functions which are not piece-wise constant
- convexity and weak lower semi-continuity
- Experiments on denoising problem
- Regularization on different regularity levels without stair-casing effect
| Object Detection Methods | |||
|
IV 2000
Broggi2000IV | |||
- Detecting pedestrians on an experimental autonomous vehicle (the ARGO project)
- Exploiting morphological characteristics (size, ratio, and shape) and vertical symmetry of human shape
- A first coarse detection from a monocular image
- Distance refinement using a stereo vision technique
- Temporal correlation using the results from the previous frame to correct and validate the current ones
- Integrated in the ARGO vehicle and tested in urban environments
- Successful detections of whole pedestrians present in the image at a distance ranging from 10 to 40 meters
| History of Autonomous Driving | |||
|
TITS 2015
Broggi2015TITS | |||
- An autonomous driving test on urban roads and freeways open to regular traffic
- Moving in a mapped and familiar scenario with the addition of the position of pedestrian crossings, traffic lights, and guard rails
- Real-time perception of the world for static and dynamic obstacles
- No need for precise 3D maps or world reconstruction
- Details about the vehicle, and main layers: perception, planning, and control
- Complex driving scenarios including roundabouts, junctions, pedestrian crossings, freeway junctions, and traffic lights
| Optical Flow Methods | |||
|
PAMI 2011
Brox2011PAMI | |||
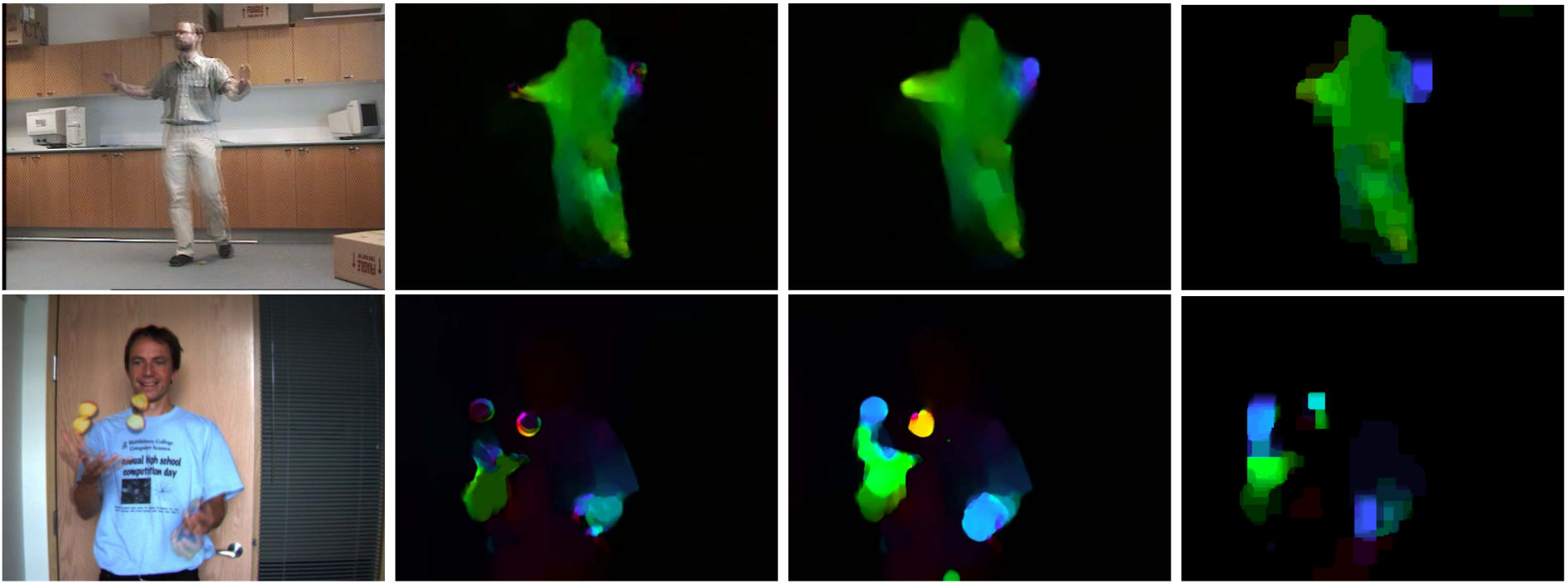
- Coarse-to-fine warping for optical flow estimation
- can handle large displacements
- small objects moving fast are problematic
- Integration of rich descriptors into a variational formulation
- Simple nearest neighbor search in coarse grid
- Feature matches used as soft constraint in continuous approach
- Continuation method: coarse-to-fine while reducing the importance of descriptor matches
- Quantitative results only on Middlebury but real world qualitative results
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
PAMI 2016
Brubaker2016PAMI | |||
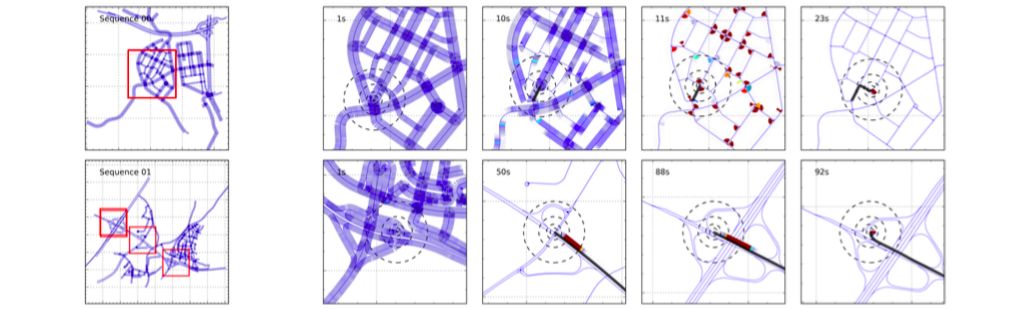
- Describes an affordable solution to vehicle self-localization which uses odometry computed from two video cameras & road maps as the sole inputs
- Contributions:
- Proposes a probabilistic model for which an efficient approximate inference algorithm is derived
- The inference algorithm is able to utilize distributed computation in order to meet the real-time requirements of autonomous systems
- Exploits freely available maps & visual odometry measurements, and is able to localize a vehicle to 4m on average after 52 seconds of driving
- Evaluates on KITTI visual odometry dataset
| Optical Flow Methods | |||
|
GPID 2006
Bruhn2006GPID | |||
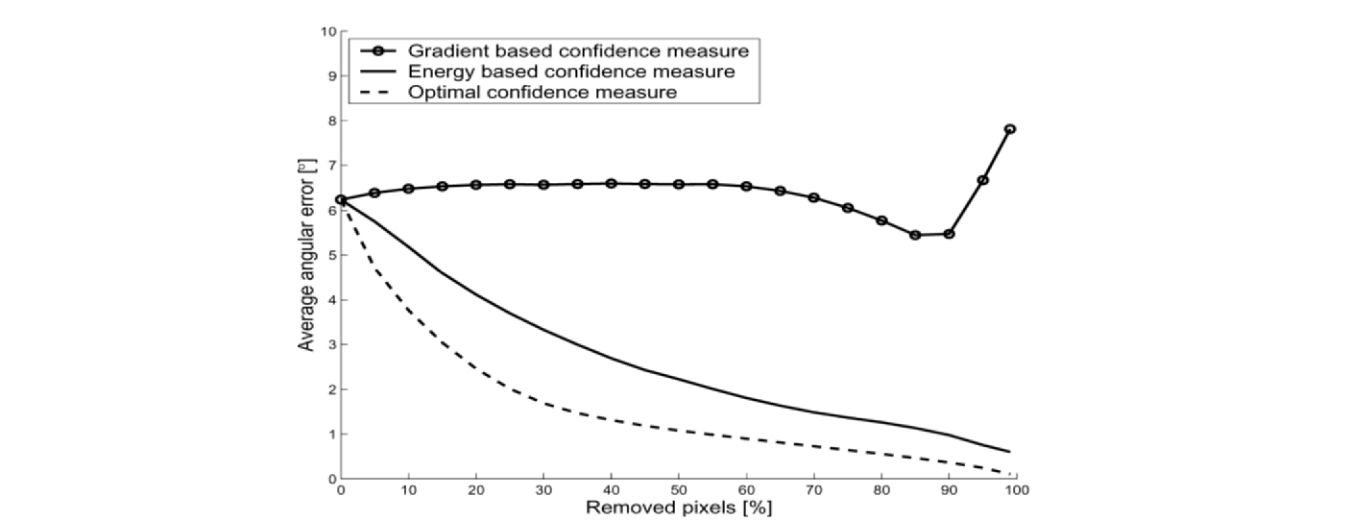
- Investigation of confidence measures for variational optic flow computation
- Discussion of frequently used sparsification strategy based on the image gradient
- Propose a novel energy-based confidence measure that is parameter-free
- Applicable to the entire class of energy minimizing optical flow approaches
- Energy-based confidence measure leads to better results than the gradient-based approach
- Validation on Yosemite, Marble and Office
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
ITSC 2016
Buczko2016ITSC | |||
- Frame-to-frame feature-based ego-motion estimation using stereo cameras
- Current approach: Rotation and translation of the ego-motion in two separate processes
- An analysis of the characteristics of the optical flows and reprojection errors that are independently induced by each of the decoupled six degrees of freedom motion
- A reprojection error that depends on the coordinates of the features
- Decoupling the translation flow from the overall flow
- Using an initial rotation estimate
- Transforming the correspondences into a pure translation scenario
- Evaluated on KITTI, the best translation error of all camera-based methods
| Semantic Segmentation Methods | |||
|
BMVC 2010
Budvytis2010BMVC | |||
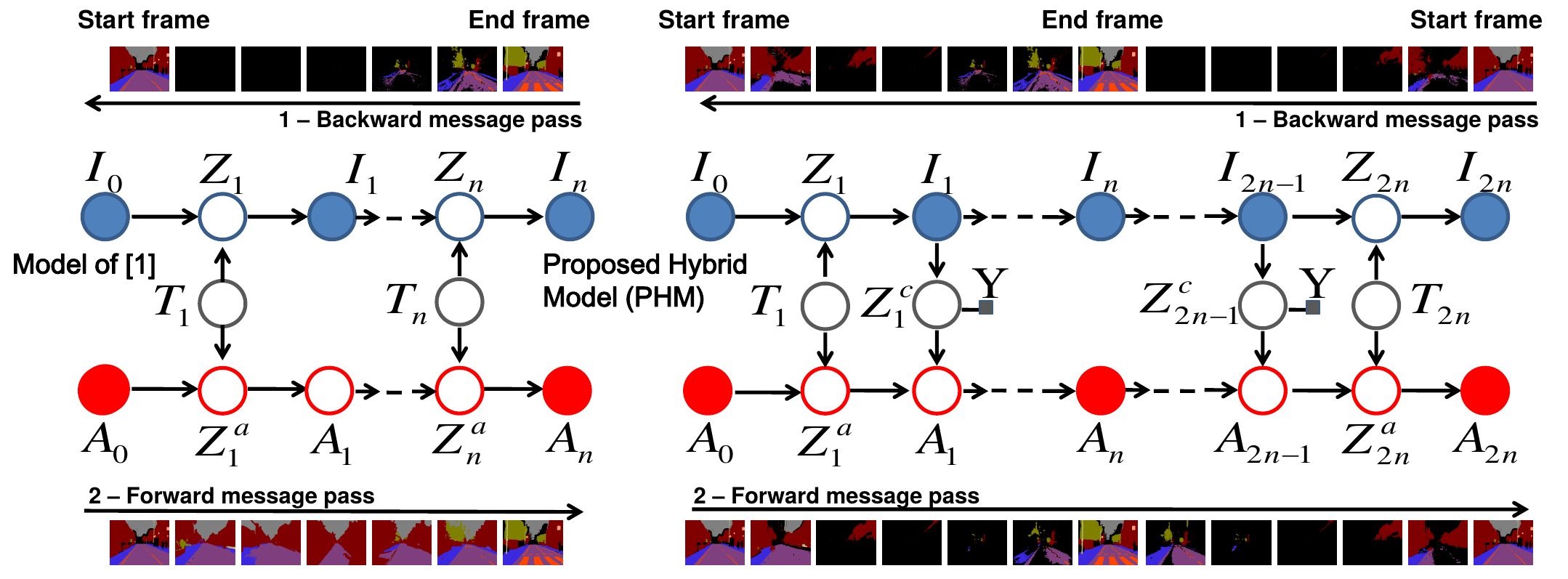
- Directed graphical model for label propagation in long and complex video sequences
- Given hand-labelled (semantic labels) start and end frames of a video sequence
- Hybrid of generative label propagation and discriminative classification
- EM based inference used for initial propagation and training of a multi-class classifier
- Labels estimated by classifier are injected back into Bayesian network for another iteration
- Iterative scheme has the ability to handle occlusions
- Time-symmetric label propagation by appending the time-reversed sequence
- Show advantage of learning from propagated labels
- Quantitative and qualitative results on CamVid
| Datasets & Benchmarks | |||
|
ECCV 2012
Butler2012ECCV | |||

- Introduction of MPI-Sintel, a new data set based on an open source animated film
- Contributions:
- This data set has important features not present in the Middlebury flow evaluation: long sequences, large motions, specular reflections, motion blur, defocus blur, atmospheric effects.
- Analysis of the statistical properties of the data suggesting it is sufficiently representative of natural movies to be useful
- Introduction of new evaluation measures
- Comparison of public-domain flow algorithms
- Evaluation website that maintains the current ranking and analysis of methods
| Datasets & Benchmarks Computer Vision Datasets | |||
|
ECCV 2012
Butler2012ECCV | |||
- Introduction of MPI-Sintel, a new data set based on an open source animated film
- Contributions:
- This data set has important features not present in the Middlebury flow evaluation: long sequences, large motions, specular reflections, motion blur, defocus blur, atmospheric effects.
- Analysis of the statistical properties of the data suggesting it is sufficiently representative of natural movies to be useful
- Introduction of new evaluation measures
- Comparison of public-domain flow algorithms
- Evaluation website that maintains the current ranking and analysis of methods
| Datasets & Benchmarks Synthetic Data Generation using Game Engines | |||
|
ECCV 2012
Butler2012ECCV | |||
- Introduction of MPI-Sintel, a new data set based on an open source animated film
- Contributions:
- This data set has important features not present in the Middlebury flow evaluation: long sequences, large motions, specular reflections, motion blur, defocus blur, atmospheric effects.
- Analysis of the statistical properties of the data suggesting it is sufficiently representative of natural movies to be useful
- Introduction of new evaluation measures
- Comparison of public-domain flow algorithms
- Evaluation website that maintains the current ranking and analysis of methods
| Stereo Datasets | |||
|
ECCV 2012
Butler2012ECCV | |||
- Introduction of MPI-Sintel, a new data set based on an open source animated film
- Contributions:
- This data set has important features not present in the Middlebury flow evaluation: long sequences, large motions, specular reflections, motion blur, defocus blur, atmospheric effects.
- Analysis of the statistical properties of the data suggesting it is sufficiently representative of natural movies to be useful
- Introduction of new evaluation measures
- Comparison of public-domain flow algorithms
- Evaluation website that maintains the current ranking and analysis of methods
| Optical Flow Methods | |||
|
ECCV 2012
Butler2012ECCV | |||
- Introduction of MPI-Sintel, a new data set based on an open source animated film
- Contributions:
- This data set has important features not present in the Middlebury flow evaluation: long sequences, large motions, specular reflections, motion blur, defocus blur, atmospheric effects.
- Analysis of the statistical properties of the data suggesting it is sufficiently representative of natural movies to be useful
- Introduction of new evaluation measures
- Comparison of public-domain flow algorithms
- Evaluation website that maintains the current ranking and analysis of methods
| Optical Flow Datasets | |||
|
ECCV 2012
Butler2012ECCV | |||
- Introduction of MPI-Sintel, a new data set based on an open source animated film
- Contributions:
- This data set has important features not present in the Middlebury flow evaluation: long sequences, large motions, specular reflections, motion blur, defocus blur, atmospheric effects.
- Analysis of the statistical properties of the data suggesting it is sufficiently representative of natural movies to be useful
- Introduction of new evaluation measures
- Comparison of public-domain flow algorithms
- Evaluation website that maintains the current ranking and analysis of methods
| 3D Scene Flow Datasets | |||
|
ECCV 2012
Butler2012ECCV | |||
- Introduction of MPI-Sintel, a new data set based on an open source animated film
- Contributions:
- This data set has important features not present in the Middlebury flow evaluation: long sequences, large motions, specular reflections, motion blur, defocus blur, atmospheric effects.
- Analysis of the statistical properties of the data suggesting it is sufficiently representative of natural movies to be useful
- Introduction of new evaluation measures
- Comparison of public-domain flow algorithms
- Evaluation website that maintains the current ranking and analysis of methods
| Object Detection Methods | |||
|
ECCV 2016
Cai2016ECCV | |||
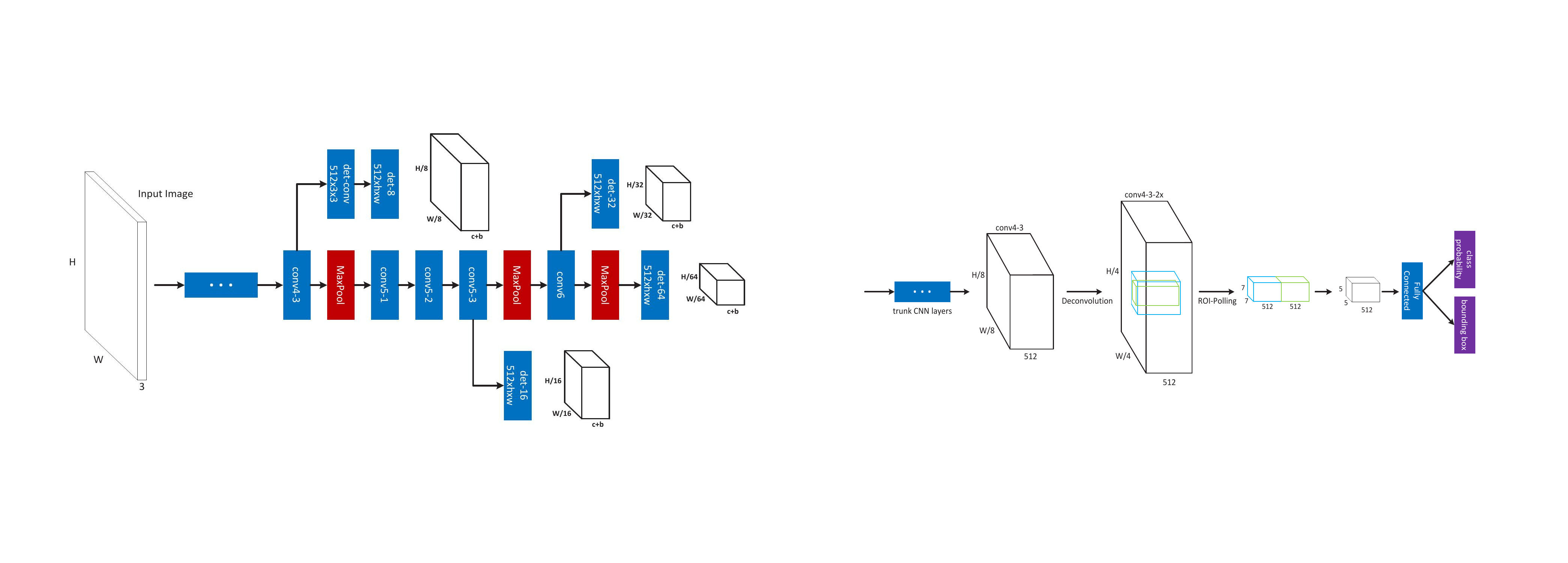
- Multi-scale CNN for fast multi-scale object detection
- Proposal sub-network performs detection at multiple output layers to match objects at different scales
- Complementary scale-specific detectors are combined to produce a strong multi-scale object detector
- Unified network is learned end-to-end by optimizing a multi-task loss
- Feature upsampling by deconvolution reduces the memory and computation costs in contrast to input upsampling
- Evaluation on KITTI and Caltech
| Object Detection State of the Art on KITTI | |||
|
ECCV 2016
Cai2016ECCV | |||
- Multi-scale CNN for fast multi-scale object detection
- Proposal sub-network performs detection at multiple output layers to match objects at different scales
- Complementary scale-specific detectors are combined to produce a strong multi-scale object detector
- Unified network is learned end-to-end by optimizing a multi-task loss
- Feature upsampling by deconvolution reduces the memory and computation costs in contrast to input upsampling
- Evaluation on KITTI and Caltech
| End-to-End Learning for Autonomous Driving Methods | |||
|
ICCV 2015
Chen2015ICCVa | |||
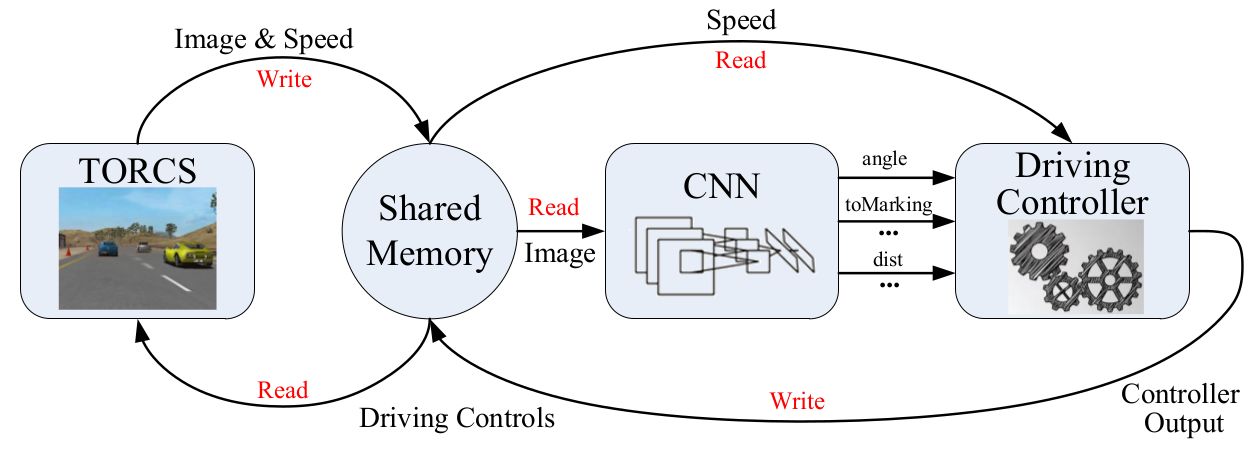
- Existing methods can be categorized into two major paradigms:
- Mediated perception approaches that parse an entire scene to make a driving decision
- Behavior reflex approaches that directly map an input image to a driving action by a regressor
- Contributions:
- Proposes to map input image to a small number of perception indicators
- These indicators directly relate to the affordance of a road/traffic state for driving
- This representation provides a set of compact descriptions of the scene to enable a controller to drive autonomously
| End-to-End Learning for Autonomous Driving Datasets | |||
|
ICCV 2015
Chen2015ICCVa | |||
- Existing methods can be categorized into two major paradigms:
- Mediated perception approaches that parse an entire scene to make a driving decision
- Behavior reflex approaches that directly map an input image to a driving action by a regressor
- Contributions:
- Proposes to map input image to a small number of perception indicators
- These indicators directly relate to the affordance of a road/traffic state for driving
- This representation provides a set of compact descriptions of the scene to enable a controller to drive autonomously
| Semantic Segmentation Methods | |||
|
CVPR 2014
Chen2014CVPRb | |||
- Automatically segmentation of objects given annotated 3D bounding boxes
- Inference in a binary MRF using appearance models, stereo and/or noisy point clouds, 3D CAD models, and topological constraints
- 10 to 20 labeled objects to train the system
- Evaluated using 3D boxes available on KITTI
- 86 IOU score on segmenting cars (performance of MTurkers)
- It can be used to de-noise MTurk annotations.
- Segmenting big cars is easier than smaller ones.
- Each potential increases performance (CAD model most).
- Same performance with stereo or LIDAR (highest using both)
- Fast: 2 min for training and 44 seconds for full test set
- Robust to low-resolution, saturation, noise, sparse point clouds, depth estimation errors and occlusions
| Semantic Segmentation Methods | |||
|
ICLR 2015
Chen2015ICLR | |||
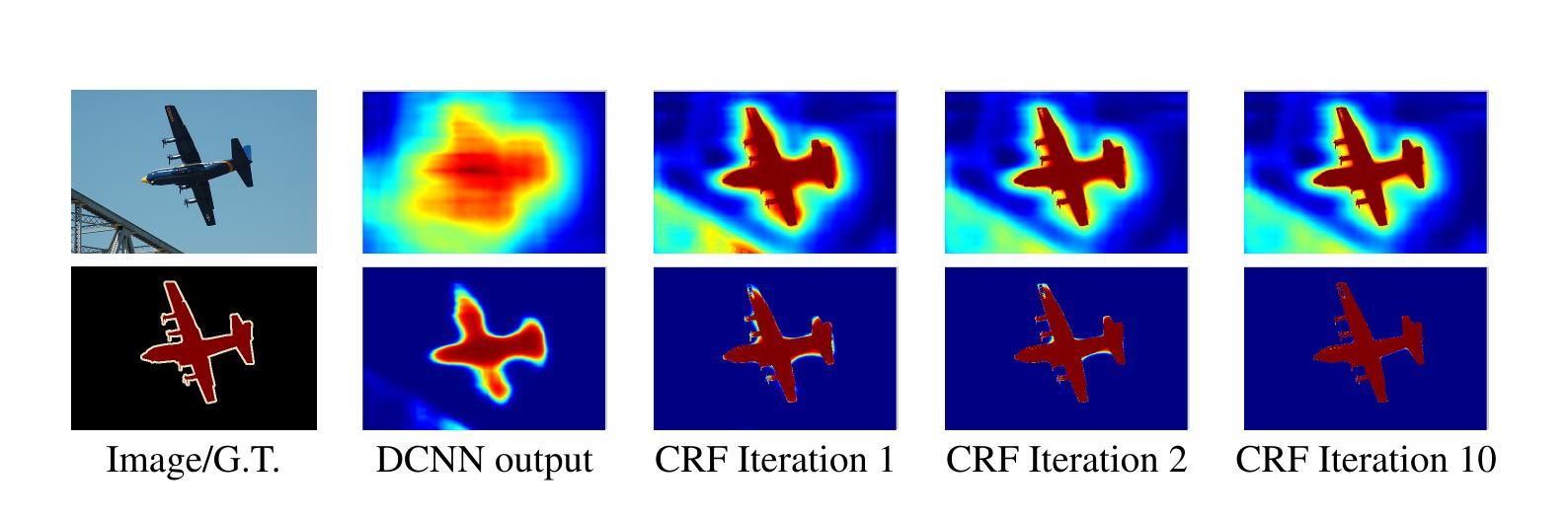
- Final layer of CNNs not sufficiently localized for accurate pixel-level object segmentation
- Overcome poor localization by combining final CNN layer with fully connected Conditional Random Field 1
- Using a fully convolutional VGG-16 network
- Modified convolutional filters by applying the 'atrous' algorithm from wavelet community instead of subsampling
- Significantly advanced the state-of-the-art in PASCAL VOC 2012 in semantic segmentation
1. Krahenbuhl, P. and Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. In NIPS, 2011.
| Optical Flow Methods | |||
|
CVPR 2016
Chen2016CVPR | |||

- Discrete optimization over the full space of mappings for optical flow
- Using a classical formulation with a normalized cross-correlation data term
- Effective optimization over large label space with TRW-S
- Min-convolution reduces the complexity of message passing from squared to linear
- Reducing the space of mappings using a smaller resolution and max displacements
- Epic Flow interpolation to fill inconsistent pixel and post processing for subpixel precision
- State-of-the-art results on Sintel and KITTI 2015
| Object Detection Methods | |||
|
NIPS 2015
Chen2015NIPS | |||

- Generating 3D object proposals by placing 3D bounding boxes on the image
- Exploiting stereo and contextual models specific to autonomous driving
- Minimizing an energy function encoding
- object size priors
- ground plane
- depth-related cues free space, point cloud densities, distance to the ground
- Experiments on KITTI
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
THREEDV 2016
Cherabier2016THREEDV | |||
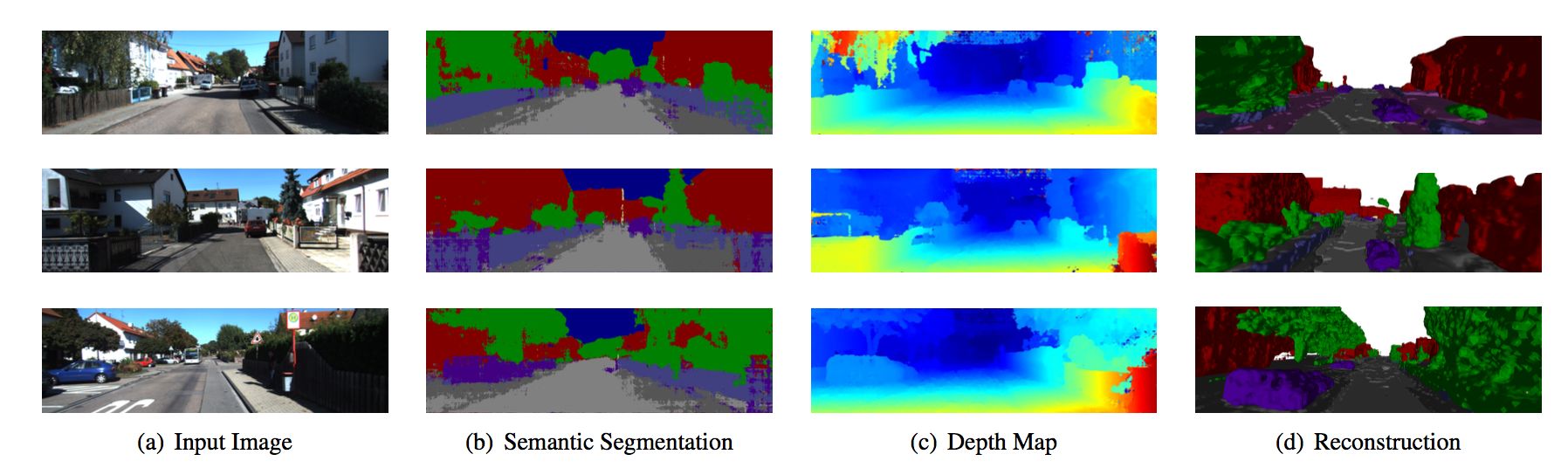
- Efficient dense 3D reconstruction and semantic segmentation
- Motivation: Current approaches can only handle a low number of semantic labels due to high memory consumption
- Idea: Dividing the scene into blocks in which generally only a subset of labels is active
- Active blocks are determined early and updated during the iterative optimization
- Evaluations on KITTI
- Reduced memory usage with more number of labels, ie 9
| Object Tracking State of the Art on MOT & KITTI | |||
|
ICCV 2015
Choi2015ICCV | |||
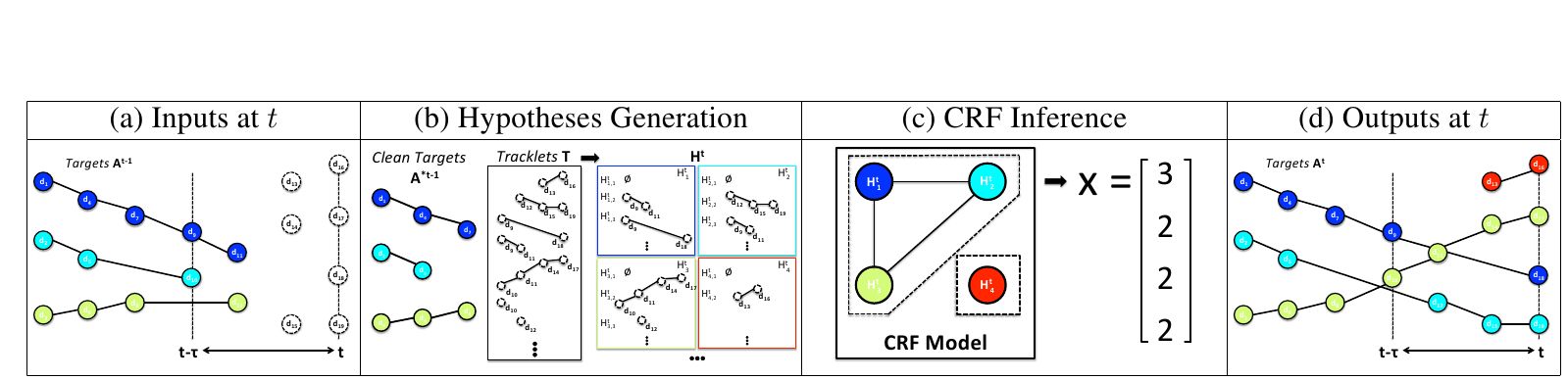
- Near-Online Multi-target Tracking (NOMT) algorithm formulated as global data association between targets and detections in temporal window
- Designing an accurate affinity measure to associate detections and estimate the likelihood of matching
- Aggregated Local Flow Descriptor (ALFD) encodes the relative motion pattern using long term interest point trajectories
- Integration of multiple cues including ALFD metric, target dynamics, appearance similarity and long term trajectory regularization
- Solves the association problem with a parallelized junction tree algorithm
- Best accuracy with significant margins on KITTI and MOT dataset
| Object Tracking Methods | |||
|
PAMI 2013
Choi2013PAMI | |||
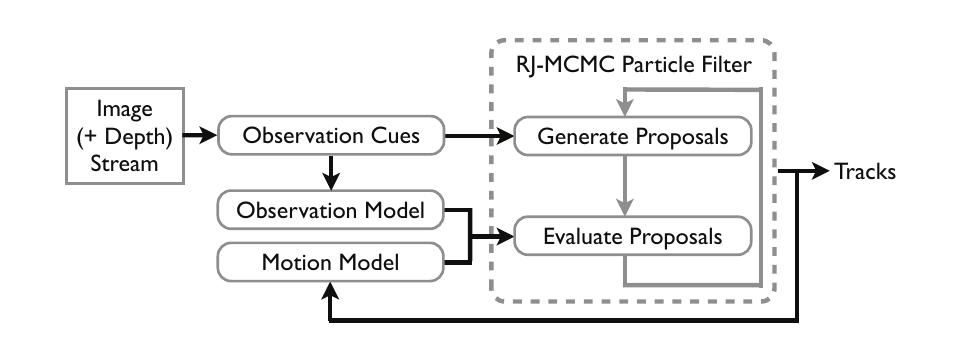
- Tracking multiple, possibly interacting, people from a mobile vision platform
- Joint estimation of camera's ego-motion and the people's trajectory in 3D
- Tracking problem formulated as finding a MAP solution and solved using Reversible Jump Markov Chain Monte Carlo Particle Filtering
- Combination of multiple observation cues face, skin color, depth-based shape, motion, and target specific appearance-based detector
- Modelling interaction with two modes: repulsion and group movement
- Automatic detection of static features for camera estimation
- Evaluation on the challenging ETH dataset and a Kinect RGB-D dataset containing dynamic in- and outdoor scenes
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
CVPR 1996
Collins1996CVPR | |||
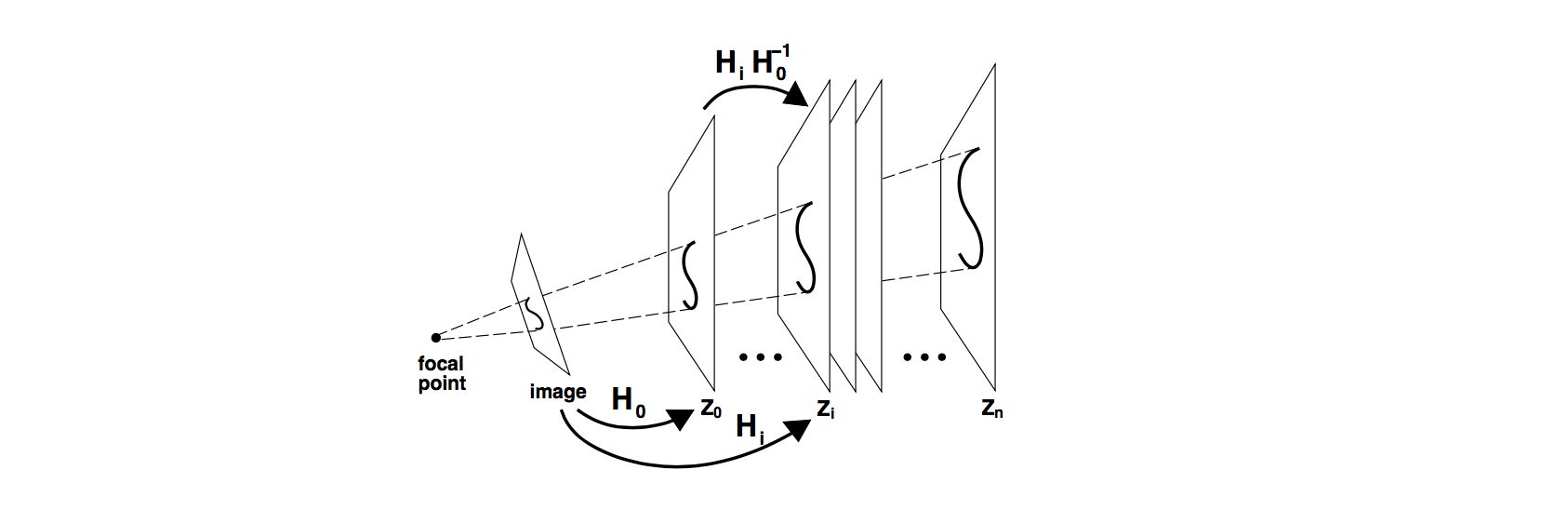
- The space-sweep approach to {it true multi-image matching}
- generalizing to any number of images
- linear complexity in the number of images
- using all images in an equal manner
- Algorithm:
- A single plane partitioned into cells is swept through the volume of space along a line perpendicular to the plane (along the Z axis of the scene).
- At each position of the plane along the sweeping path, the number of viewing rays that intersect each cell are tallied by back-projecting point features from each image onto the sweeping plane.
- After accumulating counts from feature points in all of the images, cells containing counts that are large enough are hypothesized as the locations of 3D points.
- The plane then continues its sweep to the next Z location.
| Datasets & Benchmarks | |||
|
CVPR 2016
Cordts2016CVPR | |||

- A benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling
- Specially tailored for autonomous driving in an urban environment
- Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities
- 5000 of these images have high quality pixel-level annotations
- 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data
- Develops a sound evaluation methodology for semantic labeling by introducing a novel evaluation measure
- Evaluates several state-of-the-art approaches on the benchmark
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
CVPR 2016
Cordts2016CVPR | |||
- A benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling
- Specially tailored for autonomous driving in an urban environment
- Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities
- 5000 of these images have high quality pixel-level annotations
- 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data
- Develops a sound evaluation methodology for semantic labeling by introducing a novel evaluation measure
- Evaluates several state-of-the-art approaches on the benchmark
| Semantic Segmentation Problem Definition | |||
|
CVPR 2016
Cordts2016CVPR | |||
- A benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling
- Specially tailored for autonomous driving in an urban environment
- Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities
- 5000 of these images have high quality pixel-level annotations
- 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data
- Develops a sound evaluation methodology for semantic labeling by introducing a novel evaluation measure
- Evaluates several state-of-the-art approaches on the benchmark
| Semantic Segmentation Datasets | |||
|
CVPR 2016
Cordts2016CVPR | |||
- A benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling
- Specially tailored for autonomous driving in an urban environment
- Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities
- 5000 of these images have high quality pixel-level annotations
- 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data
- Develops a sound evaluation methodology for semantic labeling by introducing a novel evaluation measure
- Evaluates several state-of-the-art approaches on the benchmark
| Semantic Segmentation Metrics | |||
|
CVPR 2016
Cordts2016CVPR | |||
- A benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling
- Specially tailored for autonomous driving in an urban environment
- Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities
- 5000 of these images have high quality pixel-level annotations
- 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data
- Develops a sound evaluation methodology for semantic labeling by introducing a novel evaluation measure
- Evaluates several state-of-the-art approaches on the benchmark
| Semantic Instance Segmentation Methods | |||
|
CVPR 2016
Cordts2016CVPR | |||
- A benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling
- Specially tailored for autonomous driving in an urban environment
- Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities
- 5000 of these images have high quality pixel-level annotations
- 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data
- Develops a sound evaluation methodology for semantic labeling by introducing a novel evaluation measure
- Evaluates several state-of-the-art approaches on the benchmark
| Semantic Instance Segmentation Datasets | |||
|
CVPR 2016
Cordts2016CVPR | |||
- A benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling
- Specially tailored for autonomous driving in an urban environment
- Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities
- 5000 of these images have high quality pixel-level annotations
- 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data
- Develops a sound evaluation methodology for semantic labeling by introducing a novel evaluation measure
- Evaluates several state-of-the-art approaches on the benchmark
| Semantic Instance Segmentation Metrics | |||
|
CVPR 2016
Cordts2016CVPR | |||
- A benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling
- Specially tailored for autonomous driving in an urban environment
- Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities
- 5000 of these images have high quality pixel-level annotations
- 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data
- Develops a sound evaluation methodology for semantic labeling by introducing a novel evaluation measure
- Evaluates several state-of-the-art approaches on the benchmark
| Semantic Segmentation Methods | |||
|
GCPR 2014
Cordts2014GCPR | |||

- Existing stixels representations are solely based on dense stereo and a strongly simplifying world model with a nearly planar road surface and perpendicular obstacles
- Whenever depth measurements are noisy or the world model is violated, Stixels are prone to error
- Contributions:
- Shows a principled way to incorporate top-down prior knowledge from object detectors into the Stixel generation
- The additional information not only improves the representation of the detected object classes, but also of other parts in the scene, e.g. the freespace
- Evaluates on stereo sequence introduced in the paper
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
IJCV 2008
Cornelis2008IJCV | |||
- Fast and memory efficient 3D city modelling
- Application: a pre-visualization of a required traffic manoeuvre for navigation systems
- Simplified geometry assumptions while still having compact models
- Adapted dense stereo algorithm with ruled-surface approximation
- Integrating object recognition for detecting cars in video and then localizing them in 3D (not real-time yet)
- 3D reconstruction and localization benefit from each other.
- Tested on three stereo sequences annotated with GPS/INS measurements
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
IJRR 2008
Cummins2008IJRR | |||
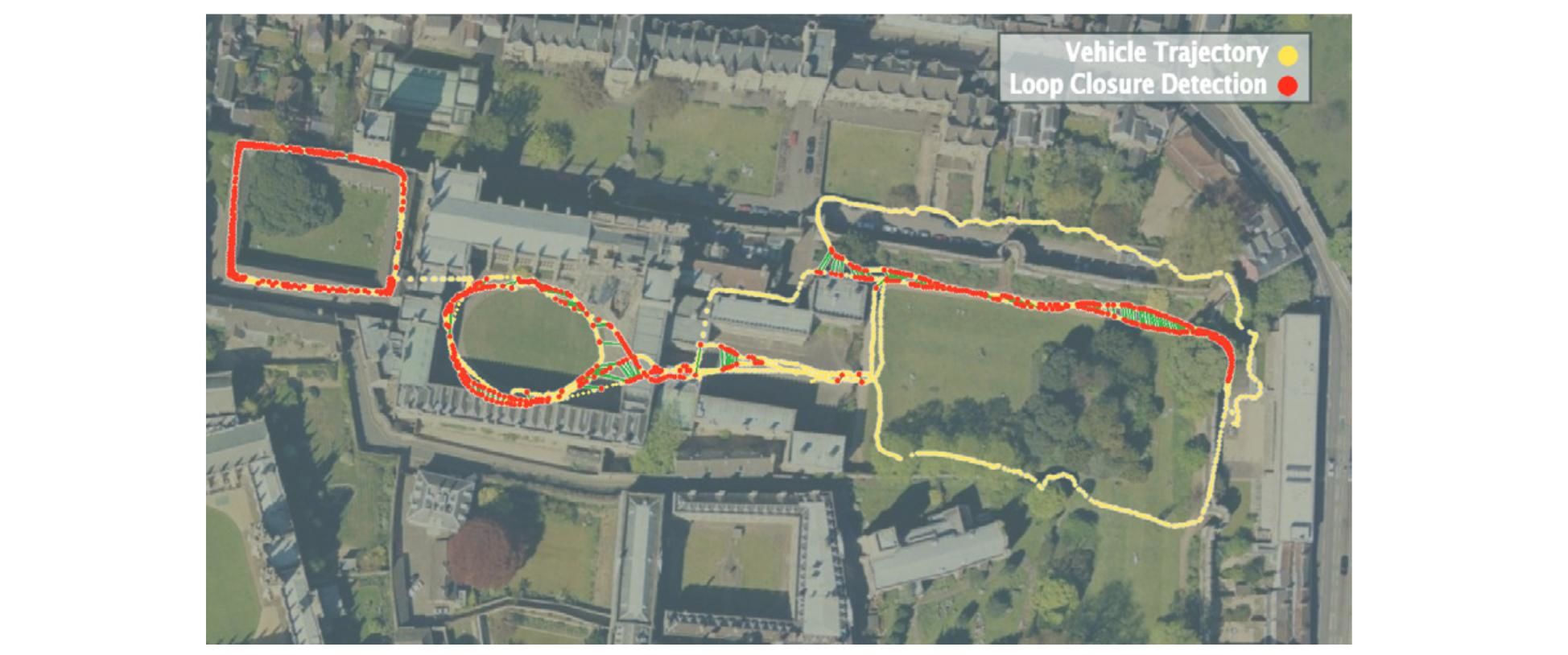
- Probabilistic approach to recognize places based on their appearance (loop closure detection)
- Topological SLAM by learning a generative model of place appearances using bag-of-words
- Combination of appearance words occur because they are generated from common objects
- Approximation of a discrete distribution using Chow Liu algorithm
- Robust in visually repetitive environments
- Complexity linear in number of places and the algorithm is suitable for online loop closure detection in mobile robotics
- Demonstration by detecting loop closures over 2km path in an initially unknown outdoor environment
| Mapping, Localization & Ego-Motion Estimation Metrics | |||
|
IJRR 2008
Cummins2008IJRR | |||
- Probabilistic approach to recognize places based on their appearance (loop closure detection)
- Topological SLAM by learning a generative model of place appearances using bag-of-words
- Combination of appearance words occur because they are generated from common objects
- Approximation of a discrete distribution using Chow Liu algorithm
- Robust in visually repetitive environments
- Complexity linear in number of places and the algorithm is suitable for online loop closure detection in mobile robotics
- Demonstration by detecting loop closures over 2km path in an initially unknown outdoor environment
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
SIGGRAPH 1996
Curless1996SIGGRAPH | |||
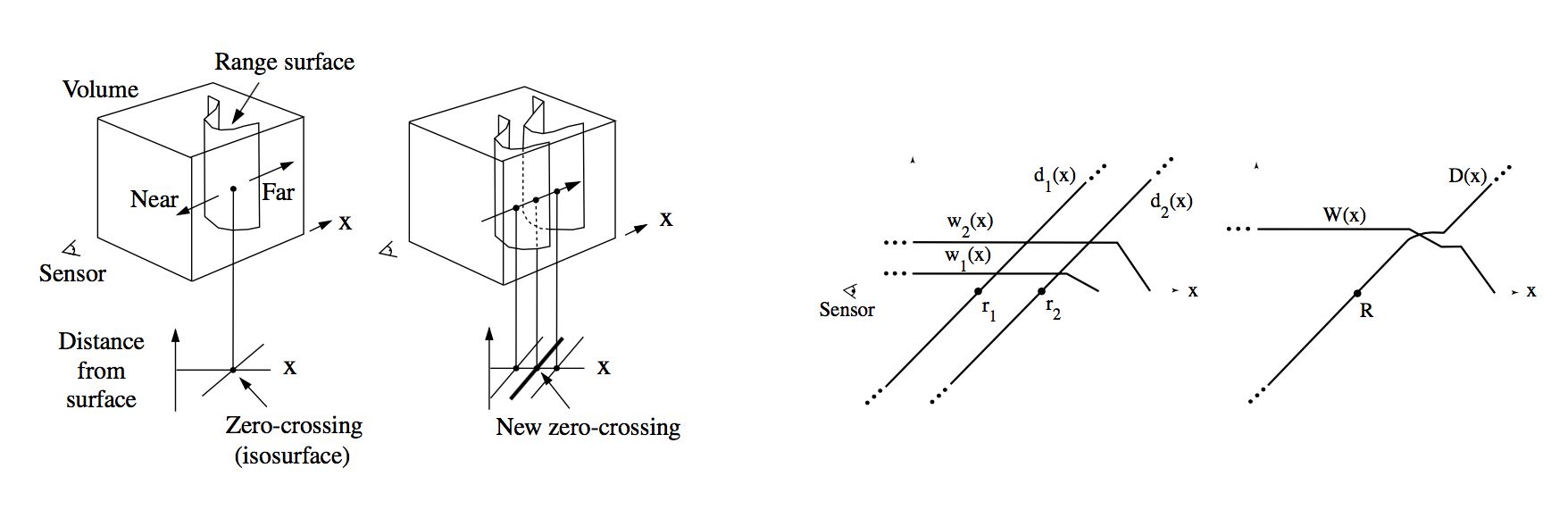
- A volumetric representation for integrating a large number of range images
- Incremental and order independent updating based on a cumulative weighted signed distance function (TSDF)
- Representation of directional uncertainty with weights
- Utilization of all range data
- No restrictions on topological type, ie without simplifying assumptions
- Time and space efficiency
- The ability to fill gaps in the reconstruction using space carving
- Robustness in the presence of outliers
- Final manifold by extracting an isosurface from the volumetric grid
- Easy to parallelize in the implementation
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
SIGGRAPH 1996
Curless1996SIGGRAPH | |||
- A volumetric representation for integrating a large number of range images
- Incremental and order independent updating based on a cumulative weighted signed distance function (TSDF)
- Representation of directional uncertainty with weights
- Utilization of all range data
- No restrictions on topological type, ie without simplifying assumptions
- Time and space efficiency
- The ability to fill gaps in the reconstruction using space carving
- Robustness in the presence of outliers
- Final manifold by extracting an isosurface from the volumetric grid
- Easy to parallelize in the implementation
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
ECMR 2015
Cvisic2015ECMR | |||
- Stereo visual odometry based on feature selection and tracking (SOFT) for us: a good taxonomy is provided in intro
- Careful selection of a subset of stable features and their tracking through the frames
- Separate estimation of rotation (the five point) and translation (the three point)
- Evaluated on KITTI, outperforming all
- Pose error of 1.03 with processing speed above 10 Hz
- A modified IMU-aided version of the algorithm
- An IMU for outlier rejection and Kalman filter for rotation refinement
- Fast and suitable for embedded systems at 20 Hz on an ODROID U3 ARM-based embedded computer
| Semantic Instance Segmentation Methods | |||
|
CVPR 2016
Dai2016CVPR | |||
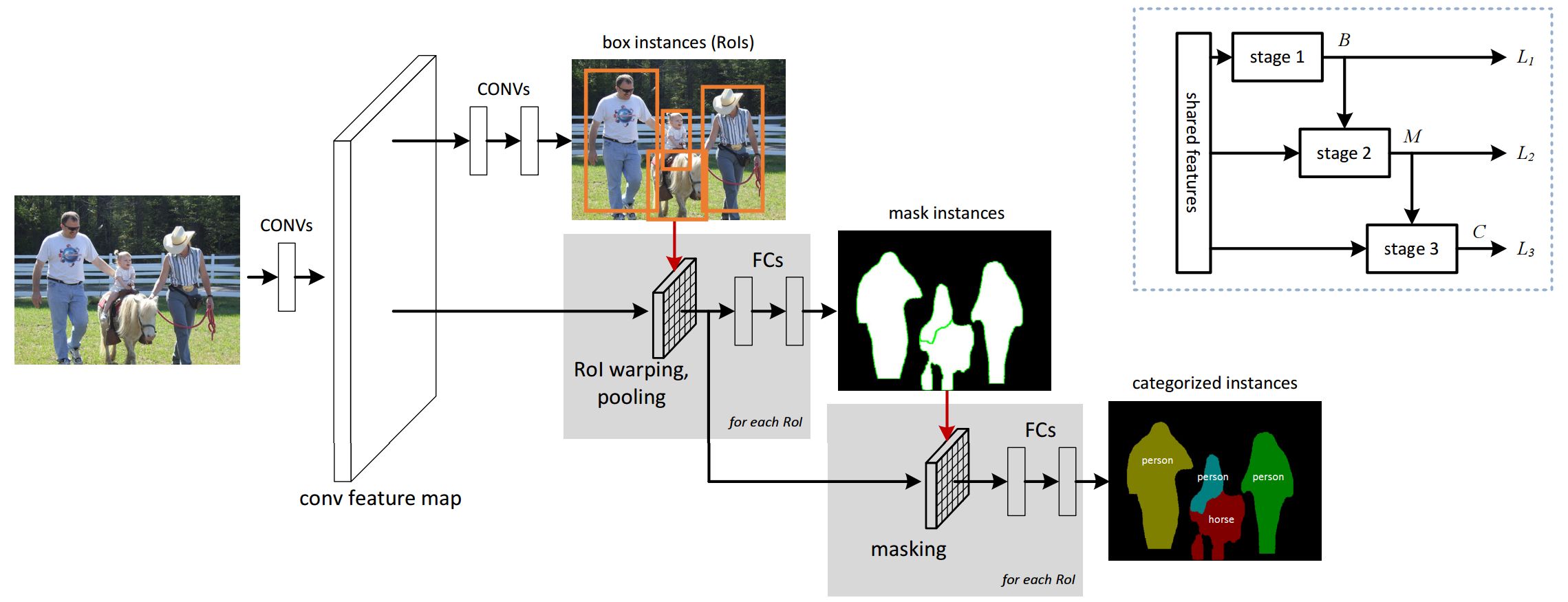
- Limitations of existing methods for instance segmentation using CNNs
- Slow at inference time because they require mask propasal methods
- Don't take advantage of deep features and large amount of training data
- End-to-end training of Multi-task Network Cascades for 3 tasks of differentiating instances, estimating masks & categorizing objects
- Two orders of magnitude faster than previous systems
- State-of-the-art on PASCAL VOC & MS COCO 2015
| 3D Scene Flow Methods | |||
|
CVPR 2016
Dai2016CVPR | |||
- Limitations of existing methods for instance segmentation using CNNs
- Slow at inference time because they require mask propasal methods
- Don't take advantage of deep features and large amount of training data
- End-to-end training of Multi-task Network Cascades for 3 tasks of differentiating instances, estimating masks & categorizing objects
- Two orders of magnitude faster than previous systems
- State-of-the-art on PASCAL VOC & MS COCO 2015
| Object Detection Methods | |||
|
CVPR 2005
Dalal2005CVPR | |||

- Show that Histograms of oriented Gradient (HOG) descriptors outperforms previous feature sets for human detection
- Analyze each stage of the computation on the performance of the approach
- Near-perfect separation on the original MIT pedestrian database
- Introduction of a more challenging dataset containing over 1800 annotated human images with large range of pose variations and backgrounds
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
CVPR 2013
Dame2013CVPR | |||
- Incorporation of object-specific knowledge into SLAM
- Current approaches
- Limited to the reconstruction of visible surfaces
- Photo-consistency error, sensitive to specularities
- Initial dense representation using photo-consistency
- Detection using a standard 2D sliding-window object-class detector
- A novel energy to find the 6D pose and shape of the object
- Shape-prior represented using GP-LVM
- Efficient fusion of the dense reconstruction with the reconstructed object shape
- Better reconstruction in terms of clarity, accuracy and completeness
- Faster and more reliable convergence of the segmentation with 3D data
- Evaluated using dense reconstruction from KinectFusion
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
GCPR 2016
Deigmoeller2016GCPR | |||
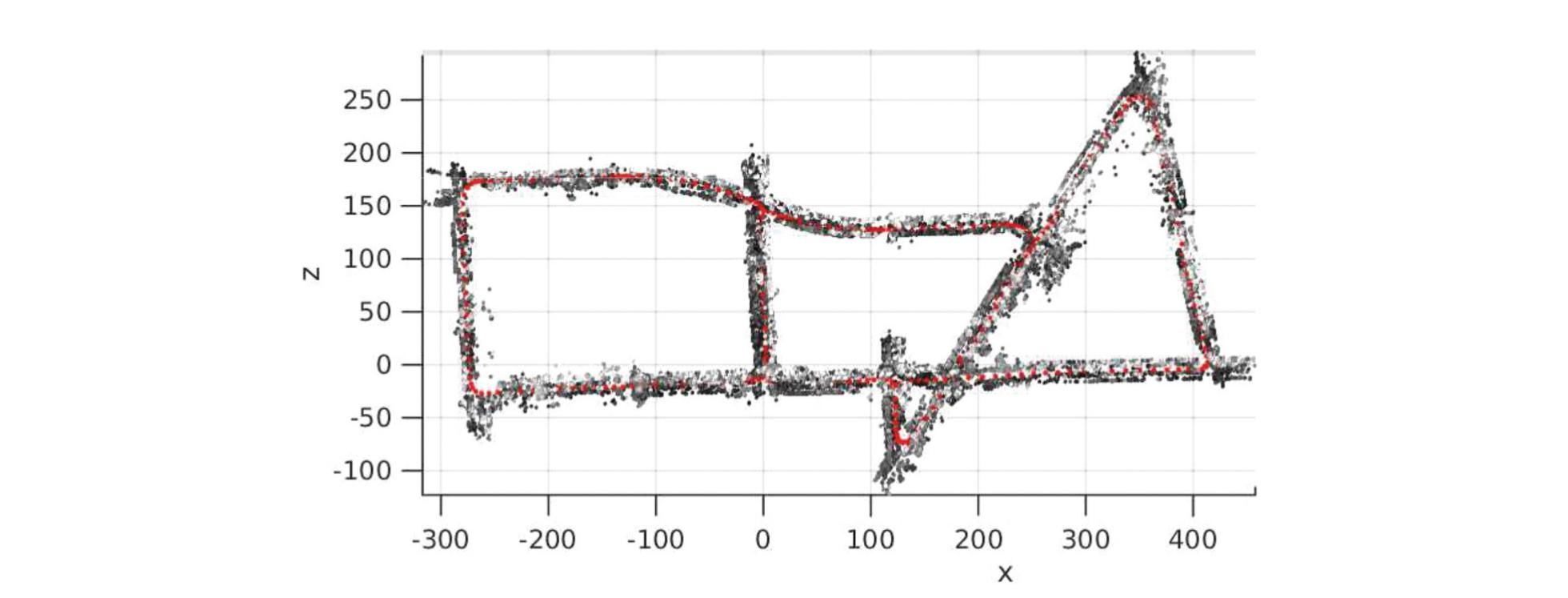
- Ego-motion estimation from stereo avoiding temporal filtering and relying exclusively on pure measurements
- Stereo camera set-up is the easiest and leads currently to the most accurate results
- Two parts
- Scene flow estimation with a combination of disparity and optical flow on Harris corners
- Pose estimation with a P6P method (perspective from 6 points) encapsulated in a RANSAC framework
- Careful selections of precise measurements by purely varying geometric constraints on optical flow measure
- Slim method within the top ranks of KITTI without filtering like bundle adjustment or Kalman filtering
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
ICRA 1999
Dellaert1999ICRA | |||
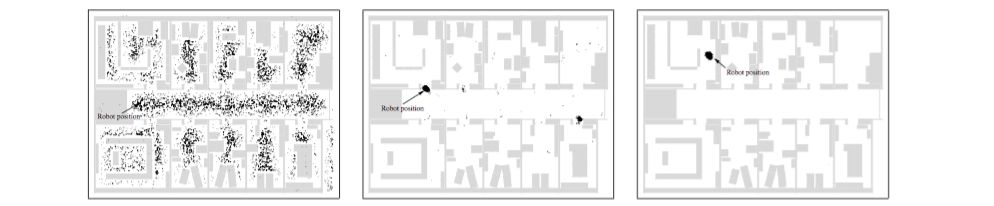
- Presents the Monte Carlo method for localization for mobile robots
- Represents uncertainty by maintaining a set of samples that are randomly drawn from it instead of describing the probability density function itself
- Contributions:
- In contrast to Kalman filtering based techniques, it is able to represent multi-modal distributions and thus can globally localize a robot
- Reduces the amount of memory required compared to grid-based Markov localization
- More accurate than Markov localization with a fixed cell size, as the state represented in the samples is not discretized
- Evaluates on datasets introduced in the paper
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
Square Root SAM: Simultaneous Localization and Mapping via Square Root Information Smoothing[scholar]
|
IJRR 2006
Dellaert2006IJRR | ||
| Datasets & Benchmarks | |||
|
CVPR 2009
Deng2009CVPR | |||

- A large-scale annotated images organized by the semantic hierarchy of WordNet
- 12 subtrees with 5247 synsets and 3.2 million images in total
- Properties: scale, hierarchy, accuracy, diversity
- Much larger in scale and diversity and much more accurate than the current image datasets
- Data collection with Amazon Mechanical Turk
- Example applications shown: object recognition, image classification and automatic object clustering
| Datasets & Benchmarks Computer Vision Datasets | |||
|
CVPR 2009
Deng2009CVPR | |||
- A large-scale annotated images organized by the semantic hierarchy of WordNet
- 12 subtrees with 5247 synsets and 3.2 million images in total
- Properties: scale, hierarchy, accuracy, diversity
- Much larger in scale and diversity and much more accurate than the current image datasets
- Data collection with Amazon Mechanical Turk
- Example applications shown: object recognition, image classification and automatic object clustering
| Object Detection Datasets | |||
|
CVPR 2009
Deng2009CVPR | |||
- A large-scale annotated images organized by the semantic hierarchy of WordNet
- 12 subtrees with 5247 synsets and 3.2 million images in total
- Properties: scale, hierarchy, accuracy, diversity
- Much larger in scale and diversity and much more accurate than the current image datasets
- Data collection with Amazon Mechanical Turk
- Example applications shown: object recognition, image classification and automatic object clustering
| Object Detection Metrics | |||
|
CVPR 2009
Deng2009CVPR | |||
- A large-scale annotated images organized by the semantic hierarchy of WordNet
- 12 subtrees with 5247 synsets and 3.2 million images in total
- Properties: scale, hierarchy, accuracy, diversity
- Much larger in scale and diversity and much more accurate than the current image datasets
- Data collection with Amazon Mechanical Turk
- Example applications shown: object recognition, image classification and automatic object clustering
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
CVPR 2009
Deng2009CVPR | |||
- A large-scale annotated images organized by the semantic hierarchy of WordNet
- 12 subtrees with 5247 synsets and 3.2 million images in total
- Properties: scale, hierarchy, accuracy, diversity
- Much larger in scale and diversity and much more accurate than the current image datasets
- Data collection with Amazon Mechanical Turk
- Example applications shown: object recognition, image classification and automatic object clustering
| History of Autonomous Driving | |||
|
IV 1994
Dickmanns1994IV | |||
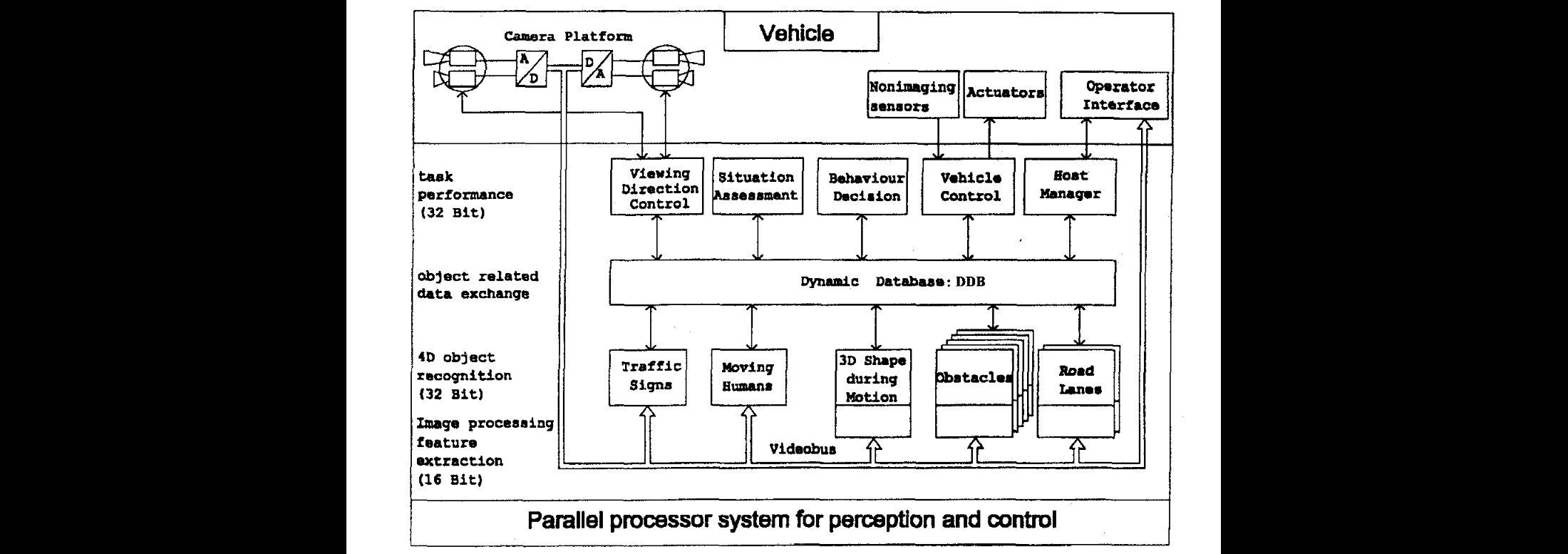
- Equipment of a passenger car Mercedes 500 SEL with sense of vision in the framework of the EUREKA-project 'Prometheus III'
- Road and object recognition performed in a look-ahead and look-back region newline allows internal servo-maintained representation of the situation around the vehicle
- Obstacle detection and tracking in forward and backward direction in a viewing range up to 100m
- Depending on computing power tracking of up to 4 or 5 objects in each direction possible
- Overall system comprises about 60 transputers T-222 (for image processing and communication) and T-800(for number crunching and knowledge processing)
- System has not been tested to its performance limit
| History of Autonomous Driving | |||
|
SMC 1990
Dickmanns1990SMC | |||
- Extension of the Kalman filter approach to image sequence processing
- Allows confine image processing to the last frame of the sequence
- Spatial interpretations are obtained in just one step, including spatial velocity components
- Results on road vehicle guidance at high speeds including obstacle detection and monocular relative spatial state estimation are presented
- Corresponding data processing architecture is discussed
- System has been implemented on a MIMD parallel processing system
- Demonstration of speeds up to 100 km/h
| Object Detection Datasets | |||
|
PAMI 2012
Dollar2012PAMI | |||

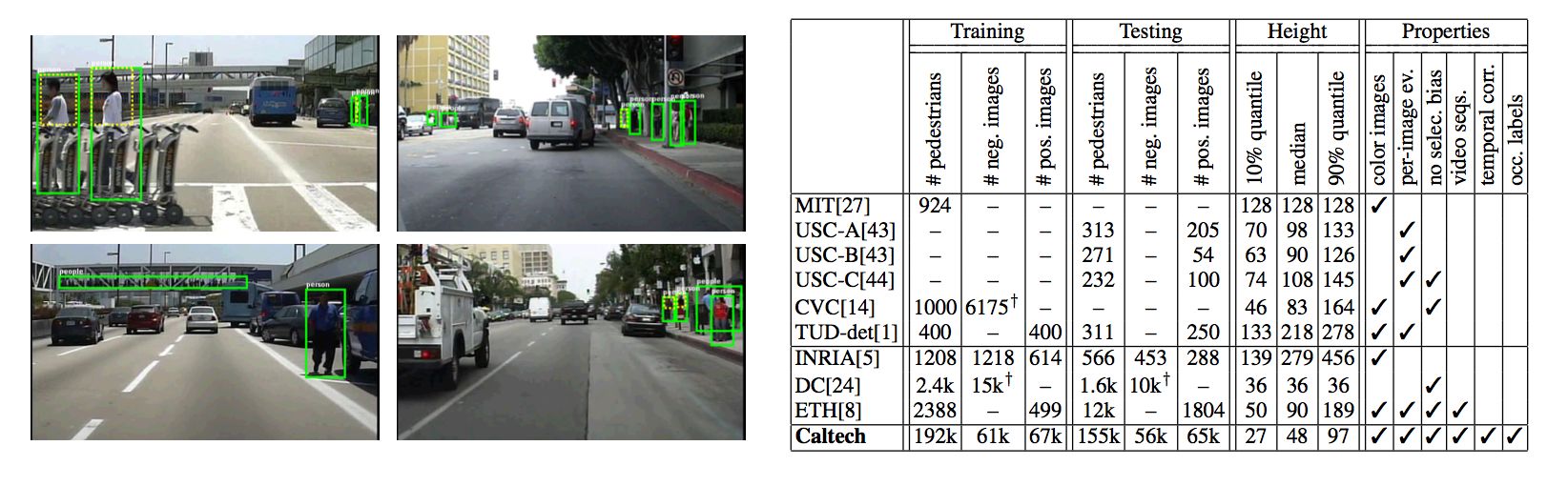
- Evaluation of pedestrian detection methods in a unified framework
- Monocular pedestrian detection data set with statistics of the size, position, and occlusion patterns of pedestrians in urban scenes (Caltech Pedestrian Data Set)
- Per-frame evaluation methodology considering performance in relation to scale and occlusion, also measuring localization accuracy and analyzing runtime
- Evaluating the performance of sixteen detectors across six data sets.
- Detection is disappointing at low resolutions and for partially occluded pedestrians.
| Object Detection Methods | |||
|
PAMI 2011
Dollar2011PAMI | |||
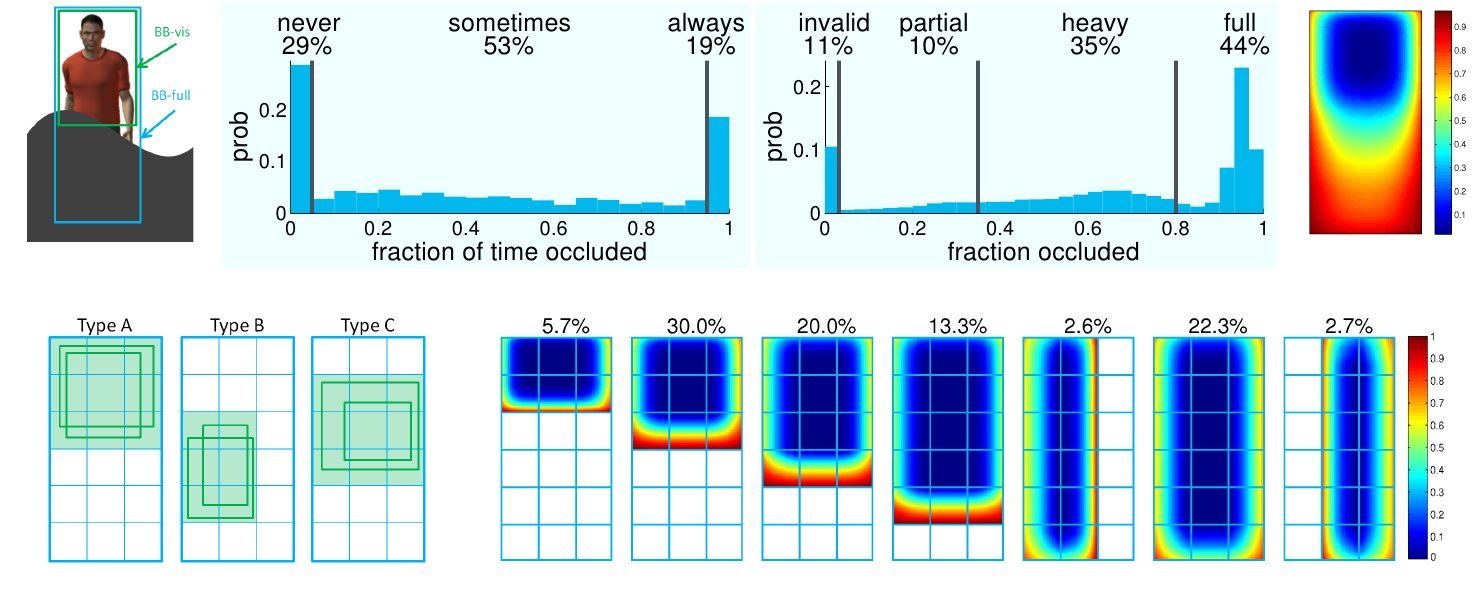
- Pedestrian detection methods are hard to compare because of multiple datasets and varying evaluation protocols
- Extensive evaluation of the state of the art in a unified framework
- Large, well-annotated and realistic monocular pedestrian detection dataset
- Refined per-frame evaluation methodology
- Evaluation of sixteen pre-trained state-of-the-art detectors across six datasets
- Performance of state-of-the-art is disappointing at low resolutions (far distant pedestrians) and in case of partial occlusions
| Datasets & Benchmarks | |||
|
CVPR 2009
Dollar2009CVPR | |||
- Caltech Pedestrian Dataset:
- richly annotated video, recorded from a moving vehicle
- pedestrians varying widely in appearance, pose and scale
- challenging low resolution
- temporal correspondence between BBs
- detailed occlusion labels
- frequently occluded people (only 30 of pedestrians remain unoccluded for the entire time they are present)
- Improved evaluation metrics
- Benchmarking existing pedestrian detection systems
- Analyzing common failure cases, detection at smaller scales and of partially occluded pedestrians
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
CVPR 2009
Dollar2009CVPR | |||
- Caltech Pedestrian Dataset:
- richly annotated video, recorded from a moving vehicle
- pedestrians varying widely in appearance, pose and scale
- challenging low resolution
- temporal correspondence between BBs
- detailed occlusion labels
- frequently occluded people (only 30 of pedestrians remain unoccluded for the entire time they are present)
- Improved evaluation metrics
- Benchmarking existing pedestrian detection systems
- Analyzing common failure cases, detection at smaller scales and of partially occluded pedestrians
| Datasets & Benchmarks | |||
|
ICCV 2015
Dosovitskiy2015ICCV | |||
- Network is trained end-to-end
- The contracting part of the network extracts rich feature representation
- Simple architecture : Process 2 stacked images jointly
- Alternative architecture : Process images separately, then correlate their features at different locations
- Expanding part of network produces high resolution flow
- Train networks on large "Flying chairs" dataset with 2D motion of rendered chairs
- Evaluated on Sintel and KITTI. Beats state of art among real time methods
| Datasets & Benchmarks Computer Vision Datasets | |||
|
ICCV 2015
Dosovitskiy2015ICCV | |||
- Network is trained end-to-end
- The contracting part of the network extracts rich feature representation
- Simple architecture : Process 2 stacked images jointly
- Alternative architecture : Process images separately, then correlate their features at different locations
- Expanding part of network produces high resolution flow
- Train networks on large "Flying chairs" dataset with 2D motion of rendered chairs
- Evaluated on Sintel and KITTI. Beats state of art among real time methods
| Datasets & Benchmarks Synthetic Data Generation using Game Engines | |||
|
ICCV 2015
Dosovitskiy2015ICCV | |||
- Network is trained end-to-end
- The contracting part of the network extracts rich feature representation
- Simple architecture : Process 2 stacked images jointly
- Alternative architecture : Process images separately, then correlate their features at different locations
- Expanding part of network produces high resolution flow
- Train networks on large "Flying chairs" dataset with 2D motion of rendered chairs
- Evaluated on Sintel and KITTI. Beats state of art among real time methods
| Stereo Methods | |||
|
ICCV 2015
Dosovitskiy2015ICCV | |||
- Network is trained end-to-end
- The contracting part of the network extracts rich feature representation
- Simple architecture : Process 2 stacked images jointly
- Alternative architecture : Process images separately, then correlate their features at different locations
- Expanding part of network produces high resolution flow
- Train networks on large "Flying chairs" dataset with 2D motion of rendered chairs
- Evaluated on Sintel and KITTI. Beats state of art among real time methods
| Stereo State of the Art on KITTI | |||
|
ICCV 2015
Dosovitskiy2015ICCV | |||
- Network is trained end-to-end
- The contracting part of the network extracts rich feature representation
- Simple architecture : Process 2 stacked images jointly
- Alternative architecture : Process images separately, then correlate their features at different locations
- Expanding part of network produces high resolution flow
- Train networks on large "Flying chairs" dataset with 2D motion of rendered chairs
- Evaluated on Sintel and KITTI. Beats state of art among real time methods
| Optical Flow Methods | |||
|
ICCV 2015
Dosovitskiy2015ICCV | |||
- Network is trained end-to-end
- The contracting part of the network extracts rich feature representation
- Simple architecture : Process 2 stacked images jointly
- Alternative architecture : Process images separately, then correlate their features at different locations
- Expanding part of network produces high resolution flow
- Train networks on large "Flying chairs" dataset with 2D motion of rendered chairs
- Evaluated on Sintel and KITTI. Beats state of art among real time methods
| Stereo Methods | |||
|
GCPR 2014
Drory2014GCPR | |||
- First principled explanation of SGM
- trivial to implement, extremely fast, and high ranking on benchmarks
- still a successful heuristic with no theoretical characterization
- Its exact relation to belief propagation and tree-reweighted message passing
- SGM's 8 direction scan-lines is an approximation to the optimal labelling of the entire graph.
- SGM amounts to the first iteration of TRW-T on a MRF with pairwise energies that have been scaled by a constant and known factor.
- Outcome: an uncertainty measure for the MAP labeling of an MRF
- Qualitative results on Middlebury Benchmark
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
ECCV 2014
Engel2014ECCV | |||
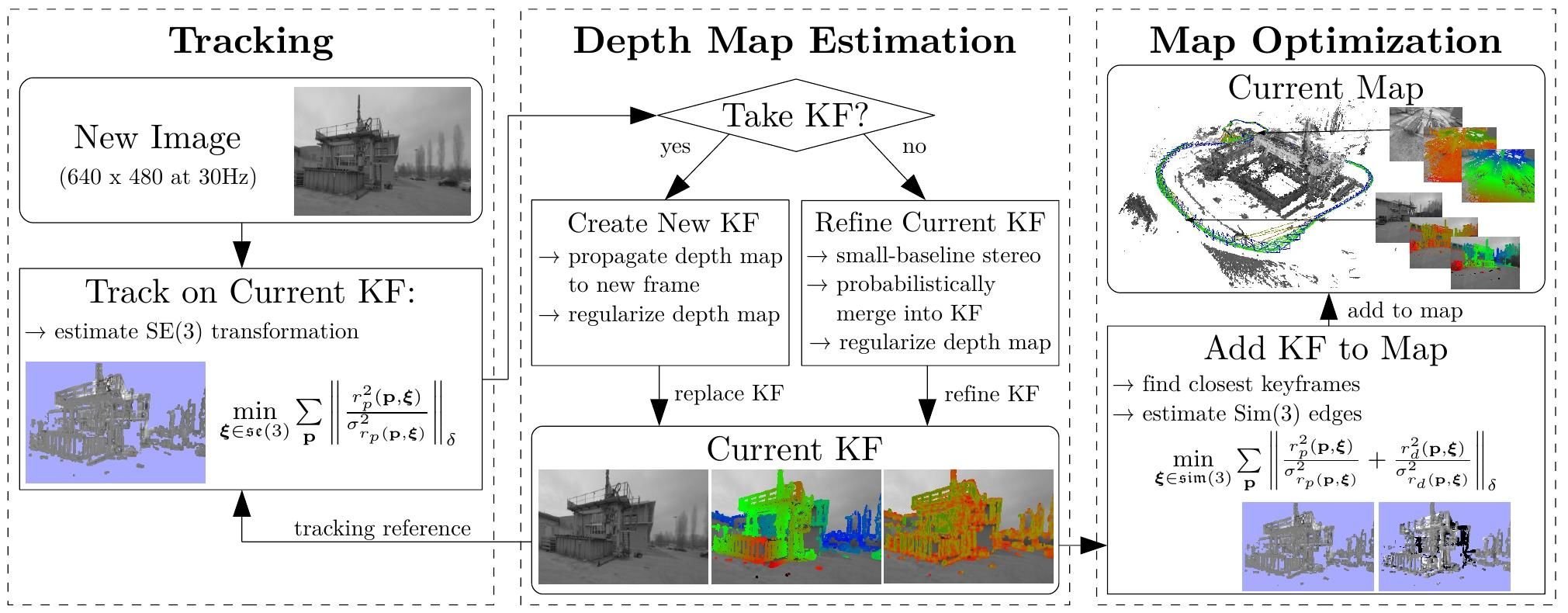
- Feature-less monocular SLAM algorithm which allows to build large-scale maps
- Novel direct tracking method that detects loop closures and scale-drift using similarity transform in 3D
- Direct image alignment with 3D reconstruction in real-time
- Pose-graph of keyframes with associated probabilistic semi-dense depth maps
- Semi-dense depth maps are obtained by filtering over a large number of pixelwise small-baseline stereo comparisons
- Probabilistic solution to include the effect of noisy depth values into tracking
- Evaluation on TUM RGB-D benchmark
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
IROS 2015
Engel2015IROS | |||
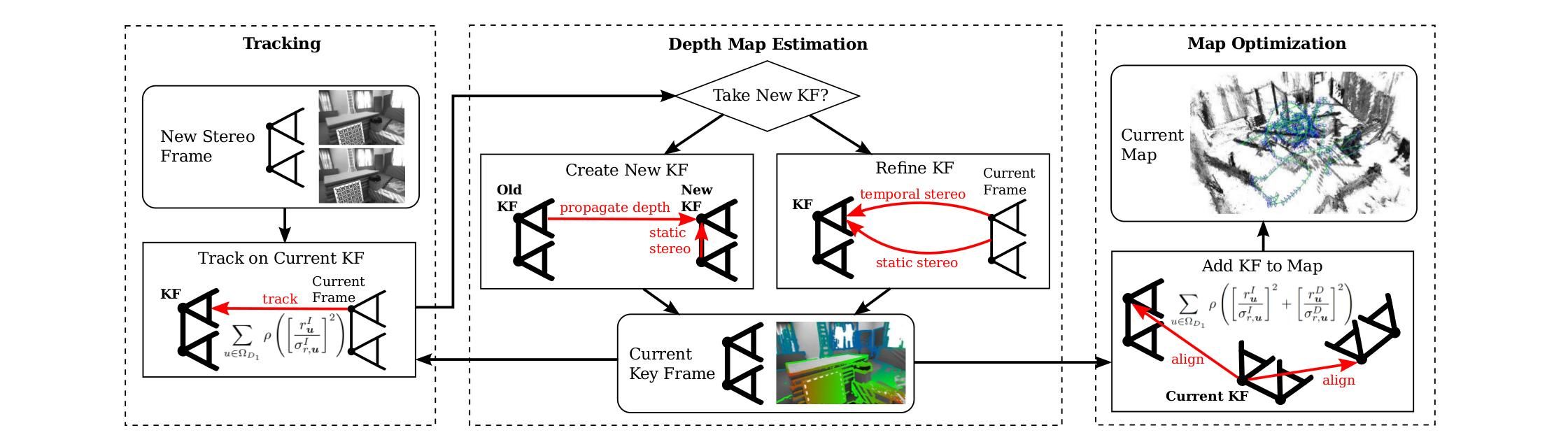
- Large-Scale Direct SLAM algorithm for stereo cameras (Stereo LSD-SLAM) that runs in real-time
- Direct alignment of the images based on photoconsistency of all high contrast pixel in contrast to sparse interest-point based methods
- Couple temporal multi-view stereo from monocular LSD-SLAM with static stereo from a fixed-baseline stereo camera setup
- Incorporating both disparity source allow to estimate depth of pixels that are under-constrained in fixed baseline stereo
- Fixed baseline avoids scale-drift that occurs in monocular SLAM
- Robust approach to enforce illumination invariance
- State-of-the-art results in KITTI and EuRoC Challenge 3 for micro aerial vehicles
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
IROS 2015
Engel2015IROS | |||
- Large-Scale Direct SLAM algorithm for stereo cameras (Stereo LSD-SLAM) that runs in real-time
- Direct alignment of the images based on photoconsistency of all high contrast pixel in contrast to sparse interest-point based methods
- Couple temporal multi-view stereo from monocular LSD-SLAM with static stereo from a fixed-baseline stereo camera setup
- Incorporating both disparity source allow to estimate depth of pixels that are under-constrained in fixed baseline stereo
- Fixed baseline avoids scale-drift that occurs in monocular SLAM
- Robust approach to enforce illumination invariance
- State-of-the-art results in KITTI and EuRoC Challenge 3 for micro aerial vehicles
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
ICCV 2013
Engel2013ICCV | |||

- Real-time visual odometry method for a monocular camera
- Continuously estimate a semi-dense inverse depth map which is used to track the motion of the camera
- Depth estimation for pixel with non-negligible gradients using multi-view stereo
- Each estimate is represented as a Gaussian probability distribution over the inverse depth (corresponds to update step of Kalman filter)
- Reference frame is selected such that the observation angle is small
- Propagate depth maps from frame to frame (corresponding to prediction step of Kalman filter) and refine with new stereo depth measurements
- Whole image alignment using depth estimates for tracking
- Comparable tracking performance with fully dense methods without requiring a depth sensor
| Object Detection Methods | |||
|
CVPR 2008
Enzweiler2008CVPR | |||
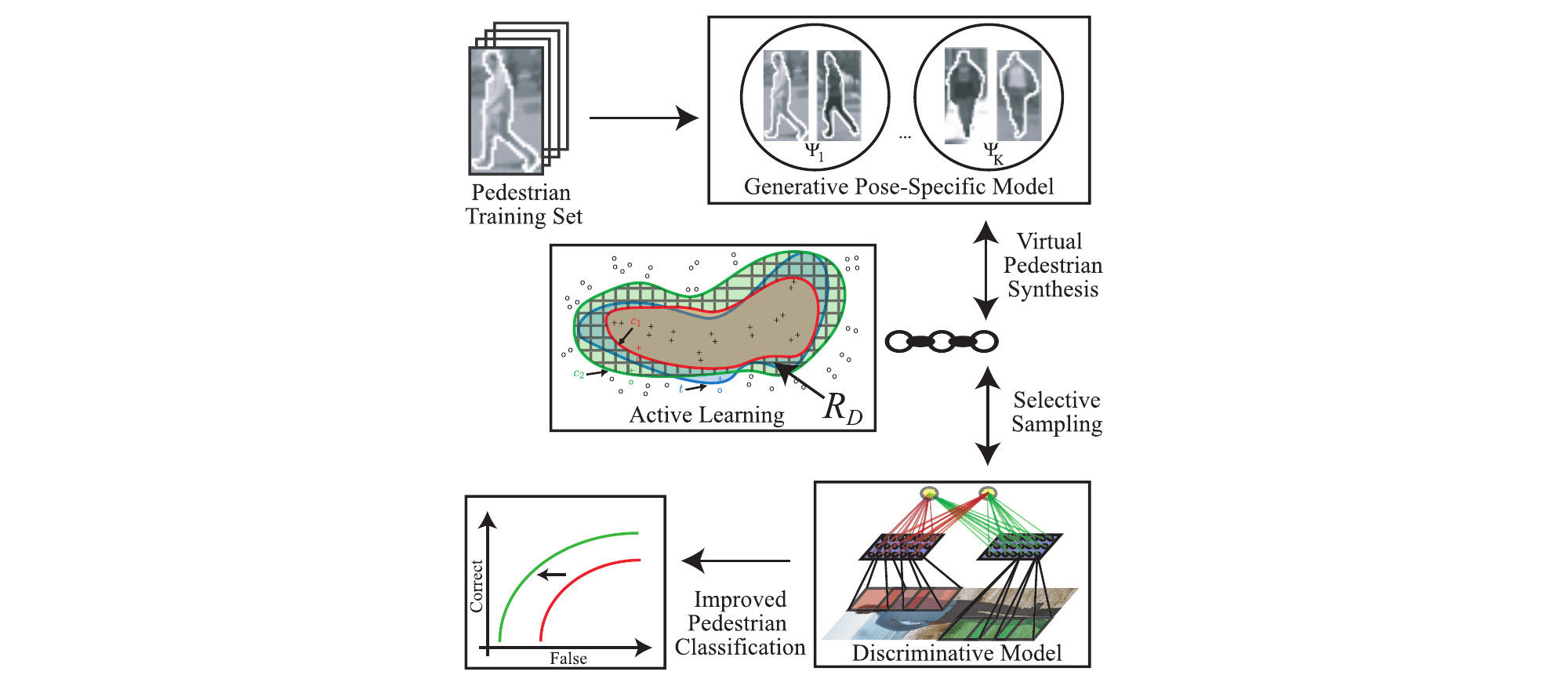
- Pedestrian classification utilizing synthesized virtual samples of a learned generative model to enhance a discriminative model
- Address bottleneck caused by the scarcity of samples of the target class
- Generative model captures prior knowledge about pedestrian class in terms of probabilistic shape and texture models
- Selective sampling, by means of probabilistic active learning, guides the training process towards the most informative samples
- Virtual samples can be considered as a regularization term to the real data
- Signification improvement in classification performance in large-scale real-world datasets
| Object Detection Problem Definition | |||
|
TIP 2011
Enzweiler2011TIP | |||
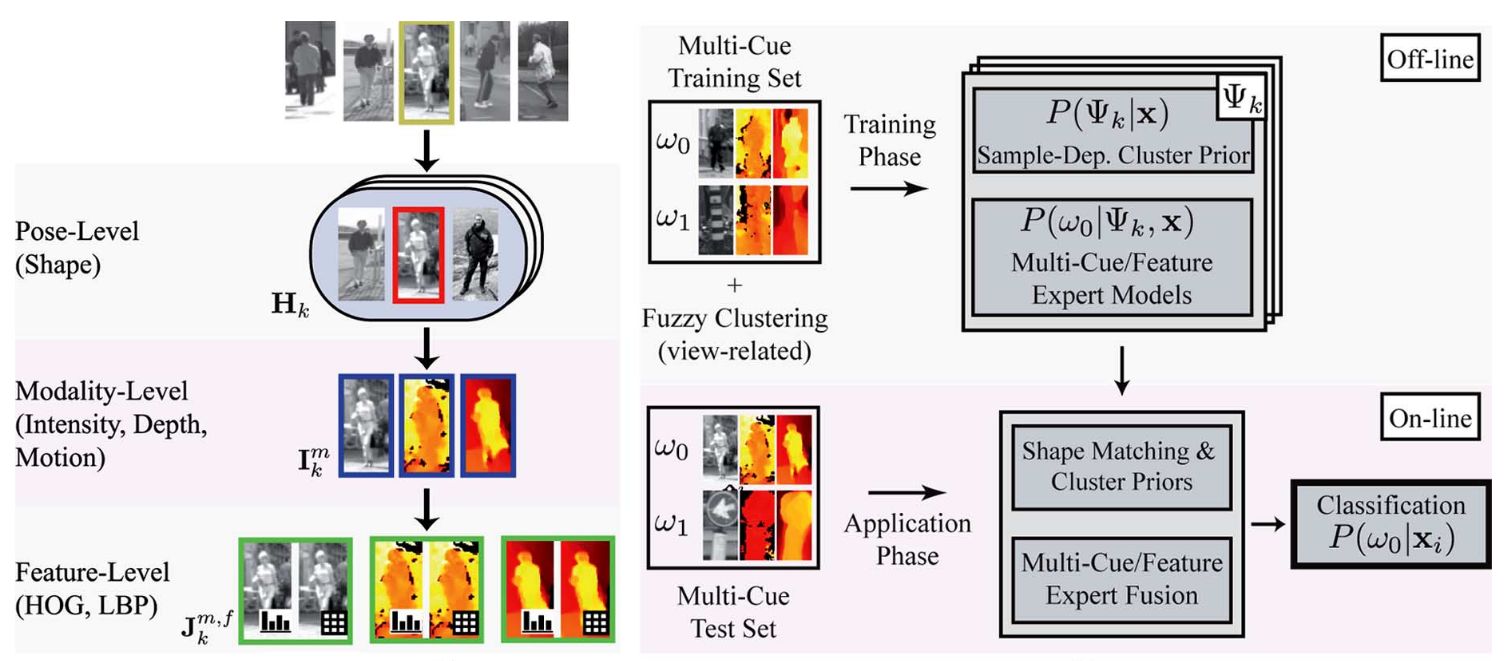
- Multilevel Mixture-of-Experts approach for pedestrian recognition
- Combining information from multiple features and cues
- Shape cues based on Chamfer shape matching provide sample-dependent priors for a certain pedestrian view
- Consider HOG and LBP as features with MLP and linSVM as classifiers
- Evaluation on a unique real world multi modality dataset captured from a vehicle in urban traffic
- Significant performance boost at that time up to a factor of 42 in reduction of false positives
| Object Detection Methods | |||
|
PAMI 2009
Enzweiler2009PAMI | |||
- Overview of the current state of the art in person detection from both methodological and experimental perspectives
- Survey: main components of a pedestrian detection system and the underlying model: hypothesis generation (ROI selection), classification (model matching), and tracking
- Experimental study: comparing state-of-the-art systems
- Experiments on a dataset captured onboard a vehicle driving through urban environment
- Results:
- HOG/linSVM at higher image resolutions and lower processing speeds
- Wavelet-based AdaBoost cascade approach at lower image resolutions and (near) real-time processing speeds
- Better performance for all by incorporating temporal integration and/or restrictions of the search space based on scene knowledge
| Semantic Segmentation Methods | |||
|
IV 2013
Erbs2013IV | |||
- Detection and tracking of moving traffic participants from a mobile platform using a stereo camera system
- Bayesian segmentation approach based on the Dynamic Stixel World
- In real-time using alpha-expansion multi-class graph cut optimization scheme
- Integrating 3D and motion features, spatio-temporal prior knowledge, and radar sensor in a CRF
- Evaluated quantitatively in various challenging traffic scenes
| Semantic Segmentation Methods | |||
|
BMVC 2012
Erbs2012BMVC | |||

- Detection of moving objects from a mobile platform
- Multi-class (street, obstacle, sky) traffic scene segmentation approach based on Dynamic Stixel World, an efficient super-pixel object representation
- Each stixel assigned to a quantized maneuver motion or to static background
- Using dense stereo depth maps obtained by SGM
- Conditional Random Field using 3D and motion features and spatio-temporal prior
- Real-time performance and evaluated in various challenging urban traffic scenes
| Object Tracking Methods | |||
|
PAMI 2009
Ess2009PAMI | |||
- Multi-person tracking in busy pedestrian zones using a stereo rig on a mobile platform
- Joint estimation of camera position, stereo depth, object detection, and tracking
- Object-object interactions and temporal links to past frames on a graphical model
- Two-step approach for intractable inference (approximate):
- First solve a simplified version to estimate the scene geometry and object detections per frame (without interactions and temporal continuity)
- Conditioned on these results, object interactions, tracking, and prediction
- Combining Belief Propagation and Quadratic Pseudo-Boolean Optimization
- Automatic failure detection and correction mechanisms
- Evaluated on challenging real-world data (over 5,000 video frame pairs)
- Robust multi-object tracking performance in very complex scenes
| Semantic Segmentation Methods | |||
|
BMVC 2009
Ess2009BMVC | |||

- Proposes a method to recognise the traffic scene in front of a moving vehicle with respect to the road topology and the existence of objects
- Contributions:
- Uses a two-stage system, where the first stage abstracts the image by a rough super-pixel segmentation of the scene
- Uses this meta representation in a second stage to construct features set for classifier that is able to distinguish between different road types as well as detect the existence of commonly encountered objects
- Shows that by relying on an intermediate stage, can effectively abstract from peculiarities of the underlying image data
- Evaluates on two urban data sets, covering day light and dusk conditions
| Mapping, Localization & Ego-Motion Estimation Mapping | |||
|
BMVC 2009
Ess2009BMVC | |||
- Proposes a method to recognise the traffic scene in front of a moving vehicle with respect to the road topology and the existence of objects
- Contributions:
- Uses a two-stage system, where the first stage abstracts the image by a rough super-pixel segmentation of the scene
- Uses this meta representation in a second stage to construct features set for classifier that is able to distinguish between different road types as well as detect the existence of commonly encountered objects
- Shows that by relying on an intermediate stage, can effectively abstract from peculiarities of the underlying image data
- Evaluates on two urban data sets, covering day light and dusk conditions
| Scene Understanding Methods | |||
|
BMVC 2009
Ess2009BMVC | |||
- Proposes a method to recognise the traffic scene in front of a moving vehicle with respect to the road topology and the existence of objects
- Contributions:
- Uses a two-stage system, where the first stage abstracts the image by a rough super-pixel segmentation of the scene
- Uses this meta representation in a second stage to construct features set for classifier that is able to distinguish between different road types as well as detect the existence of commonly encountered objects
- Shows that by relying on an intermediate stage, can effectively abstract from peculiarities of the underlying image data
- Evaluates on two urban data sets, covering day light and dusk conditions
| Scene Understanding Discussion | |||
|
BMVC 2009
Ess2009BMVC | |||
- Proposes a method to recognise the traffic scene in front of a moving vehicle with respect to the road topology and the existence of objects
- Contributions:
- Uses a two-stage system, where the first stage abstracts the image by a rough super-pixel segmentation of the scene
- Uses this meta representation in a second stage to construct features set for classifier that is able to distinguish between different road types as well as detect the existence of commonly encountered objects
- Shows that by relying on an intermediate stage, can effectively abstract from peculiarities of the underlying image data
- Evaluates on two urban data sets, covering day light and dusk conditions
| Datasets & Benchmarks | |||
|
IJCV 2010
Everingham2010IJCV | |||
- A benchmark with a standard dataset of images and annotation, and standard evaluation procedures
- Two principal challenges: classification and detection
- Two subsidiary challenges: pixel-level segmentation and person layout estimation
- Dataset: challenging images and high quality annotation, with a standard evaluation methodology
- Variability in object size, orientation, pose, illumination, position and occlusion
- No systematic bias for centred objects or good illumination
- Consistent, accurate, and exhaustive annotations for class, bounding box, viewpoint, truncation, and difficult
- Competition: measure the state of the art each year
| Datasets & Benchmarks Computer Vision Datasets | |||
|
IJCV 2010
Everingham2010IJCV | |||
- A benchmark with a standard dataset of images and annotation, and standard evaluation procedures
- Two principal challenges: classification and detection
- Two subsidiary challenges: pixel-level segmentation and person layout estimation
- Dataset: challenging images and high quality annotation, with a standard evaluation methodology
- Variability in object size, orientation, pose, illumination, position and occlusion
- No systematic bias for centred objects or good illumination
- Consistent, accurate, and exhaustive annotations for class, bounding box, viewpoint, truncation, and difficult
- Competition: measure the state of the art each year
| Object Detection Datasets | |||
|
IJCV 2010
Everingham2010IJCV | |||
- A benchmark with a standard dataset of images and annotation, and standard evaluation procedures
- Two principal challenges: classification and detection
- Two subsidiary challenges: pixel-level segmentation and person layout estimation
- Dataset: challenging images and high quality annotation, with a standard evaluation methodology
- Variability in object size, orientation, pose, illumination, position and occlusion
- No systematic bias for centred objects or good illumination
- Consistent, accurate, and exhaustive annotations for class, bounding box, viewpoint, truncation, and difficult
- Competition: measure the state of the art each year
| Object Detection Metrics | |||
|
IJCV 2010
Everingham2010IJCV | |||
- A benchmark with a standard dataset of images and annotation, and standard evaluation procedures
- Two principal challenges: classification and detection
- Two subsidiary challenges: pixel-level segmentation and person layout estimation
- Dataset: challenging images and high quality annotation, with a standard evaluation methodology
- Variability in object size, orientation, pose, illumination, position and occlusion
- No systematic bias for centred objects or good illumination
- Consistent, accurate, and exhaustive annotations for class, bounding box, viewpoint, truncation, and difficult
- Competition: measure the state of the art each year
| Semantic Segmentation Datasets | |||
|
IJCV 2010
Everingham2010IJCV | |||
- A benchmark with a standard dataset of images and annotation, and standard evaluation procedures
- Two principal challenges: classification and detection
- Two subsidiary challenges: pixel-level segmentation and person layout estimation
- Dataset: challenging images and high quality annotation, with a standard evaluation methodology
- Variability in object size, orientation, pose, illumination, position and occlusion
- No systematic bias for centred objects or good illumination
- Consistent, accurate, and exhaustive annotations for class, bounding box, viewpoint, truncation, and difficult
- Competition: measure the state of the art each year
| Semantic Instance Segmentation Datasets | |||
|
IJCV 2010
Everingham2010IJCV | |||
- A benchmark with a standard dataset of images and annotation, and standard evaluation procedures
- Two principal challenges: classification and detection
- Two subsidiary challenges: pixel-level segmentation and person layout estimation
- Dataset: challenging images and high quality annotation, with a standard evaluation methodology
- Variability in object size, orientation, pose, illumination, position and occlusion
- No systematic bias for centred objects or good illumination
- Consistent, accurate, and exhaustive annotations for class, bounding box, viewpoint, truncation, and difficult
- Competition: measure the state of the art each year
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
TIP 1998
Faugeras1998TIP | |||
- Stereo matching based on a variational principle
- Binocular stereo by considering objects as forming the graph of a smooth depth function
- A more general shape model by modeling objects as a set of general smooth surfaces in three space
- The EulerLagrange equations deduced from the variational principle
- A set of PDE's to deform an initial set of surfaces which then move toward the objects to be detected
- The level set implementation of these PDE's
- A simple matching criterion based on the difference of intensities
- A more sophisticated matching criterion by a measure of correlation
| Object Detection Methods | |||
|
CVPR 2008
Felzenszwalb2008CVPR | |||

- Discriminatively trained, multi-scale, deformable part model for object detection
- Combine a margin-sensitive approach for data mining hard negative examples
- Latent SVM, like a hidden CRF, leads to a non-convex training problem
- Problem becomes convex once latent information is specified for the positive examples
- Training method will eventually allow the effective use of more latent information such as hierarchical (grammar) models
- Two-fold improvement in average precision over the previous best in the 2006 PASCAL person detection challenge
| Object Tracking Datasets | |||
|
CVPR 2008
Felzenszwalb2008CVPR | |||
- Discriminatively trained, multi-scale, deformable part model for object detection
- Combine a margin-sensitive approach for data mining hard negative examples
- Latent SVM, like a hidden CRF, leads to a non-convex training problem
- Problem becomes convex once latent information is specified for the positive examples
- Training method will eventually allow the effective use of more latent information such as hierarchical (grammar) models
- Two-fold improvement in average precision over the previous best in the 2006 PASCAL person detection challenge
| Semantic Segmentation Methods | |||
|
CVPR 2012
Floros2012CVPR | |||
- Proposes a novel Conditional Random Field (CRF) formulation for the semantic scene labeling problem which is able to enforce temporal consistency between consecutive video frames and take advantage of the 3D scene geometry to improve segmentation quality
- Uses 3D scene reconstruction as a means to temporally couple the individual image segmentations, allowing information flow from 3D geometry to the 2D image space
- Details:
- Optimizes the semantic labels in a temporal window around the image we are interested in
- Augments the higher-order cliques of the CRF with the sets of pixels that are projections of the same 3D point in different images
- Since these new higher-order cliques contain different projections of the same 3D point, the labels of the pixels inside the clique should be consistent
- Forms a grouping constraint on these pixels
- Evaluates on Leuven and City stereo dataset
| Multi-view 3D Reconstruction Problem Definition | |||
|
IJCV 2005
Frueh2005IJCV | |||
- Generating textured facade meshes of cities from a series of vertical 2D surface scans and camera images
- Set of data processing algorithms that cope with imperfections and non-idealities
- Data is divided into easy-to-handle quasi linear segments and sequential topological order of scans
- Depth images are obtained by transforming the divided segments and used to detect Dominant building structures
- Large holes are filled by planar, horizontal interpolation for the background and horizontal, vertical interpolation or by copy-paste methods for foreground objects
- Demonstrated on a large set of data of downtown Berkeley
| Mapping, Localization & Ego-Motion Estimation Mapping | |||
|
IJCV 2005
Frueh2005IJCV | |||
- Generating textured facade meshes of cities from a series of vertical 2D surface scans and camera images
- Set of data processing algorithms that cope with imperfections and non-idealities
- Data is divided into easy-to-handle quasi linear segments and sequential topological order of scans
- Depth images are obtained by transforming the divided segments and used to detect Dominant building structures
- Large holes are filled by planar, horizontal interpolation for the background and horizontal, vertical interpolation or by copy-paste methods for foreground objects
- Demonstrated on a large set of data of downtown Berkeley
| Multi-view 3D Reconstruction Structure from Motion | |||
|
ECCV 2010
Frahm2010ECCV | |||

- Dense 3D reconstruction from unregistered Internet-scale photo collections
- 3 million images within a day on a single PC
- Geometric and appearance constraints to obtain a highly parallel implementation
- Extension of appearance-based clustering 1 and stereo fusion 2
- Geometric cluster verification using a fast RANSAC method
- Local iconic scene graph reconstruction and dense model computation using views obtained from iconic scene graph
- Two orders of magnitude higher performance on an order of magnitude larger dataset than state-of-the-art
1. Li, X., Wu, C., Zach, C., Lazebnik, S., Frahm, J.M.: Modeling and recognition of landmark image collections using iconic scene graphs. In: ECCV. (2008)
2. Gallup, D., Pollefeys, M., Frahm, J.M.: 3d reconstruction using an n-layer heightmap. In: DAGM (2010)
| History of Autonomous Driving | |||
|
IS 1998
Franke1998IS | |||

- Discussion of new algorithmic and system-architecture challenges posed when developing autonomous or driver assistance systems for complex urban traffic
- Introduction of the Intelligent Stop&Go System
- Stereo-based obstacle detection and tracking recognizes the road, traffic signs and pedestrians
- Road detection by analyzing the polygonal contour images
- Gray-value segmentation and classification using RBF for arrow recognition
- Color segmentation, filtering and classification is used for Traffic sign and Traffic light recognition
- Pedestrian recognition by either their shape or their characteristic walking patterns
| History of Autonomous Driving | |||
|
IV 1994
Franke1994IV | |||
- Development of the Daimler-Benz Steering Assistant based on the experience gained during 3000 km of autonomous driving on public highways
- System supports the driver in keeping his lateral position on the lane while remaining in full control of the vehicle
- Reduction of the driver's steering task to global positioning
- Steering angle commanded by the driver is slightly modified by adding a correcting value via a small actuator
- Hard- and software of the controllers action guarantees safety
- Image processing is used to obtain the needed vehicle position and orientation
- Quickly accepted by test drivers
| 3D Scene Flow Problem Definition | |||
|
DAGM 2005
Franke2005DAGM | |||

- Obstacle avoidance in mobile robotics needs a robust perception of the environment
- Simultaneous estimation of depth and motion for image sequences
- 3D position and 3D motion are estimated with Kalman-Filters
- Ego-motion is assumed to be known (they use inertial sensors)
- 2000 points are tracked with KLT tracker
- Multiple filters with different initializations improve the convergence rate
- Only qualitative results
- Runs in real-time
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
ITSC 2013
Fritsch2013ITSC | |||
- Open-access dataset and benchmark for road area and ego-lane detection
- Motivation: finding the boundaries of unmarked or weakly marked roads and lanes as they appear in inner-city and rural environments
- 600 annotated training and test images of high variability from three challenging real-world city road types derived from the KITTI dataset
- Evaluation using 2D Birds Eye View (BEV) space
- Behavior-based metric by fitting a driving corridor to road detection results in the BEV
- Comparison of state-of-the-art road detection algorithms using classical pixel-level metrics in perspective and BEV space as well as the novel behavior-based performance measure
| History of Autonomous Driving | |||
|
IV 2013
Furgale2013IV | |||
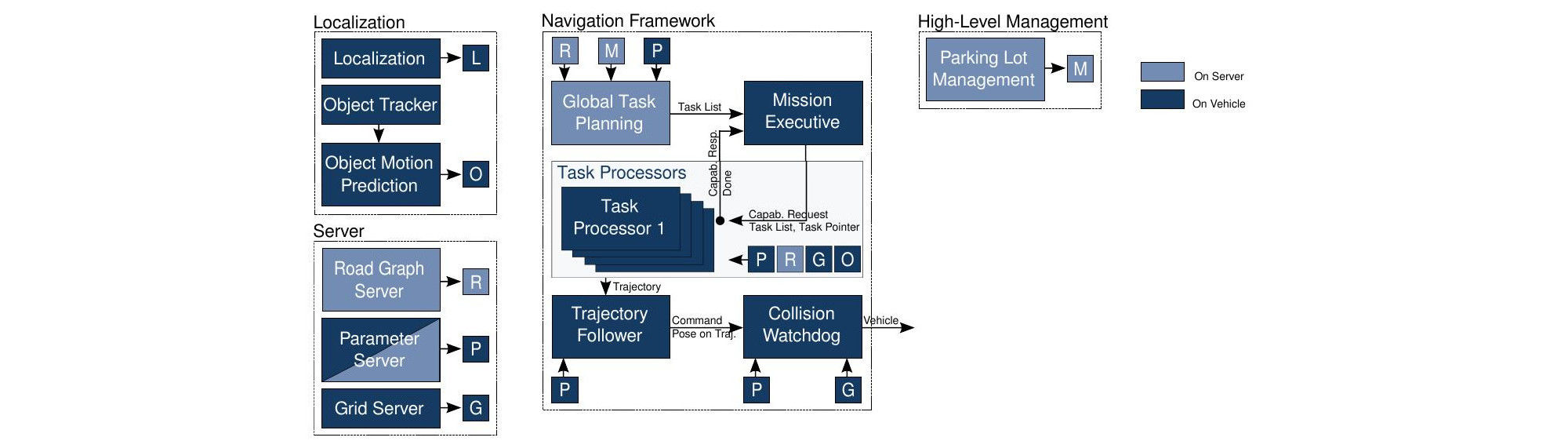
- Electric automated car outfitted with close-to-market sensors
- Fully operational system including automated navigation and parking
- Dense map obtained from motion stereo and a volumetric grid
- Sparse map is built from state-of-the-art SLAM
- Road network represented by RoadGraph, a directed graph of connected lanes, parking lots and other semantic annotations
- Localization by extensive data association between sparse map and observed frame
- Situational awareness with a robust and accurate scene reconstruction using dense stereo, object detection and tracking, and map fusion
- Path planing and motion control with a hierarchical approach consisting of a mission planer, specific processors for onlane driving and parking maneuvers and a motion control module
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
PAMI 2010
Furukawa2010PAMI | |||

- A patch-based multi-view stereo (PMVS) algorithm
- Match, expand, and filter procedure:
- Initial sparse matches: features by Harris and difference-of-Gaussians operators across multiple pictures
- Expansion: to spread the initial matches to nearby pixels and obtain a dense set of patches
- Filtering: visibility (and a weak form of regularization) constraints to eliminate incorrect matches
- Converting resulting patch model into a mesh using a polygonal mesh-based refinement algorithm
- Handling images of objects, scenes and crowded scenes
- Evaluated on Middlebury benchmark
| Multi-view 3D Reconstruction Discussion | |||
|
PAMI 2010
Furukawa2010PAMI | |||
- A patch-based multi-view stereo (PMVS) algorithm
- Match, expand, and filter procedure:
- Initial sparse matches: features by Harris and difference-of-Gaussians operators across multiple pictures
- Expansion: to spread the initial matches to nearby pixels and obtain a dense set of patches
- Filtering: visibility (and a weak form of regularization) constraints to eliminate incorrect matches
- Converting resulting patch model into a mesh using a polygonal mesh-based refinement algorithm
- Handling images of objects, scenes and crowded scenes
- Evaluated on Middlebury benchmark
| Semantic Segmentation Methods | |||
|
ECCV 2012
Guenyel2012ECCV | |||

- Traditionally, motion estimation between two frames is done using optical flow methods, which are computationally expensive
- Contributions:
- Proposes the first algorithm for stixels motion estimation without requiring the computation of optical flow. This enables much faster computation while keeping good quality
- The stixel motion can be viewed as a matching problem between stixels in 2 frames
- Computes matching cost matrix. Optimal motion assignment for each stixel can be solved via dynamic programming
- Presents the first evaluation of the stixels motion quality by comparing against two baselines
- Evaluates on the ``Bahnhof" sequence
| Semantic Segmentation Methods | |||
|
ECCV 2016
Gadde2016ECCV | |||
- Adding bilateral filtering to CNNs for semantic segmentation: "Bilateral Inception" (BI)
- Idea: Pixels that are spatially and photometrically similar are more likely to have the same label.
- End-to-end learning of feature spaces for bilateral filtering and other parameters
- Standard bilateral filters with Gaussian kernels, at different feature scales
- Information propagation between (super) pixels while respecting image edges
- Full resolution segmentation result from the lower resolution solution of a CNN
- Inserting BI into several existing CNN architectures before/after the last 1 times 1 convolution (FC) layers
- Improved results on Pascal VOC12, Materials in Context, and Cityscapes datasets
- Better and faster than DenseCRF
| Datasets & Benchmarks | |||
|
CVPR 2016
Gaidon2016CVPR | |||

- Modern CV algorithms rely on expensive data acquisition and manual labeling
- Generation of fully labeled, dynamic and photo-realistic proxy virtual worlds
- Allow to change conditions of the proxy world and to study rare events or difficult to observe conditions that might occur in practice (what-if analysis)
- Efficient real-to-virtual world cloning method validated by creating a dataset called Virtual KITTI
- Accurate ground truth for object detection, tracking, scene and instance segmentation, depth and optical flow
- Gap in performance between leaning from real and virtual KITTI is small
- Pre-training with Virtual KITTI and final training with KITTI gave best results (virtual data augmentation)
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
CVPR 2016
Gaidon2016CVPR | |||
- Modern CV algorithms rely on expensive data acquisition and manual labeling
- Generation of fully labeled, dynamic and photo-realistic proxy virtual worlds
- Allow to change conditions of the proxy world and to study rare events or difficult to observe conditions that might occur in practice (what-if analysis)
- Efficient real-to-virtual world cloning method validated by creating a dataset called Virtual KITTI
- Accurate ground truth for object detection, tracking, scene and instance segmentation, depth and optical flow
- Gap in performance between leaning from real and virtual KITTI is small
- Pre-training with Virtual KITTI and final training with KITTI gave best results (virtual data augmentation)
| Datasets & Benchmarks Synthetic Data Generation using Game Engines | |||
|
CVPR 2016
Gaidon2016CVPR | |||
- Modern CV algorithms rely on expensive data acquisition and manual labeling
- Generation of fully labeled, dynamic and photo-realistic proxy virtual worlds
- Allow to change conditions of the proxy world and to study rare events or difficult to observe conditions that might occur in practice (what-if analysis)
- Efficient real-to-virtual world cloning method validated by creating a dataset called Virtual KITTI
- Accurate ground truth for object detection, tracking, scene and instance segmentation, depth and optical flow
- Gap in performance between leaning from real and virtual KITTI is small
- Pre-training with Virtual KITTI and final training with KITTI gave best results (virtual data augmentation)
| Stereo Datasets | |||
|
CVPR 2016
Gaidon2016CVPR | |||
- Modern CV algorithms rely on expensive data acquisition and manual labeling
- Generation of fully labeled, dynamic and photo-realistic proxy virtual worlds
- Allow to change conditions of the proxy world and to study rare events or difficult to observe conditions that might occur in practice (what-if analysis)
- Efficient real-to-virtual world cloning method validated by creating a dataset called Virtual KITTI
- Accurate ground truth for object detection, tracking, scene and instance segmentation, depth and optical flow
- Gap in performance between leaning from real and virtual KITTI is small
- Pre-training with Virtual KITTI and final training with KITTI gave best results (virtual data augmentation)
| Stereo Methods | |||
|
CVPR 2008
Gallup2008CVPR | |||
- Presents a novel multi-baseline, multi-resolution stereo method, which varies the baseline and resolution proportionally to depth to obtain a reconstruction in which the depth error is constant
- In contrast to traditional stereo, in which the error grows quadratically with depth, which means that the accuracy in the near range far exceeds that of the far range
- By selecting an appropriate baseline and resolution (image pyramid), the algorithm computes a depthmap which has these properties:
- the depth accuracy is constant over the reconstructed volume, by increasing the baseline to increase accuracy in the far range
- the computational effort is spread evenly over the volume by reducing the resolution in the near range
- the angle of triangulation is held constant w.r.t. depth
- Evaluates on self-recorded dataset
| Stereo Methods | |||
|
CVPR 2010
Gallup2010CVPR | |||
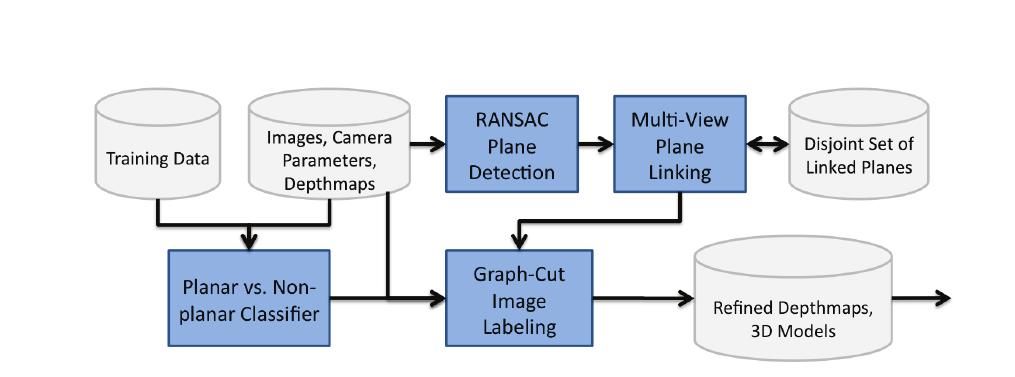
- Depth estimation in indoor and urban outdoor scenes
- Planarity assumptions are problematic in presence of non-planar objects
- Stereo method capable of handling more general scenes containing planar and non-planar regions
- Segmentation by multi-view photoconsistency and color-/texture-based classifier into piecewise planar and non-planar regions
- Standard multi-view stereo used to model non-planar regions
- Fusion of plane hypotheses across multiple overlapping views ensure consistent 3D reconstruction
- Tested with street-side sequences captured by two vehicle-mounted color-cameras
| Object Tracking Methods | |||
|
IJCV 2007
Gavrila2007IJCV | |||
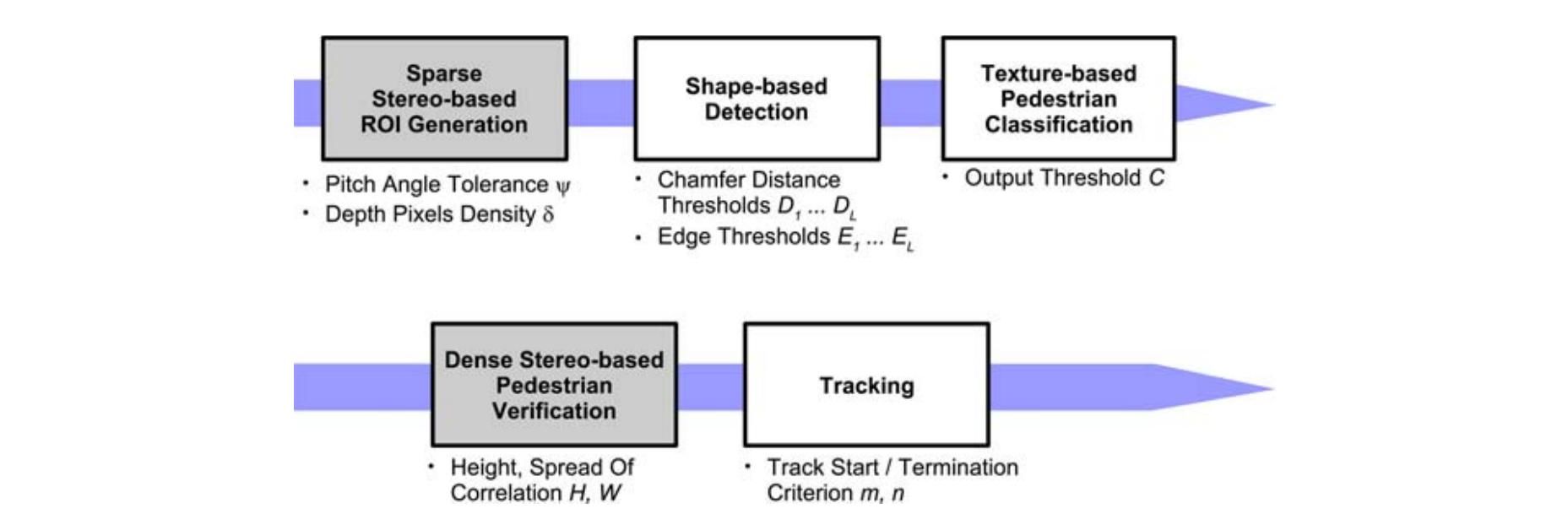
- Mutli-cue system for real-time detection and tracking of pedestrians from a moving vehicle
- Cascade of modules utilizing complementary visual criteria to narrow down the search space
- Integration of sparse stereo-based ROI generation, shape-based detection, texture-based classification and dense stereo-based verification
- Mixture-of-experts involving texture-based component classifiers weighted by the outcome of shape matching
- alpha-beta tracker using the Hungarian method for data association
- Analysis of the performance and interaction of the individual modules
- Evaluation in difficult urban traffic conditions
| Stereo Methods | |||
|
ICVS 2009
Gehrig2009ICVS | |||
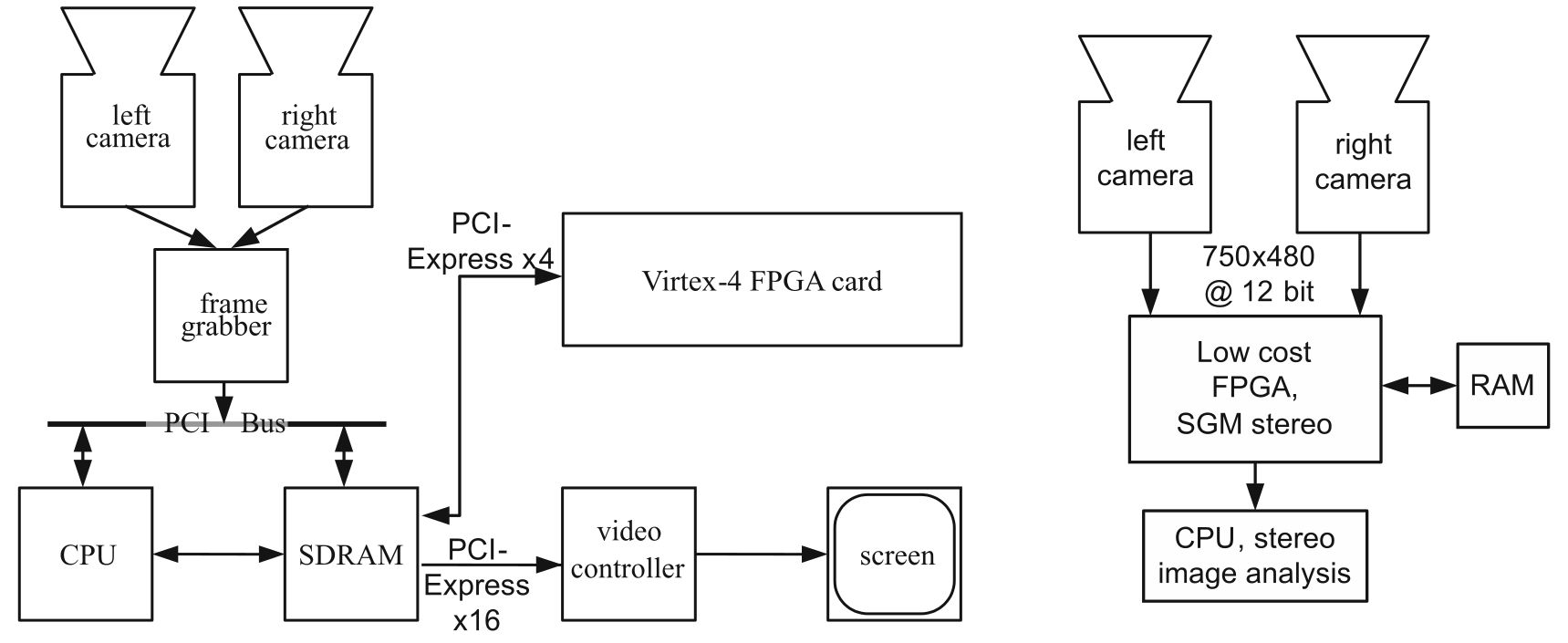
- Low-power implementations of real-time stereo vision systems not available in existing literature
- Contributions:
- Introduces a real-time low-power global stereo engine based on semi-global matching (SGM)
- Achieves real time performance by parallelization of the path calculator block and subsampling of the images
- Evaluates on Middlebury database
| Mapping, Localization & Ego-Motion Estimation Mapping | |||
|
IV 2009
Geiger2009IV | |||

- Marking-based lane recognition require unobstructed view onto the road which usually is not possible due to traffic
- Multi-stage registration procedure for road mosaicing in dynamic environments
- Approximating the road surface by a plane allows to use homographies for the mapping from one image to another
- Picking a subset as keyframes to reduce error accumulation and save computational power
- Road segmentation using optical flow on Harris corners
- Combine road images using multi-band blending to remove artificial edges
| History of Autonomous Driving | |||
|
TITS 2012
Geiger2012TITS | |||
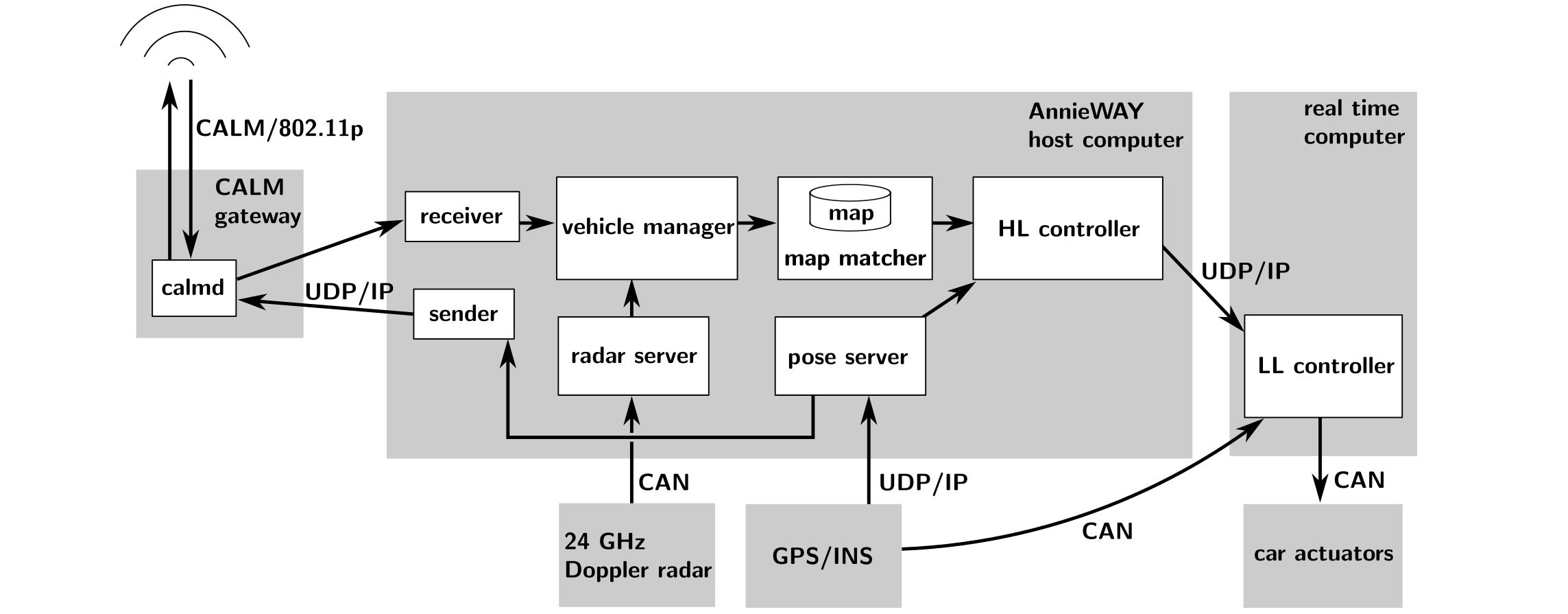
- Presents the concepts and methods developed for the autonomous vehicle AnnieWAY, winning entry to the Grand Cooperative Driving Challenge of 2011
- Goal of cooperative driving is to improve traffic homogeneity using vehicle-to-vehicle communication to provide the vehicle with information about the current traffic situation
- Contributions:
- Describes algorithms used for sensor fusion, vehicle-to-vehicle communication and cooperative control
- Analyzes the performance of the proposed methods and compare them to those of competing teams
| Semantic Segmentation Methods | |||
|
PAMI 2014
Geiger2014PAMI | |||
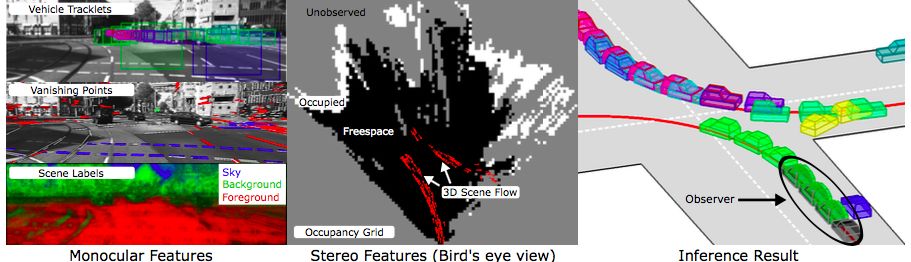
- Presents a probabilistic generative model for multi-object traffic scene understanding from movable platforms
- Reasons jointly about the 3D scene layout as well as the location and orientation of objects in the scene
- Contributions:
- Estimates the layout of urban intersections based on onboard stereo imagery alone
- Does not rely on strong prior knowledge such as intersection maps
- Infers all information from different types of visual features that describe the static environment of the crossroads & the motions of objects in the scene
- Evaluates on dataset of 113 video sequences of real traffic
| Scene Understanding Methods | |||
|
PAMI 2014
Geiger2014PAMI | |||
- Presents a probabilistic generative model for multi-object traffic scene understanding from movable platforms
- Reasons jointly about the 3D scene layout as well as the location and orientation of objects in the scene
- Contributions:
- Estimates the layout of urban intersections based on onboard stereo imagery alone
- Does not rely on strong prior knowledge such as intersection maps
- Infers all information from different types of visual features that describe the static environment of the crossroads & the motions of objects in the scene
- Evaluates on dataset of 113 video sequences of real traffic
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
IJRR 2013
Geiger2013IJRR | |||

- Present a novel dataset captured from a VW station wagon for use in mobile robotics and autonomous driving research.
- In total, the dataset contains 6 hours of traffic scenarios at 10-100 Hz using a variety of sensor modalities such as highresolution color and grayscale stereo cameras, a Velodyne 3D laser scanner and a high-precision GPS/IMU inertial navigation system.
- The scenarios are diverse, capturing real-world traffic situations and range from freeways over rural areas to innercity scenes with many static and dynamic objects.
- Data is calibrated, synchronized and timestamped & provide the rectified and raw image sequences.
- Dataset also contains object labels in the form of 3D tracklets & provide online benchmarks for stereo, optical flow, object detection and other tasks.
- This paper describes the recording platform, the data format and the utilities that we provide.
| Semantic Segmentation Methods | |||
|
IJRR 2013
Geiger2013IJRR | |||
- Present a novel dataset captured from a VW station wagon for use in mobile robotics and autonomous driving research.
- In total, the dataset contains 6 hours of traffic scenarios at 10-100 Hz using a variety of sensor modalities such as highresolution color and grayscale stereo cameras, a Velodyne 3D laser scanner and a high-precision GPS/IMU inertial navigation system.
- The scenarios are diverse, capturing real-world traffic situations and range from freeways over rural areas to innercity scenes with many static and dynamic objects.
- Data is calibrated, synchronized and timestamped & provide the rectified and raw image sequences.
- Dataset also contains object labels in the form of 3D tracklets & provide online benchmarks for stereo, optical flow, object detection and other tasks.
- This paper describes the recording platform, the data format and the utilities that we provide.
| Semantic Segmentation Datasets | |||
|
IJRR 2013
Geiger2013IJRR | |||
- Present a novel dataset captured from a VW station wagon for use in mobile robotics and autonomous driving research.
- In total, the dataset contains 6 hours of traffic scenarios at 10-100 Hz using a variety of sensor modalities such as highresolution color and grayscale stereo cameras, a Velodyne 3D laser scanner and a high-precision GPS/IMU inertial navigation system.
- The scenarios are diverse, capturing real-world traffic situations and range from freeways over rural areas to innercity scenes with many static and dynamic objects.
- Data is calibrated, synchronized and timestamped & provide the rectified and raw image sequences.
- Dataset also contains object labels in the form of 3D tracklets & provide online benchmarks for stereo, optical flow, object detection and other tasks.
- This paper describes the recording platform, the data format and the utilities that we provide.
| History of Autonomous Driving | |||
|
CVPR 2012
Geiger2012CVPR | |||
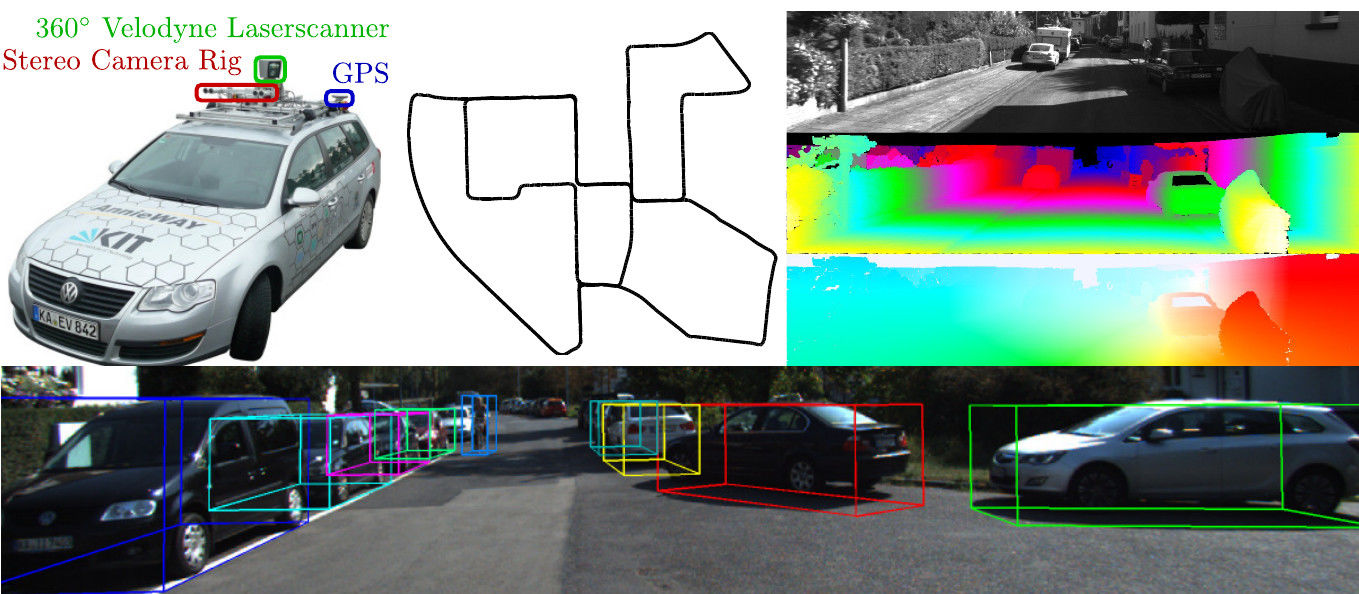
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Datasets & Benchmarks | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Datasets & Benchmarks Computer Vision Datasets | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Object Detection Datasets | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Object Detection Metrics | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Object Detection State of the Art on KITTI | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Object Tracking Methods | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Object Tracking Datasets | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Object Tracking Metrics | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Semantic Instance Segmentation Datasets | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Stereo Problem Definition | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Stereo Methods | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Stereo Datasets | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Stereo Discussion | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Optical Flow Methods | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Optical Flow Datasets | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| 3D Scene Flow Datasets | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Mapping, Localization & Ego-Motion Estimation Datasets | |||
|
CVPR 2012
Geiger2012CVPR | |||
- Autonomous driving platform equipped with video cameras, Velodyne scanner & GPS
- Goal: provide novel benchmarks for several tasks
- Stereo & optical flow: 389 image pairs
- Stereo visual odometry: sequences of 39.2 km total length
- 2D & 3D object detection: vehicles, pedestrians, cyclists (>200k annotations)
- Online evaluation server (held-out test ground truth)
- Conclusions: novel challenges and ranking compared to lab conditions (eg, Middlebury)
| Sensors Calibration | |||
|
ICRA 2012
Geiger2012ICRA | |||

- Set up of calibrated systems heavily delay robotic research
- Toolbox with web interface for fully automatic camera-to-camera and camera-to-range calibration using plane checkerboard patterns
- Recovers intrinsic and extrinsic camera parameters as well as transformation between cameras and range sensors within one minute
- Checkerboard corner detector significantly outperforms state-of-the-art
- Validation using a variety of sensors such as cameras, Kinect, and Velodyne laser scanner
| Stereo Methods | |||
|
ACCV 2010
Geiger2010ACCV | |||
- Fast stereo matching for high-resolution images
- Efficient, parallel algorithm in a reduced search space
- Building a prior on the disparities
- Robustly matched points used to form a triangulation (support points)
- Reducing the matching ambiguities of the remaining points
- Piecewise linear: robust to poorly-textured and slanted surfaces
- Automatic detection of disparity range
- Significantly lower matching entropy compared to using a uniform prior
- 1 sec for a 1 Megapixel image pair on a single CPU
- State-of-the-art with significant speed-ups on large-scale Middlebury benchmark
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
ACCV 2010
Geiger2010ACCV | |||
- Fast stereo matching for high-resolution images
- Efficient, parallel algorithm in a reduced search space
- Building a prior on the disparities
- Robustly matched points used to form a triangulation (support points)
- Reducing the matching ambiguities of the remaining points
- Piecewise linear: robust to poorly-textured and slanted surfaces
- Automatic detection of disparity range
- Significantly lower matching entropy compared to using a uniform prior
- 1 sec for a 1 Megapixel image pair on a single CPU
- State-of-the-art with significant speed-ups on large-scale Middlebury benchmark
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
IV 2011
Geiger2011IV | |||

- Real-time 3D reconstruction from high-resolution stereo sequences using visual odometry
- Sparse feature matching using blob, corner detector and descriptors
- Egomotion estimation by minimizing the reprojection error and refining with Kalman filter
- Dense 3D reconstruction by projecting image points into 3D and associating the projected points
- Visual odometry runs at 25fps and 3D reconstruction at 3-4fps
- Evaluation on the Karlsruhe dataset to GPS+IMU data and a freely available visual odometry library
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
IV 2011
Geiger2011IV | |||
- Real-time 3D reconstruction from high-resolution stereo sequences using visual odometry
- Sparse feature matching using blob, corner detector and descriptors
- Egomotion estimation by minimizing the reprojection error and refining with Kalman filter
- Dense 3D reconstruction by projecting image points into 3D and associating the projected points
- Visual odometry runs at 25fps and 3D reconstruction at 3-4fps
- Evaluation on the Karlsruhe dataset to GPS+IMU data and a freely available visual odometry library
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
IV 2011
Geiger2011IV | |||
- Real-time 3D reconstruction from high-resolution stereo sequences using visual odometry
- Sparse feature matching using blob, corner detector and descriptors
- Egomotion estimation by minimizing the reprojection error and refining with Kalman filter
- Dense 3D reconstruction by projecting image points into 3D and associating the projected points
- Visual odometry runs at 25fps and 3D reconstruction at 3-4fps
- Evaluation on the Karlsruhe dataset to GPS+IMU data and a freely available visual odometry library
| Object Detection Problem Definition | |||
|
PAMI 2010
Geronimo2010PAMI | |||
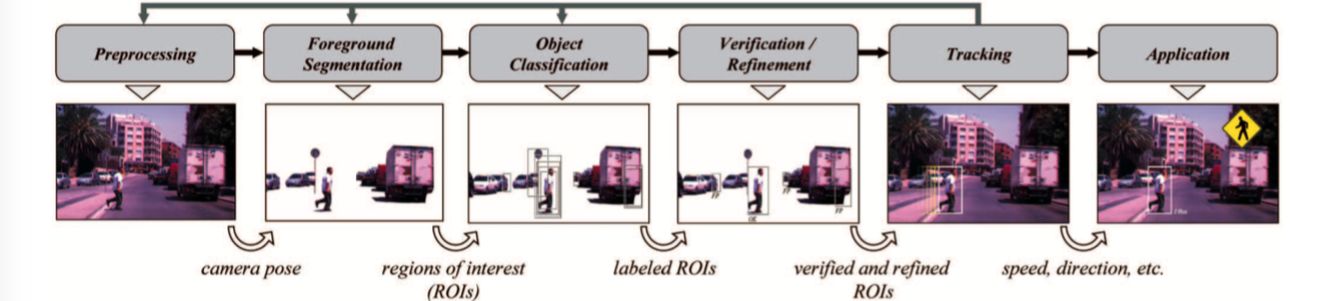
- In this paper, the focus is on a particular type of ADAS, pedestrian protection systems (PPSs).
- The objective of a PPS is to detect the presence of both stationary and moving people in a specific area of interest around the moving host vehicle in order to warn the driver
- Presents a general module-based architecture that simplifies the comparison of specific detection tasks
- Provides a comprehensive up- to-date review of state-of-the-art sensors and benchmarking
- Reviews different approaches according to the specific tasks defined in the aforementioned architecture
- Major progress has been made in pedestrian classification, mainly due to synergy with generic object detection and applications such as face detection and surveillance
| Sensors Camera Models | |||
|
ECCV 2000
Geyer2000ECCV | |||
- Provides a unifying theory for all central catadioptric systems, that means for all catadioptric systems with a unique effective viewpoint
- Shows that all of them are isomorphic to projective mappings from the sphere to a plane with a projection center on the perpendicular to the plane
- This unification is novel & has significant impact on the 3D interpretation of images
- Presents new invariances inherent in parabolic projections and a unifying calibration scheme from one view
- Describes the advantages of catadioptric systems & explain why images arising in central catadioptric systems contain more information than images from conventional cameras
- One example is that intrinsic calibration from a single view is possible for parabolic catadioptric systems given only three lines
| Stereo Methods | |||
|
ECCV 2000
Geyer2000ECCV | |||
- Provides a unifying theory for all central catadioptric systems, that means for all catadioptric systems with a unique effective viewpoint
- Shows that all of them are isomorphic to projective mappings from the sphere to a plane with a projection center on the perpendicular to the plane
- This unification is novel & has significant impact on the 3D interpretation of images
- Presents new invariances inherent in parabolic projections and a unifying calibration scheme from one view
- Describes the advantages of catadioptric systems & explain why images arising in central catadioptric systems contain more information than images from conventional cameras
- One example is that intrinsic calibration from a single view is possible for parabolic catadioptric systems given only three lines
| Semantic Segmentation Methods | |||
|
ECCV 2016
Ghiasi2016ECCV | |||
- A multi-resolution reconstruction (from low to full resolution) architecture for semantic segmentation
- Significant sub-pixel localization information in high-dimensional features
- Sub-pixel up-sampling using a class-specific reconstruction basis
- Substantially improves over common up-sampling schemes
- Laplacian pyramid using skip connections from higher resolution feature maps
- Reducing the effect of shallow, high-resolution layers by using them only to correct residual errors in the low-resolution prediction (like ResNets)
- Multiplicative gating to avoid integrating noisy high-resolution outputs
- State-of-the-art results on the PASCAL VOC and Cityscapes benchmarks
| Object Tracking Methods | |||
|
ECCV 2004
Giebel2004ECCV | |||
- Multi-cue 3D deformable object tracking from a moving vehicle
- Spatio-temporal shape representation by a set of distinct linear subspace models Dynamic Point Distribution Models (DPDMs)
- Continuous and discontinuous appearance changes
- Learned fully automatically from training data
- Texture information by means of intensity histograms , compared using the Bhattacharyya coefficient
- Direct 3D measurement by a stereo system
- State propagation by a particle filter combining shape, texture and depth in its observation density function
- Measurements from an independent object detection by means of importance sampling
- Evaluated in urban, rural, and synthetic environments
| Object Detection Methods | |||
|
CVPR 2014
Girshick2014CVPR | |||
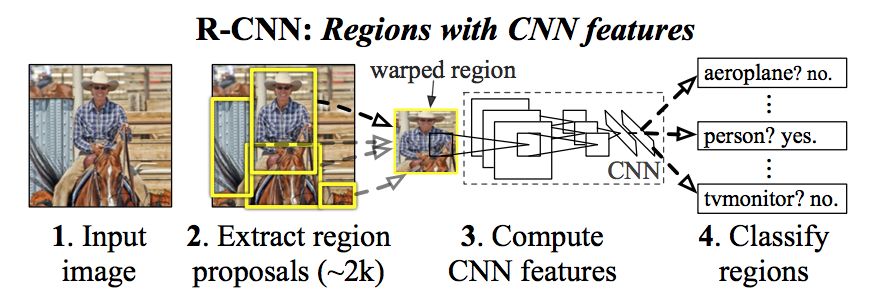
- Object detection using features computed by a large CNN
- Recognition using regions instead of computationally expensive sliding window approach resulting in two orders of magnitude fewer image windows
- Generating bottom-up region proposals: R-CNN: Regions with CNN features
- A fixed-length feature vector for each proposal, shared across all categories and appearance modes
- Fitting SVMs to ConvNet features as object detectors
- The same framework also for semantic segmentation
- Evaluated on PASCAL VOC detection and segmentation challenges.
- More investigations on the architecture:
- Removing 94 of parameters with only a moderate drop in accuracy.
- Removing color degrades performance only marginally.
| Object Detection State of the Art on KITTI | |||
|
CVPR 2014
Girshick2014CVPR | |||
- Object detection using features computed by a large CNN
- Recognition using regions instead of computationally expensive sliding window approach resulting in two orders of magnitude fewer image windows
- Generating bottom-up region proposals: R-CNN: Regions with CNN features
- A fixed-length feature vector for each proposal, shared across all categories and appearance modes
- Fitting SVMs to ConvNet features as object detectors
- The same framework also for semantic segmentation
- Evaluated on PASCAL VOC detection and segmentation challenges.
- More investigations on the architecture:
- Removing 94 of parameters with only a moderate drop in accuracy.
- Removing color degrades performance only marginally.
| Object Detection Methods | |||
|
ICCV 2015
Girshick2015ICCV | |||
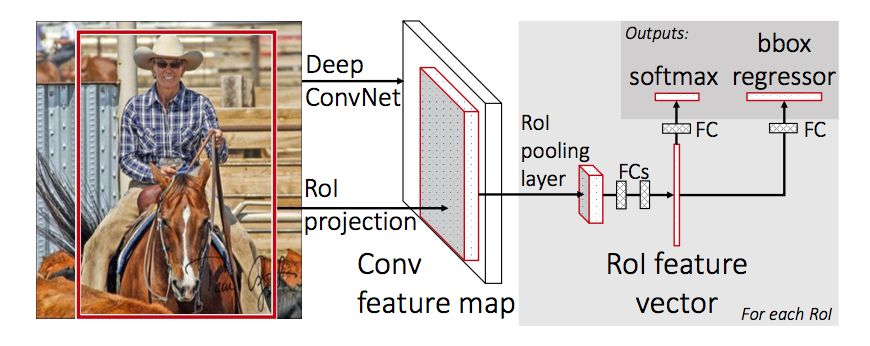
- Fast Region-based Convolutional Network method (Fast R-CNN) for object detection
- Previous approaches with high complexity due to multi-stage approach:
- localization, ie creating region proposals
- refinement for precise localization
- high storage requirements due to feature caching
- In R-CNN, a forward pass for each object proposal, without sharing computation
- Proposed: a single-stage training algorithm using a multi-task loss ie jointly learning to classify object proposals and refine their spatial locations
- Training VGG16 9times faster than R-CNN, 213times faster for test-time
- Achieving a higher accuracy on PASCAL VOC 2012
| Object Detection State of the Art on KITTI | |||
|
ICCV 2015
Girshick2015ICCV | |||
- Fast Region-based Convolutional Network method (Fast R-CNN) for object detection
- Previous approaches with high complexity due to multi-stage approach:
- localization, ie creating region proposals
- refinement for precise localization
- high storage requirements due to feature caching
- In R-CNN, a forward pass for each object proposal, without sharing computation
- Proposed: a single-stage training algorithm using a multi-task loss ie jointly learning to classify object proposals and refine their spatial locations
- Training VGG16 9times faster than R-CNN, 213times faster for test-time
- Achieving a higher accuracy on PASCAL VOC 2012
| Object Detection Problem Definition | |||
|
On-Board Object Detection: Multicue, Multimodal, and Multiview Random Forest of Local Experts[scholar]
|
TCYB 2016
Gonzalez2016TCYB | ||
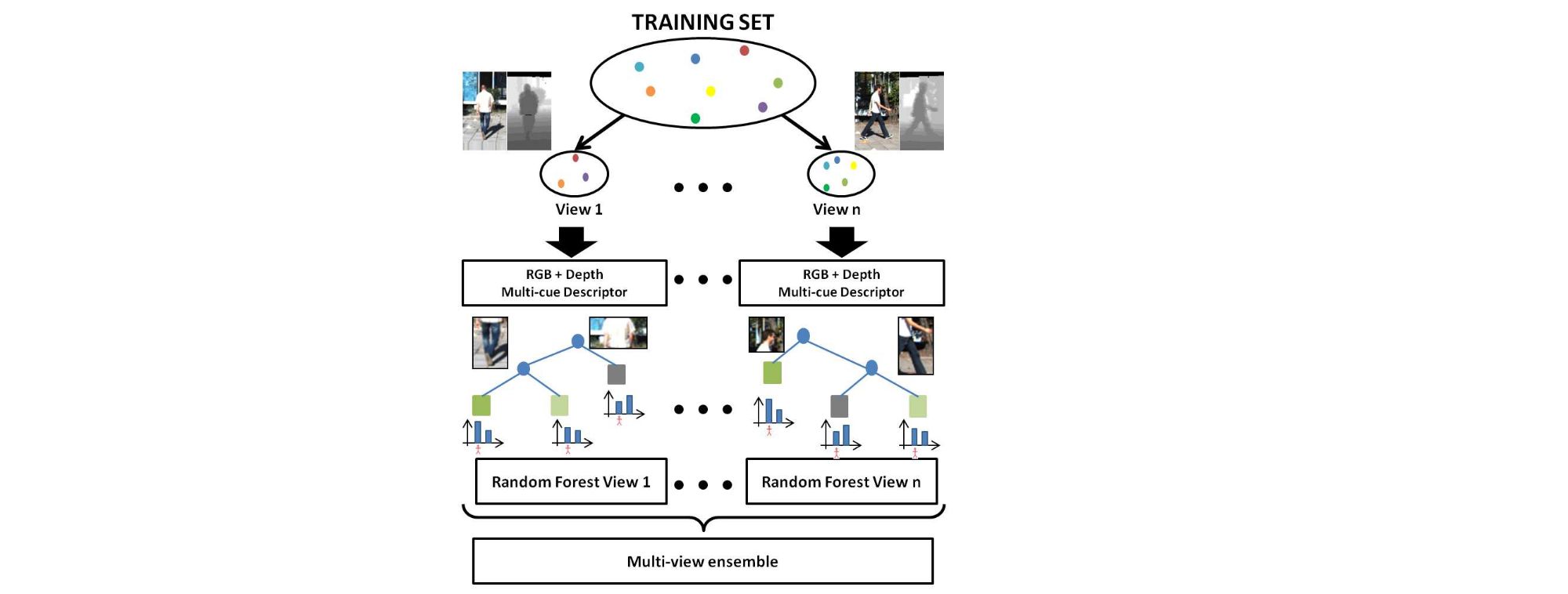
- Extensive evaluation of object detection system
- Considering the aspects multiple cues, multiple imaging modalities and a strong multi-view classifier
- How does each of these aspects affect accuracy individually and when integrated together
- Fusion of RGB and depth obtained from LIDAR is explored in the multi-modality component
- Analysis reveals that all of the aspects are important but the fusion of visible spectrum and depth is particularly boosting the performance
- Resulting detector ranks among the top best on KITTI benchmark during that time
| History of Autonomous Driving | |||
|
ICRA 2015
Grimmett2015ICRA | |||
- Creating metric maps and semantic maps
- Missing in the literature: how to update the semantic layer as the metric map evolves
- Unsupervised evolution of both maps as the environment is revisited by the robot
- Distinguishing between static and dynamic maps
- Using vision-only sensors and reduced human labelling of semantic maps in case of safety-critical situations
- Automatically generating road network graphs
- Evaluated on two different car parks with a fully automated car, performing repeated automated parking manoeuvres (V-Charge project)
| Mapping, Localization & Ego-Motion Estimation Mapping | |||
|
ICRA 2015
Grimmett2015ICRA | |||
- Creating metric maps and semantic maps
- Missing in the literature: how to update the semantic layer as the metric map evolves
- Unsupervised evolution of both maps as the environment is revisited by the robot
- Distinguishing between static and dynamic maps
- Using vision-only sensors and reduced human labelling of semantic maps in case of safety-critical situations
- Automatically generating road network graphs
- Evaluated on two different car parks with a fully automated car, performing repeated automated parking manoeuvres (V-Charge project)
| History of Autonomous Driving | |||
|
IFAC 2010
Grisleri2010IFAC | |||
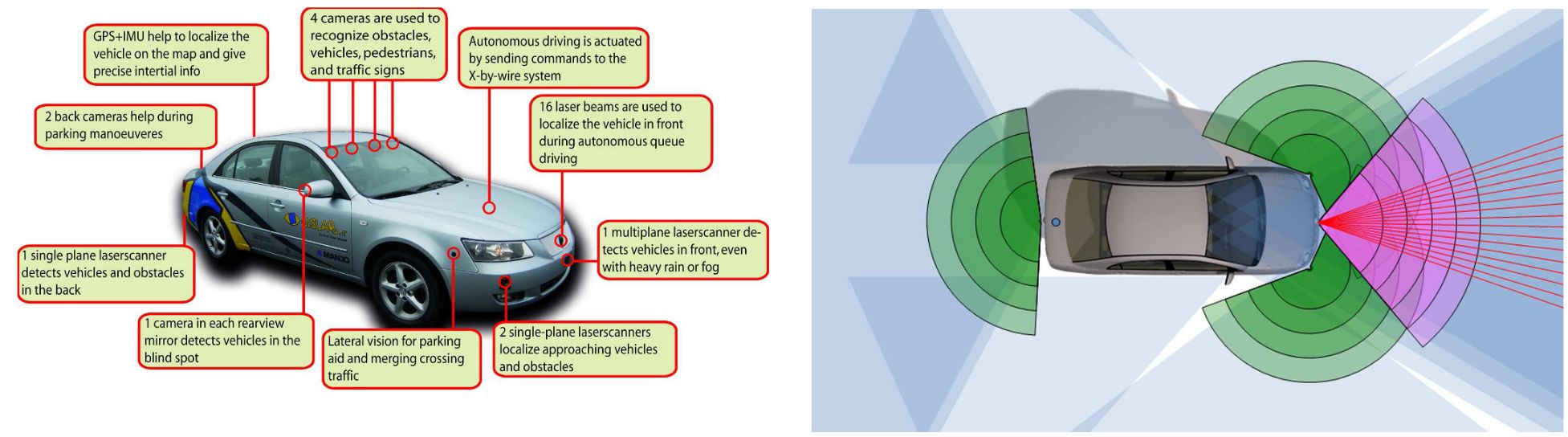
- BRAiVE vehicle system is designed to change the transportation world to move people in a safer and more efficient way
- Introduction of advanced systems and more complex levels of automation
- Description and comparison to other similar projects around the world pointing out the innovations
- Three main components: sensing, processing and actuation
- Cameras, lasers, GPS and IMU are used for sensing
- Actuation consists of X-By-Wire system, dSpace Micro Autobox, e-Stop system
- Novelty is the high level of integration reached which makes this vehicle look like a normal car even with a very sophisticated sensing suite
| Optical Flow Methods | |||
|
ACCV 2016
Guney2016ACCV | |||
- Learning features for optical flow by training a CNN for feature matching on image patches
- Large receptive field size via dilated convolutions
- A context network (dilated convolutions) trained on the output of a local network (regular convolutions)
- Fast exact matching on GPU
- Discrete flow framework
- Regular BP with 300 proposals
- Evaluated on Sintel and KITTI benchmarks
| Stereo Methods | |||
|
CVPR 2015
Guney2015CVPR | |||
- Using object-category specific disparity proposals (displets) to compensate for the weak data term on the reflecting and textureless surfaces
- Displets as non-local regularizer for the challenging object class 'car' in a superpixel based CRF framework
- Sampling displets using inverse graphics techniques based on a sparse disparity estimate and a semantic segmentation of the image
- Representative set of 3D CAD models of cars from Google Warehouse (8 models)
- Mesh simplification of 3D CAD models for preserving the hull of the object
- The best performing method on KITTI stereo benchmark, but slow
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
CVPR 2015
Guney2015CVPR | |||
- Using object-category specific disparity proposals (displets) to compensate for the weak data term on the reflecting and textureless surfaces
- Displets as non-local regularizer for the challenging object class 'car' in a superpixel based CRF framework
- Sampling displets using inverse graphics techniques based on a sparse disparity estimate and a semantic segmentation of the image
- Representative set of 3D CAD models of cars from Google Warehouse (8 models)
- Mesh simplification of 3D CAD models for preserving the hull of the object
- The best performing method on KITTI stereo benchmark, but slow
| History of Autonomous Driving | |||
|
THREEDV 2014
Haene2014THREEDV | |||
- An adaptation of camera projection models for fisheye cameras into the plane-sweeping stereo matching algorithm
- Depth maps computed directly from the fisheye images to cover a larger part of the scene with fewer images
- Plane-sweeping approach over rectification:
- Suitable for more than two images
- Well-suited to GPUs fro real-time performance
- Requirement: Efficient projection and unprojection
- Two different camera models: the unified projection and the field-of-view (FOV)
- Unified projection model also works for other non-pinhole cameras such as omnidirectional and catadioptric cameras.
- Simple, real-time approach for full, good quality and high resolution depth maps
| Stereo Methods | |||
|
THREEDV 2014
Haene2014THREEDV | |||
- An adaptation of camera projection models for fisheye cameras into the plane-sweeping stereo matching algorithm
- Depth maps computed directly from the fisheye images to cover a larger part of the scene with fewer images
- Plane-sweeping approach over rectification:
- Suitable for more than two images
- Well-suited to GPUs fro real-time performance
- Requirement: Efficient projection and unprojection
- Two different camera models: the unified projection and the field-of-view (FOV)
- Unified projection model also works for other non-pinhole cameras such as omnidirectional and catadioptric cameras.
- Simple, real-time approach for full, good quality and high resolution depth maps
| History of Autonomous Driving | |||
|
IROS 2015
Haene2015IROS | |||
- Extracting static obstacles from depth maps computed from monocular fisheye cameras parked cars and signposts, the amount of free space, distance between obstacles, the size of an empty parking spot
- Motivation: Affordable, reliable, accurate, and real-time detection of obstacles
- Two approaches: Active methods using sensors such as laser scanners, time-of-flight, structured light or ultrasound and passive methods using camera images
- No need for accurate visual inertial odometry estimation, only available wheel odometry
- Steps:
- Depth estimation for each camera using multi-view stereo matching
- Obstacle detection in 2D
- Fusing the obstacle detections over several camera frames to handle uncertainty
- Accurate enough for navigation purposes of self-driving cars
| Semantic Segmentation Methods | |||
|
IROS 2015
Haene2015IROS | |||
- Extracting static obstacles from depth maps computed from monocular fisheye cameras parked cars and signposts, the amount of free space, distance between obstacles, the size of an empty parking spot
- Motivation: Affordable, reliable, accurate, and real-time detection of obstacles
- Two approaches: Active methods using sensors such as laser scanners, time-of-flight, structured light or ultrasound and passive methods using camera images
- No need for accurate visual inertial odometry estimation, only available wheel odometry
- Steps:
- Depth estimation for each camera using multi-view stereo matching
- Obstacle detection in 2D
- Fusing the obstacle detections over several camera frames to handle uncertainty
- Accurate enough for navigation purposes of self-driving cars
| Semantic Segmentation Methods | |||
|
APRS 2016
Hackel2016APRS | |||
- Semantic segmentation of 3D point clouds
- Unstructured and inhomogeneous point clouds (LiDAR, photogammetric reconstruction)
- Features from neighbourhood relations
- A multi-scale pyramid with decreasing point density
- A separate search structure per scale level
- Random Forest classifier to predict class-conditional probabilities
- Point clouds with many millions of points in a matter of minutes (< 4 minutes per 10 million points)
- Evaluated on
- benchmark data from a mobile mapping platform (Paris-Rue-Cassette and Paris-Rue-Madame)
- a variety of large, terrestrial laser scans with greatly varying point density
| History of Autonomous Driving | |||
|
CVPR 2014
Haene2014CVPR | |||

- Dense 3D reconstruction of real world objects
- General smoothness priors such as surface area regularization can lead to defects
- Exploit the object class specific local surface orientation to solve this problem
- Object class specific shape prior in form of spatially varying anisotropic smoothness term
- Discrete Wulff shapes allow general enough parametrization for anisotropic smoothness
- Parameters are extracted from training data
- Directly fits into volumetric multi-label reconstruction approaches
- Allows a segmentation between the object and its supporting grounds
- Evaluated on synthetic data and real world sequences
| Semantic Segmentation Methods | |||
|
CVPR 2014
Haene2014CVPR | |||
- Dense 3D reconstruction of real world objects
- General smoothness priors such as surface area regularization can lead to defects
- Exploit the object class specific local surface orientation to solve this problem
- Object class specific shape prior in form of spatially varying anisotropic smoothness term
- Discrete Wulff shapes allow general enough parametrization for anisotropic smoothness
- Parameters are extracted from training data
- Directly fits into volumetric multi-label reconstruction approaches
- Allows a segmentation between the object and its supporting grounds
- Evaluated on synthetic data and real world sequences
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
CVPR 2014
Haene2014CVPR | |||
- Dense 3D reconstruction of real world objects
- General smoothness priors such as surface area regularization can lead to defects
- Exploit the object class specific local surface orientation to solve this problem
- Object class specific shape prior in form of spatially varying anisotropic smoothness term
- Discrete Wulff shapes allow general enough parametrization for anisotropic smoothness
- Parameters are extracted from training data
- Directly fits into volumetric multi-label reconstruction approaches
- Allows a segmentation between the object and its supporting grounds
- Evaluated on synthetic data and real world sequences
| History of Autonomous Driving | |||
|
CVPR 2013
Haene2013CVPR | |||

- Proposes a rigorous mathematical framework to formulate and solve a joint segmentation and dense reconstruction problem
- Contributions:
- Demonstrates that joint image segmentation and dense 3D reconstruction is beneficial for both tasks
- Introduces a rigorous mathematical framework to formulate and solve this joint optimization task.
- Extends volumetric scene reconstruction methods to a multi-label volumetric segmentation framework
- Evaluates on castle P-30 dataset
| Semantic Segmentation Methods | |||
|
CVPR 2013
Haene2013CVPR | |||
- Proposes a rigorous mathematical framework to formulate and solve a joint segmentation and dense reconstruction problem
- Contributions:
- Demonstrates that joint image segmentation and dense 3D reconstruction is beneficial for both tasks
- Introduces a rigorous mathematical framework to formulate and solve this joint optimization task.
- Extends volumetric scene reconstruction methods to a multi-label volumetric segmentation framework
- Evaluates on castle P-30 dataset
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
CVPR 2013
Haene2013CVPR | |||
- Proposes a rigorous mathematical framework to formulate and solve a joint segmentation and dense reconstruction problem
- Contributions:
- Demonstrates that joint image segmentation and dense 3D reconstruction is beneficial for both tasks
- Introduces a rigorous mathematical framework to formulate and solve this joint optimization task.
- Extends volumetric scene reconstruction methods to a multi-label volumetric segmentation framework
- Evaluates on castle P-30 dataset
| History of Autonomous Driving | |||
|
THREEDIMPVT 2012
Haene2012THREEDIMPVT | |||

- Dense 3D reconstructions suffer from weak and ambiguous observations in man-made environments that can be solved with strong, domain-specific priors
- Powerful prior directly modeling the expected local surface-structure without the need for higher-order MRFs
- Using a small patch dictionary as by patch-based representations used in image processing
- Energy can be optimized using an efficient first-order primal dual algorithm
- The patch dictionary and priors on dictionary coefficients are known
- Demonstrate the prior for dense reconstruction of 3D models using stereo and fusion of multiple depth maps on synthetic data and real data
| Stereo Methods | |||
|
THREEDIMPVT 2012
Haene2012THREEDIMPVT | |||
- Dense 3D reconstructions suffer from weak and ambiguous observations in man-made environments that can be solved with strong, domain-specific priors
- Powerful prior directly modeling the expected local surface-structure without the need for higher-order MRFs
- Using a small patch dictionary as by patch-based representations used in image processing
- Energy can be optimized using an efficient first-order primal dual algorithm
- The patch dictionary and priors on dictionary coefficients are known
- Demonstrate the prior for dense reconstruction of 3D models using stereo and fusion of multiple depth maps on synthetic data and real data
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
CVPR 2008
Hays2008CVPR | |||
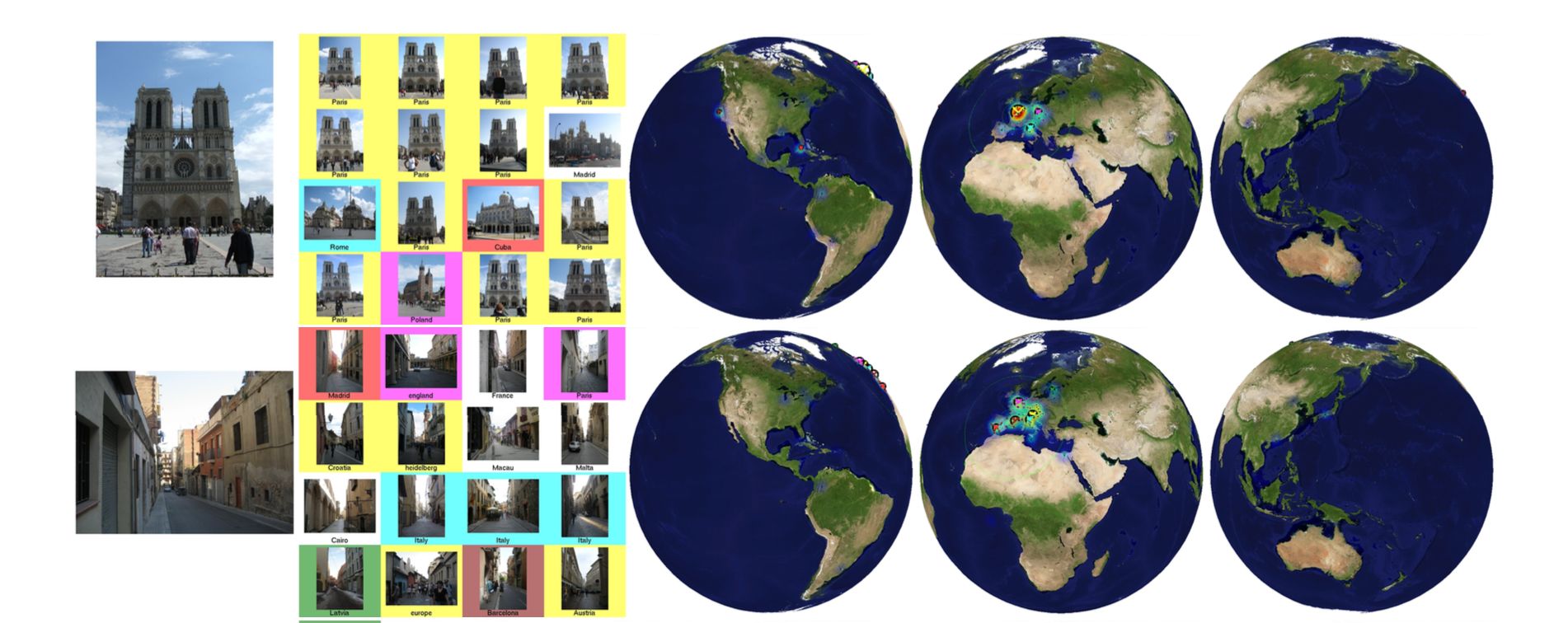
- Estimating a distribution over geographic locations from a single image
- A dataset of over 6 million GPS-tagged images from the Internet
- 30 times better than chance
- Data-driven approach:
- pre-compute features: color/texton histograms, line features, gist descriptor, color, geometric context
- compute the distance in each feature space to all 6 million images in the database
- aggregate feature distances to find the nearest neighbors in the database
- derive geo-location estimates from GPS tagged nearest neighbors
- Other related tasks: population density estimation, land cover estimation or urban/rural classification
| Semantic Segmentation Methods | |||
|
CVPR 2016
He2016CVPR | |||
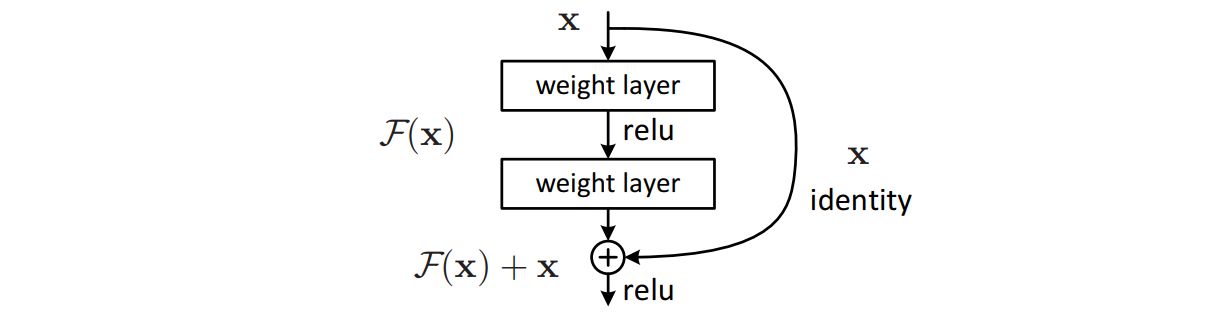
- Previous work has shown that the depth of a CNN is crucial to represent rich features.
- However, increasing the depth of a net- work lead to the saturation and degradation of the accuracy
- Thee paper proposes deep residual learning framework (ResNet) to address this problem.
- They let each stacked layer learn a residual mapping instead of the original, unreferenced mapping.
- This allows them to train deeper networks with improving accuracy while plain net- works (simply stacked networks) exhibited higher training errors.
- Demonstrate performance on ILSVRC & COCO 2015 competitions.
| Semantic Instance Segmentation Methods | |||
|
CVPR 2016
He2016CVPR | |||
- Previous work has shown that the depth of a CNN is crucial to represent rich features.
- However, increasing the depth of a net- work lead to the saturation and degradation of the accuracy
- Thee paper proposes deep residual learning framework (ResNet) to address this problem.
- They let each stacked layer learn a residual mapping instead of the original, unreferenced mapping.
- This allows them to train deeper networks with improving accuracy while plain net- works (simply stacked networks) exhibited higher training errors.
- Demonstrate performance on ILSVRC & COCO 2015 competitions.
| Object Detection Methods | |||
|
ECCV 2014
He2014ECCV | |||
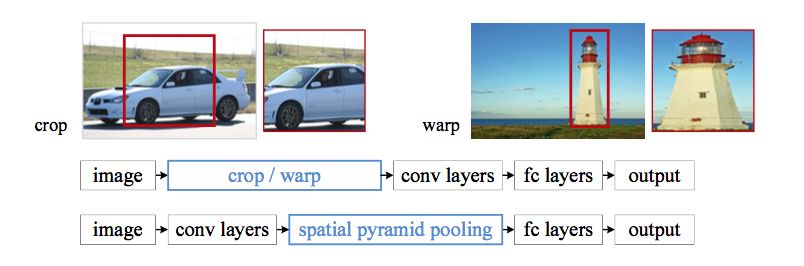
- Spatial Pyramid Pooling (SPP) to eliminate the requirement of fixed size input in CNNs
- Fixed-length representation regardless of image size/scale
- Improving all CNN-based image classification methods on the datasets of ImageNet 2012, Pascal VOC 2007, and Caltech101
- Especially in object detection:
- feature maps from the entire image only once
- pooling features in arbitrary regions o generate fixed-length representations and train object detectors
- No repeatedly computing of the convolutional features, resulting in large improvements in speed compared to R-CNN
| Object Detection State of the Art on KITTI | |||
|
ECCV 2014
He2014ECCV | |||
- Spatial Pyramid Pooling (SPP) to eliminate the requirement of fixed size input in CNNs
- Fixed-length representation regardless of image size/scale
- Improving all CNN-based image classification methods on the datasets of ImageNet 2012, Pascal VOC 2007, and Caltech101
- Especially in object detection:
- feature maps from the entire image only once
- pooling features in arbitrary regions o generate fixed-length representations and train object detectors
- No repeatedly computing of the convolutional features, resulting in large improvements in speed compared to R-CNN
| Semantic Segmentation Methods | |||
|
CVPR 2004
He2004CVPR | |||
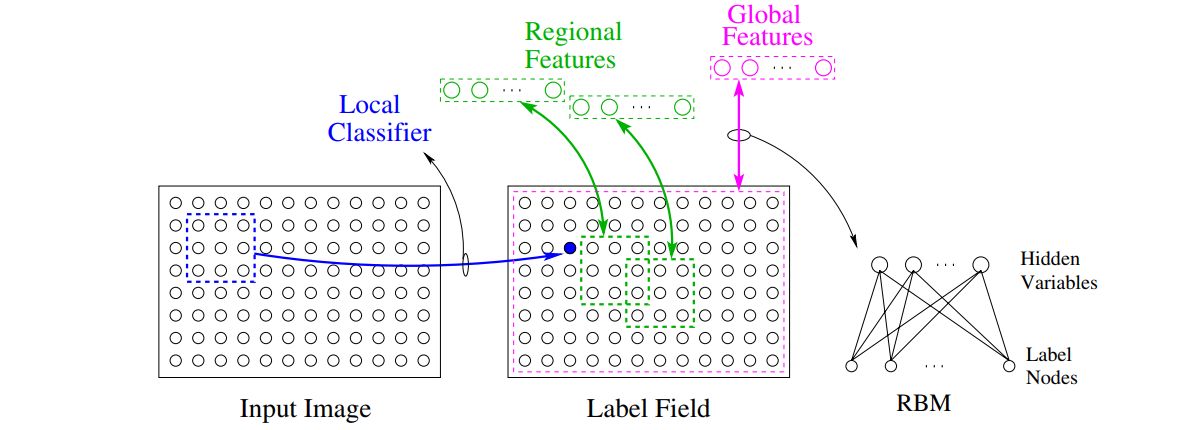
- Novel CRF model for labeling images into a predefined set of class labels.
- The model is a combination of three individual components
- Components differ in their scale, from fine resolution to more global structure
- a classifier that looks at local image statistics
- regional label features that look at local label patterns
- global label features that look at coarse label patterns
- Demonstrate performance on two real-world image databases
| Semantic Segmentation Methods | |||
|
ECCV 2006
He2006ECCV | |||

- Describe a segmentation scheme that integrates bottom-up cues with information about multiple object categories
- Bottom-up cues are used to produce an over-segmentation that is assumed to be consistent with object boundaries but breaks large objects into small pieces
- The problem then is how to group those segments into larger regions.
- They propose to use the top-down category-based information to help merge those segments into object components as an image labeling problem
- Demonstrate performance on three real-world image databases
| Optical Flow Problem Definition | |||
|
IJCV 1988
Heeger1988IJCV | |||
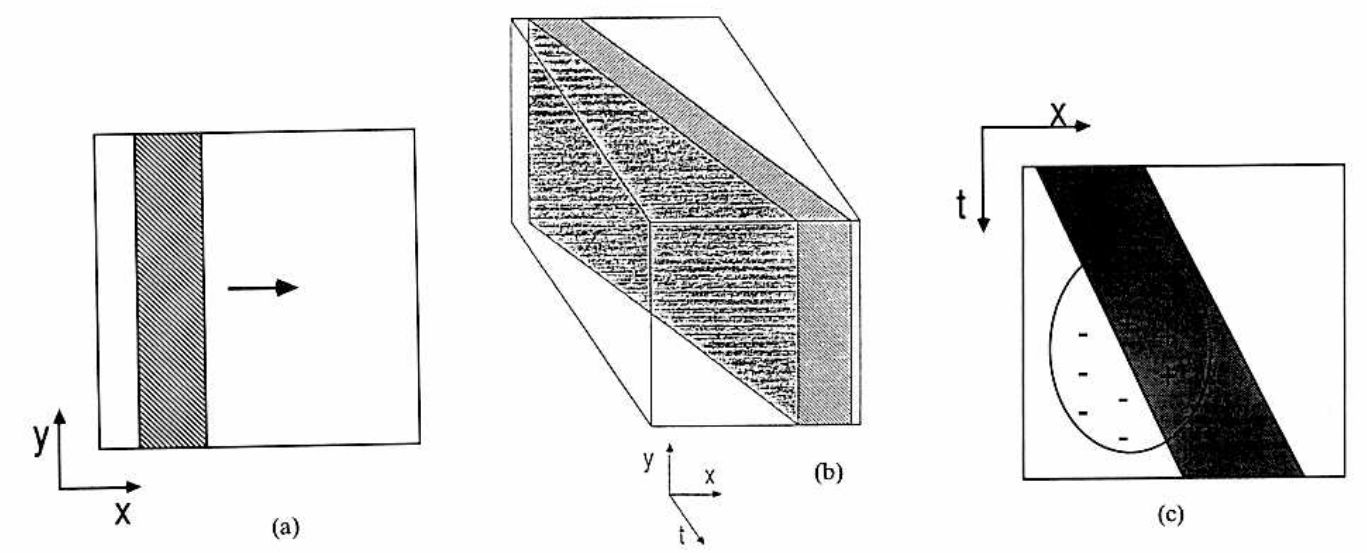
- Propose a model that combines the outputs of a set of spatiotemporal motion-energy filters to estimate optical flow
- Consonant with current views regarding the neurophysiology and psychophysics of motion perception
- Parallel implementation compute a distributed representation of image velocity
- Formulation to measure image-flow uncertainty that can be used to recognize ambiguities
- Model seems to deal with aperture problem since it extracts the correct motion in case of large differences in contrast at different spatial orientations
| History of Autonomous Driving | |||
|
JFR 2015
Heng2015JFR | |||
- Efficient, robust, completely unsupervised infrastructure-based calibration method for calibration of a multi-camera rig
- Efficient, near real-time
- No modification of the infrastructure (or calibration area)
- By using natural features instead of known fiducial markings
- Completely unsupervised
- No initial guesses for the extrinsic parameters
- Without assuming overlapping fields of view
- Using a map of a chosen calibration area via SLAM-based self-calibration (one-time run)
- Leveraging image-based localization
- Significantly improved version of Heng2013IROS Differences to :
- Robust 6D pose graph optimization
- Improved feature matching
- More improvements related to joint optimization
- Extensive experiments to quantify the accuracy and repeatability of the extrinsics
- Evaluation of the accuracy of the map
| Sensors Calibration | |||
|
JFR 2015
Heng2015JFR | |||
- Efficient, robust, completely unsupervised infrastructure-based calibration method for calibration of a multi-camera rig
- Efficient, near real-time
- No modification of the infrastructure (or calibration area)
- By using natural features instead of known fiducial markings
- Completely unsupervised
- No initial guesses for the extrinsic parameters
- Without assuming overlapping fields of view
- Using a map of a chosen calibration area via SLAM-based self-calibration (one-time run)
- Leveraging image-based localization
- Significantly improved version of Heng2013IROS Differences to :
- Robust 6D pose graph optimization
- Improved feature matching
- More improvements related to joint optimization
- Extensive experiments to quantify the accuracy and repeatability of the extrinsics
- Evaluation of the accuracy of the map
| History of Autonomous Driving | |||
|
IROS 2013
Heng2013IROS | |||
- A full automatic pipeline for both intrinsic calibration for a generic camera and extrinsic calibration for a rig with multiple generic cameras and odometry
- Without the need for GPS/INS and the Vicon motion capture system
- Intrinsic calibration for each generic camera using a chessboard
- Extrinsic calibration to find all camera-odometry transforms
- Monocular VO for each camera using five-point algorithm and linear triangulation
- Robust initial estimate of camera-odometry transform robust to poor-feature areas
- 3D point triangulation
- Finding local inter-camera feature point correspondences for consistency
- Loop closure detection using a vocabulary tree
- Full bundle adjustment which optimizes all intrinsics, extrinsics, odometry poses, and 3D scene points
- Globally-consistent sparse map of landmarks which can be used for visual localization
- Highly accurate, automated, adaptable calibration for arbitrary, large-scale environments
| Sensors Calibration | |||
|
IROS 2013
Heng2013IROS | |||
- A full automatic pipeline for both intrinsic calibration for a generic camera and extrinsic calibration for a rig with multiple generic cameras and odometry
- Without the need for GPS/INS and the Vicon motion capture system
- Intrinsic calibration for each generic camera using a chessboard
- Extrinsic calibration to find all camera-odometry transforms
- Monocular VO for each camera using five-point algorithm and linear triangulation
- Robust initial estimate of camera-odometry transform robust to poor-feature areas
- 3D point triangulation
- Finding local inter-camera feature point correspondences for consistency
- Loop closure detection using a vocabulary tree
- Full bundle adjustment which optimizes all intrinsics, extrinsics, odometry poses, and 3D scene points
- Globally-consistent sparse map of landmarks which can be used for visual localization
- Highly accurate, automated, adaptable calibration for arbitrary, large-scale environments
| Semantic Segmentation Methods | |||
|
PAMI 2008
Hirschmueller2008PAMI | |||
- A pixel-wise, Mutual Information (MI)-based matching cost
- Cost aggregation as approximation of a global, 2D smoothness constraint by combining many 1D constraints
- Two terms by using a lower penalty for small changes
- Disparity computation as WTA and by disparity refinements as consistency checking and sub-pixel interpolation
- Propagating valid disparities along paths from eight directions
- Multi-baseline matching by fusion of disparities
- Further disparity refinements: peak filtering, intensity consistent disparity selection, and gap interpolation
- Matching almost arbitrarily large images
- Fusion of several disparity images using orthographic projection
| Stereo Methods | |||
|
PAMI 2008
Hirschmueller2008PAMI | |||
- A pixel-wise, Mutual Information (MI)-based matching cost
- Cost aggregation as approximation of a global, 2D smoothness constraint by combining many 1D constraints
- Two terms by using a lower penalty for small changes
- Disparity computation as WTA and by disparity refinements as consistency checking and sub-pixel interpolation
- Propagating valid disparities along paths from eight directions
- Multi-baseline matching by fusion of disparities
- Further disparity refinements: peak filtering, intensity consistent disparity selection, and gap interpolation
- Matching almost arbitrarily large images
- Fusion of several disparity images using orthographic projection
| Stereo Methods | |||
|
CVPR 2007
Hirschmueller2007CVPR | |||

- Evaluation of the insensitivity of different matching costs with respect to radiometric variations for stereo correspondence methods
- Pixel-based and window-based variants are considered
- Sampling-insensitive absolute differences, three filter-based costs, hierarchical mutual information and normalized cross-correlation
- Measure the performance in the presence of global intensity changes, local intensity changes, and noise
- Different costs are evaluated with local, semi-global and global stereo methods
- Using Middlebury stereo dataset with ground-truth disparities and six new datasets taken under controlled changes of exposure and lighting
- Filter-based costs performed best with local radiometric variations but have blurry edges whereas HMI has sharp edges
| Scene Understanding Methods | |||
|
IJCV 2007
Hoiem2007IJCV | |||
- Constructing the surface layout via a labelling of the image into geometric classes
- main classes (support, vertical, sky) and subclasses of vertical (left, center, right, porous, solid)
- Appearance-based models for each class through multiple segmentations
- A wide variety of image cues including position, color, texture, and perspective
- Multiple segmentations for the spatial support, useful especially for subclasses
- Applicable to a wide variety of outdoor scenes and generalizable to indoor scenes
| Object Detection Methods | |||
|
IJCV 2008
Hoiem2008IJCV | |||

- Framework for object detection
- Modeling the interdependence of objects, surface orientations, and camera viewpoint
- Probabilistic estimates of 3D geometry enable to model the scale and location variance in the image
- Allowing probabilistic objects hypotheses to refine geometry and vice-versa
- Substitution of any object detector possible
- Easy extension to include other aspects from image understanding
- Results confirm the benefits
| Optical Flow Problem Definition | |||
|
AI 1981
Horn1981AI | |||
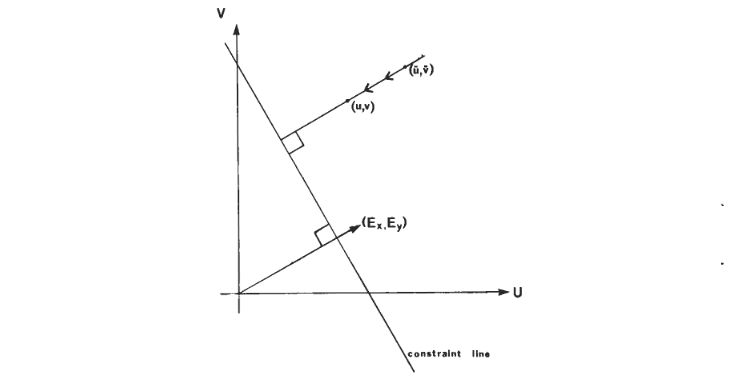
- Pioneering work in optical flow computation
- Computation of optical flow considering only one pixel is not possible since only one independent measurement is available while the motion has two components
- Present the first method to compute optical flow by assuming that the motion varies smoothly between neighbors
- Propose an iterative implementation that successfully computes optical flow
- This formulation is not robust to violations of the brightness constancy and motion discontinuities
- Demonstration only on synthetic toy examples
| Optical Flow Methods | |||
|
AI 1981
Horn1981AI | |||
- Pioneering work in optical flow computation
- Computation of optical flow considering only one pixel is not possible since only one independent measurement is available while the motion has two components
- Present the first method to compute optical flow by assuming that the motion varies smoothly between neighbors
- Propose an iterative implementation that successfully computes optical flow
- This formulation is not robust to violations of the brightness constancy and motion discontinuities
- Demonstration only on synthetic toy examples
| Semantic Segmentation Methods | |||
|
ICPR 2016
Huang2016ICPR | |||
- Labelling 3D point clouds using a 3D CNN
- Motivation:
- Projecting 3D to 2D: loss of important 3D structural information
- No segmentation step or hand-crafted features
- An end-to-end segmentation method based on voxelized data
- Voxelization to generate occupancy voxel grids centered at a set of keypoints
- 3D CNN: two 3D convolutional layers, two 3D max-pooling layers, a fully connected layer and a logistic regression layer
- Experiments on a large Lidar point cloud dataset of the urban area of Ottawa with 7 categories
| Object Detection Methods | |||
|
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift[scholar]
|
ICML 2015
Ioffe2015ICML | ||
| Semantic Segmentation Methods | |||
|
Learning Sparse High Dimensional Filters: Image Filtering, Dense CRFs and Bilateral Neural Networks[scholar]
|
CVPR 2016
Jampani2016CVPR | ||
- Generalize the parametrization of bilateral filters.
- Use the permutohedral lattice to freely parametrize its values.
- Derive a gradient descent algorithm to learn the filter parameters from data.
- Unroll the CRF which allows for end-to-end training of the filter parameters from data.
- Allows for reasoning over larger spatial regions within one convolutional layer by leveraging input features as a guiding signal.
- Evaluates on two pixel labeling tasks, semantic segmentation of VOC data and material classification
| Datasets & Benchmarks | |||
|
Slow Flow: Exploiting High-Speed Cameras for Accurate and Diverse Optical Flow Reference Data[scholar]
|
CVPR 2017
Janai2017CVPR | ||

- A novel challenging optical flow dataset from a high-speed camera
- Accurate reference flow fields outside the laboratory in natural environments
- dense pixel tracking over a large number of high-resolution input frames
- discrete-continuous multi-frame variational model
- exploiting linearity within small temporal windows
- Evaluating the quality of the produced flow fields on synthetic and real-world datasets
- Augmenting the input images with realistic motion blur
- Analysis of the performance of the state-of-the-art in optical flow under various levels of motion blur
| Datasets & Benchmarks Computer Vision Datasets | |||
|
Slow Flow: Exploiting High-Speed Cameras for Accurate and Diverse Optical Flow Reference Data[scholar]
|
CVPR 2017
Janai2017CVPR | ||
- A novel challenging optical flow dataset from a high-speed camera
- Accurate reference flow fields outside the laboratory in natural environments
- dense pixel tracking over a large number of high-resolution input frames
- discrete-continuous multi-frame variational model
- exploiting linearity within small temporal windows
- Evaluating the quality of the produced flow fields on synthetic and real-world datasets
- Augmenting the input images with realistic motion blur
- Analysis of the performance of the state-of-the-art in optical flow under various levels of motion blur
| Datasets & Benchmarks Computer Vision Datasets | |||
|
CVPR 2014
Jensen2014CVPR | |||

- Existing stereo benchmarks, eg Middlebury, are limited in scope with few reference scenes
- A new multi-view stereo dataset: an order of magnitude larger in number of scenes and with a significant increase in diversity
- 80 scenes of large variability, each scene with 49 or 64 accurate camera positions and reference structured light scans
- Extending Middlebury evaluation protocol to reflect the more complex geometry
- Evaluating multiple multi-view stereo algorithms with respect to both completeness and accuracy
| Multi-view 3D Reconstruction Datasets | |||
|
CVPR 2014
Jensen2014CVPR | |||
- Existing stereo benchmarks, eg Middlebury, are limited in scope with few reference scenes
- A new multi-view stereo dataset: an order of magnitude larger in number of scenes and with a significant increase in diversity
- 80 scenes of large variability, each scene with 49 or 64 accurate camera positions and reference structured light scans
- Extending Middlebury evaluation protocol to reflect the more complex geometry
- Evaluating multiple multi-view stereo algorithms with respect to both completeness and accuracy
| Multi-view 3D Reconstruction State of the Art on ETH3D & Tanks and Temples | |||
|
CVPR 2014
Jensen2014CVPR | |||
- Existing stereo benchmarks, eg Middlebury, are limited in scope with few reference scenes
- A new multi-view stereo dataset: an order of magnitude larger in number of scenes and with a significant increase in diversity
- 80 scenes of large variability, each scene with 49 or 64 accurate camera positions and reference structured light scans
- Extending Middlebury evaluation protocol to reflect the more complex geometry
- Evaluating multiple multi-view stereo algorithms with respect to both completeness and accuracy
| Datasets & Benchmarks Synthetic Data Generation using Game Engines | |||
|
ICM 2014
Jia2014ICM | |||
- CAFFE framework for deep learning
- BSD-licensed C++ library for training and deploying CNNs
- CUDA for GPU computation
- Fully open source
- Highlights:
- Modularity
- Separation of representation and implementation
- Test coverage
- Python and MATLAB bindings
- Pre-trained reference models
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
IJRR 2012
Kaess2012IJRR | |||
- Presents a novel data structure, the Bayes tree, that provides an algorithmic foundation enabling a better understanding of existing graphical model inference algorithms and their connection to sparse matrix factorization methods
- Contributions:
- Bayes tree encodes a factored probability density, but unlike the clique tree it is directed and maps more naturally to the information matrix of the simultaneous localization and mapping problem
- Shows how the fairly abstract updates to a matrix factorization translate to a simple editing of the Bayes tree and its conditional densities
- Applies the Bayes tree to obtain a novel algorithm for sparse nonlinear incremental optimization, which achieves improvements in efficiency through incremental variable re-ordering & relinearization
- Evaluates on a range of real and simulated datasets like Manhattan, Killian Court and City20000
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
TR 2008
Kaess2008TR | |||
- Simultaneous localization and mapping
- Requirements for SLAM: incremental, real-time, applicable to large-scale environments, and online data association
- An incremental smoothing and mapping approach based on fast incremental matrix factorization
- Efficient and exact solution by updating a QR factorization of the naturally sparse smoothing information matrix
- Recalculating only the matrix entries that actually change
- Periodic variable reordering to avoid unnecessary fill-in (trajectories with many loops)
- Estimation of relevant uncertainties for online data association
- Evaluation on various simulated and real-world datasets for both landmark and pose-only settings
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
CVPRWORK 2009
Kaminsky2009CVPRWORK | |||
- Addresses the problem of automatically aligning structure-from-motion reconstructions to overhead images, such as satellite images, maps and floor plans, generated from an orthographic camera
- Contributions:
- Computes the optimal alignment using an objective function that matches 3D points to image edges
- Imposes free space constraints based on the visibility of points in each camera
- Evaluates on several outdoor and indoor scenes using both satellite and floor plan images
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
ICCV 2015
Kendall2015ICCV | |||
- Robust and real-time monocular relocalization system
- 23 layer deep convnet to regress the 6-DOF camera pose from a RGB image in an end-to-end manner
- Transfer learning from large scale classification data (training a pose regressor, pre-trained as a classifier on immense recognition datasets)
- Using SfM to automatically generate camera poses from a video of the scene
- Mapping feature vectors to pose which generalizes to unseen scenes with a few additional training samples
- Evaluated on both indoors (7 Scenes dataset) and outdoors in real time, (5ms per frame)
- An outdoor urban localization dataset with 5 scenes: Cambridge Landmarks
- Robust to difficult lighting, motion blur and different camera intrinsics where point based SIFT registration fails
| Mapping, Localization & Ego-Motion Estimation Datasets | |||
|
ICCV 2015
Kendall2015ICCV | |||
- Robust and real-time monocular relocalization system
- 23 layer deep convnet to regress the 6-DOF camera pose from a RGB image in an end-to-end manner
- Transfer learning from large scale classification data (training a pose regressor, pre-trained as a classifier on immense recognition datasets)
- Using SfM to automatically generate camera poses from a video of the scene
- Mapping feature vectors to pose which generalizes to unseen scenes with a few additional training samples
- Evaluated on both indoors (7 Scenes dataset) and outdoors in real time, (5ms per frame)
- An outdoor urban localization dataset with 5 scenes: Cambridge Landmarks
- Robust to difficult lighting, motion blur and different camera intrinsics where point based SIFT registration fails
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
IV 2010
Kitt2010IV | |||
- Well distributed corner-like feature matches due to bucketing
- Using trifocal geometry the egomotion is estimated
- Iterated Sigma Point Kalman Filter yields robust frame-to-frame motion estimation
- Outlier are rejected with RANSAC-based approach
- Outperforms other filtering techniques in accuracy and run time
- Evaluated on simulated and real world data with INS trajectories
| Multi-view 3D Reconstruction State of the Art on ETH3D & Tanks and Temples | |||
|
SIGGRAPH 2017
Knapitsch2017SIGGRAPH | |||
| Semantic Segmentation Methods | |||
|
IJCV 2009
Kohli2009IJCV | |||
- This paper proposed a novel framework for labelling problems which is capable of utilizing features based on sets of pixels.
- Showed that incorporation of P^n Potts and Robust P^n model type potential functions defined on segments in the CRF model for object segmentation significantly improved results around object boundaries.
- Demonstrate performance on MSRC-23 and Sowerby-7 datasets.
| Optical Flow Methods | |||
|
PAMI 2006
Kolmogorov2006PAMI | |||

- Propose an extension for a discrete energy minimization method
- Tree-reweighted max-product message passing (TRW) was inspired by the problem of maximizing a lower bound on the energy
- TRW is not guaranteed to increase this bound and does not always converge
- Propose a modification of the approach called sequential tree-reweighted message passing (TRW-S)
- The bound is guaranteed to not decrease
- Weak tree agreement condition characterizes local maxima of the bound with respect to TRW
- Prove that the algorithm has a limit point that achieves a weak tree agreement
- Half of the memory consumption as traditional message passing approaches
- Outperforms ordinary belief propagation and TRW on synthetic and real problems
- On stereo problems with Potts model TRW-S obtains a lower energy than graph cuts
| Optical Flow Methods | |||
|
GCPR 2007
Kondermann2007GCPR | |||
- Confidence measures allow the validation of optical flow fields
- Novel confidence measure based on linear subspace projections
- Comparison to previously proposed measures with respect to an optical confidence
- Improvement by 31 in comparison to previous work
| Datasets & Benchmarks | |||
|
CVPRWORK 2016
Kondermann2016CVPRWORK | |||

- Stereo and optical flow dataset to complement existing benchmarks
- Representative for urban autonomous driving, including realistic systematically varied radiometric and geometric challenges
- Evaluation of the ground truth accuracy with Monte Carlo simulations
- Interquartile ranges are used as uncertainty measure
- Binary masks for dynamically moving regions are supplied with estimated stereo and flow
- Initial benchmark consists of 55 manually selected sequences between 19 and 100 frames
- Interactive tools for database search, visualization, comparison and benchmarking
| Datasets & Benchmarks Computer Vision Datasets | |||
|
CVPRWORK 2016
Kondermann2016CVPRWORK | |||
- Stereo and optical flow dataset to complement existing benchmarks
- Representative for urban autonomous driving, including realistic systematically varied radiometric and geometric challenges
- Evaluation of the ground truth accuracy with Monte Carlo simulations
- Interquartile ranges are used as uncertainty measure
- Binary masks for dynamically moving regions are supplied with estimated stereo and flow
- Initial benchmark consists of 55 manually selected sequences between 19 and 100 frames
- Interactive tools for database search, visualization, comparison and benchmarking
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
CVPRWORK 2016
Kondermann2016CVPRWORK | |||
- Stereo and optical flow dataset to complement existing benchmarks
- Representative for urban autonomous driving, including realistic systematically varied radiometric and geometric challenges
- Evaluation of the ground truth accuracy with Monte Carlo simulations
- Interquartile ranges are used as uncertainty measure
- Binary masks for dynamically moving regions are supplied with estimated stereo and flow
- Initial benchmark consists of 55 manually selected sequences between 19 and 100 frames
- Interactive tools for database search, visualization, comparison and benchmarking
| Semantic Segmentation Methods | |||
|
NIPS 2011
Kraehenbuehl2011NIPS | |||
- Existing methods are restricted by the accuracy of the unsupervised image segmentations used as input to compute the regions on which the model operates.
- This paper proposes a highly efficient inference algorithm for fully connected CRF models which models pairwise potentials between all pairs of pixels in the image.
- The algorithm is based on a mean field approximation to the CRF distribution.
- Evaluate performance on MSRC-21 and the PASCAL VOC 2010 datasets.
| Semantic Segmentation Methods | |||
|
IV 2012
Kuehnl2012IV | |||
- Road classification in in unconstrained environments
- Extending local appearance-based road classification with a spatial feature generation and classification
- Local properties from base classifiers on patches from monocular camera images
- Output of classifiers represented in a metric confidence map
- Spatial ray features (SPRAY) from these confidence maps
- Final road-terrain classification based on local visual properties and their spatial layout
- No an explicit lane model
- In real-time with approximately 25 Hz on a GPU
| Scene Understanding Methods | |||
|
CVPR 2010
Kuettel2010CVPR | |||
- Learning spatio-temporal dependencies of moving agents in complex dynamic scenes What are the typical actions in the scene? How do they relate to each other? What are the rules governing the scene?
- Motivation: modelling
- correlated behaviours of multiple agents rather than independent agents
- spatial and temporal dependencies jointly
- Local temporal rules: learning sequences of activities using Hierarchical Dirichlet Processes (HDP)
- Global temporal rules: jointly learning co-occurring activities and their time dependencies using an arbitrary number of HMMs in HDP
- Datasets: two videos of three hours in Zurich and two shorter videos of London
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
ECCV 2014
Kundu2014ECCV | |||
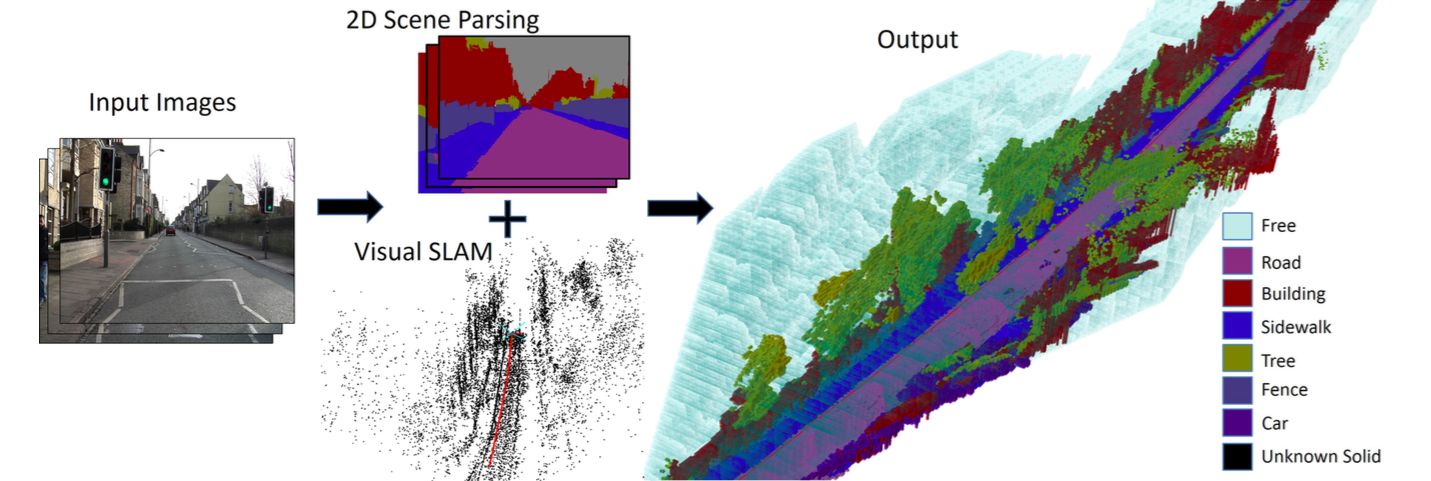
- Presents a method for joint inference of both semantic segmentation and 3D reconstruction
- Contributions:
- Introduces a novel higher order CRF model for joint inference of 3D structure and semantics in a 3D volumetric model
- The framework does not require dense depth measurements and utilizes semantic cues and 3D priors to enhance both depth estimation and scene parsing
- Presents a data-driven category-specific process for dynamically instantiating potentials in the CRF
- Evaluates on monocular sequences such as CamVid and Leuven
| Semantic Segmentation Methods | |||
|
CVPR 2016
Kundu2016CVPR | |||

- long-range spatio-temporal regularization in semantic video segmentation
- Temporal regularization is challenging because of camera and scene motion
- Optimize the position of pixels in a Euclidean feature space to minimize the distances between corresponding points
- Structured prediction is performed by a dense CRF operating on the optimized features
- Evaluation on CamVid and Cityscapes dataset and achieving state-of-the-art accuracy for semantic video segmentation
| Semantic Segmentation Discussion | |||
|
CVPR 2016
Kundu2016CVPR | |||
- long-range spatio-temporal regularization in semantic video segmentation
- Temporal regularization is challenging because of camera and scene motion
- Optimize the position of pixels in a Euclidean feature space to minimize the distances between corresponding points
- Structured prediction is performed by a dense CRF operating on the optimized features
- Evaluation on CamVid and Cityscapes dataset and achieving state-of-the-art accuracy for semantic video segmentation
| Stereo Methods | |||
|
ICCVWORK 2013
Kuschk2013ICCVWORK | |||

- Presents a fast algorithm for high-accuracy large-scale outdoor dense stereo reconstruction of man- made environments
- Contributions:
- Proposes a structure-adaptive second-order Total Generalized Variation (TGV) regularization which facilitates the emergence of planar structures by enhancing the discontinuities along building facades
- Uses cost functions as data term which are robust to illumination changes arising in real world scenarios
- Instead of solving the optimization problem by a coarse-to-fine approach, proposes a quadratic relaxation which is solved by an augmented Lagrangian method
- This technique allows for capturing large displacements and fine structures simultaneously
- Experiments show that the proposed augmented Lagrangian formulation leads to a speedup by about a factor of 2
- Evaluates on Middlebury, KITTI stereo datasets
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
IJCV 2000
Kutulakos2000IJCV | |||

- Multi-view stereo algorithm from a wide range of viewpoints
- No constraints on scene geometry or topology, on the positions of the input cameras
- No information on features or correspondences
- Studying the equivalence class of all 3D shapes that reproduce the input photographs
- The photo hull: a volume which is the tightest possible bound on the shape of the true scene that can be inferred from a set of photographs
- Space Carving: a discrete algorithm that iteratively removes (ie carving) portions of a given initial volume until it converges to the photo hull
- Evaluated on complex real-world scenes
- Complex interactions between occlusion, parallax, shading, and their view-dependent effects on scene-appearance
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
Efficient Multi-View Reconstruction of Large-Scale Scenes using Interest Points, Delaunay Triangulation and Graph Cuts[scholar]
|
ICCV 2007
Labatut2007ICCV | ||
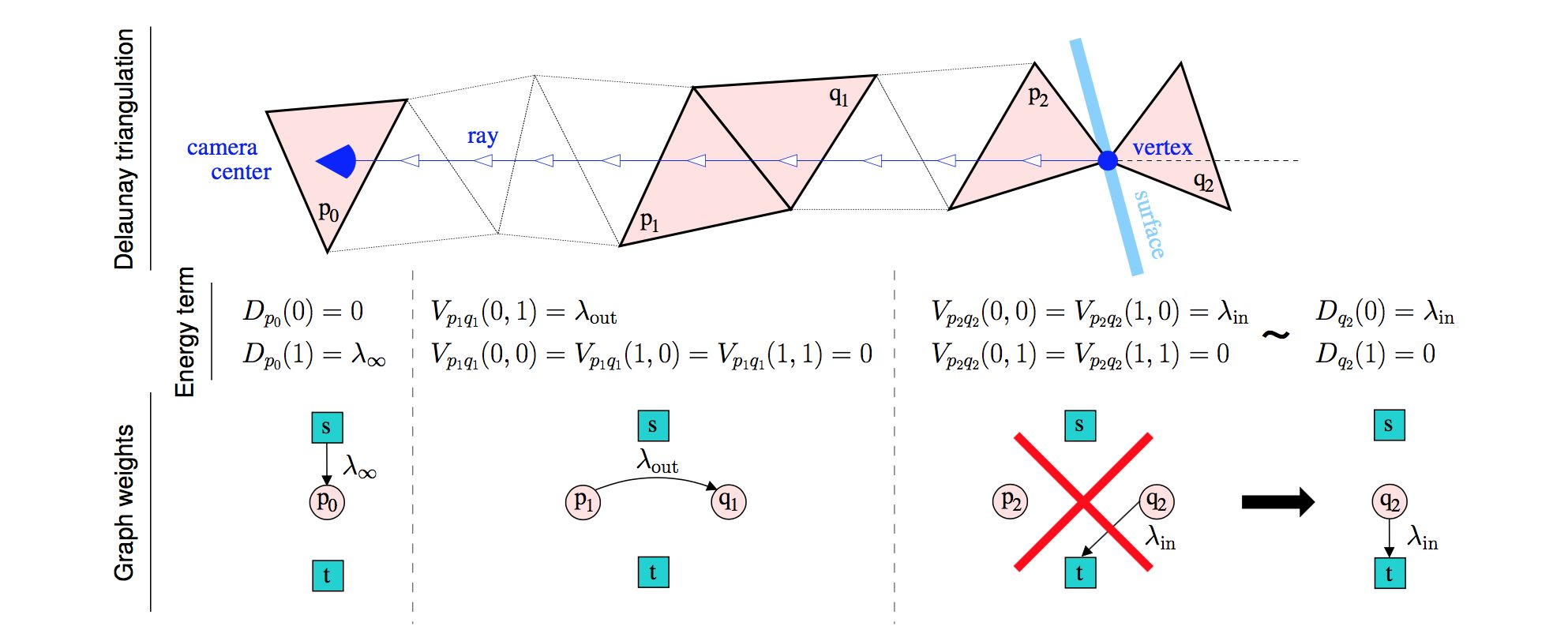
- Reconstructing large-scale cluttered scenes under uncontrolled imaging conditions
- A quasi-dense 3D point cloud of the scene by matching keypoints across images
- An adaptive tetrahedral decomposition of space by computing the 3D Delaunay triangulation of the 3D point set
- Reconstructing the scene by labeling Delaunay tetrahedra as empty or occupied, generating a triangular mesh of the scene
- Photo-consistency and compatibility with the visibility of keypoints in input images
- Formulated as a minimum cut solution in a graph
- Without any knowledge of the scene geometry
- Efficiency by representing empty space by a few large tetrahedra
| Semantic Segmentation Methods | |||
|
IV 2016
AnkitLaddha2016IV | |||
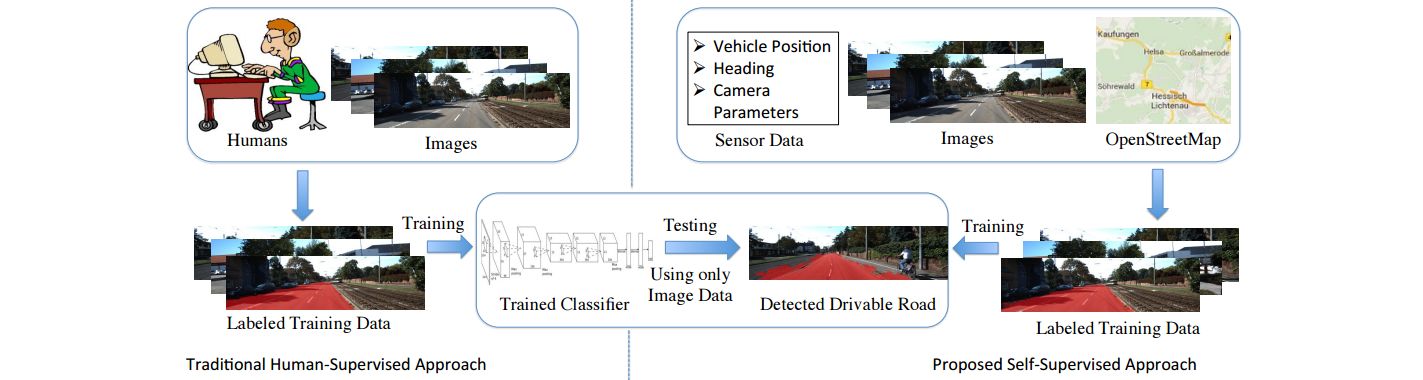
- Proposes an approach to detect drivable road area in monocular images
- Self-supervised approach which doesnt require any human road annotations on images to train the road detection algorithm
- First, they automatically generate training drivable road area annotations for images using noisy OpenStreetMap data, vehicle pose estimation sensors (GPS and IMU) on the vehicle, and camera parameters
- Next, they train a Convolutional Neural Network using these noisy labels for road detection
- Outperforms all the methods which do not require human effort for image labeling
- Evaluates on KITTI dataset
| Semantic Segmentation Methods | |||
|
ECCV 2010
Ladicky2010ECCV | |||

- The methods so far consider each object class independently while the co-occurrence of object classes can be an important clue for semantic segmentation.
- For example cars are more likely to occur in a street scene than in an office.
- Consequently, this paper proposes to incorporate object class co-occurrence as global potentials in a CRF.
- They show how these potentials can be efficiently optimized using a graph cut algorithm and demonstrate improvements over simpler pairwise models.
- The CRF model uses a novel formulation that allows context to be incorporated at multiple levels of multiple quantisation.
- Evaluate performance on MSRC and VOC 2009 datasets.
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
PAMI 2010
Lafarge2010PAMI | |||
- 3D reconstruction of complex buildings and dense urban areas from a single Digital Surface Model (DSM)
- Buildings as an assemblage of simple urban structures extracted from a library of 3D parametric blocks (like Lego pieces)
- Steps:
- Extraction of 2D-supports of the urban structures (interactively or automatically)
- 3D-blocks are positioned on the 2D-supports using a Gibbs model
- MCMC sampler to find the optimal configuration of 3D-blocks associated with original proposition kernels
- Validated in a wide resolution interval such as 0.7 m satellite and 0.1 m aerial DSMs
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
PAMI 2013
Lafarge2013PAMI | |||
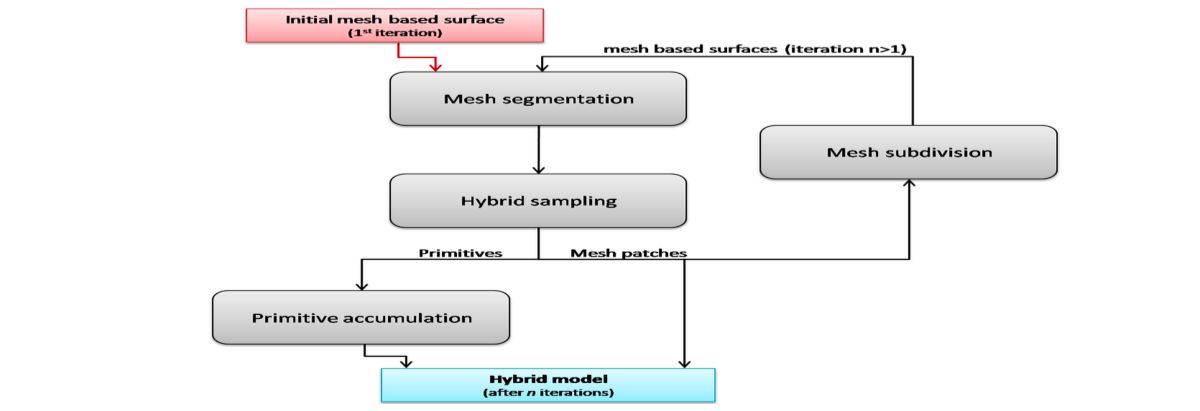
- Presents an original multi-view stereo reconstruction algorithm which allows the 3D-modeling of urban scenes as a combination of meshes and geometric primitives
- Contributions:
- Hybrid modeling by generating meshes where primitives are then inserted or by detecting primitives and then meshing the unfitted parts of the scene
- The lack of information contained in the images is compensated by the introduction of urban knowledge in the stochastic model
- Efficient global optimization by performing the sampling of both 3D-primitives and meshes by a Jump-Diffusion based algorithm
- Evaluates on Entry-P10, Herz-Jesu-P25 and Church datasets
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
ICRA 2011
Lategahn2011ICRA | |||
- Propose a dense stereo V-SLAM algorithm that estimates a dense 3D map representation which is more accurate than raw stereo measurements
- Runs a sparse V- SLAM system, take the resulting pose estimates to compute a locally dense representation from dense stereo correspondences
- Expresses this dense representation in local coordinate systems which are tracked as part of the SLAM estimate
- The sparse part of the SLAM system uses sub mapping techniques to achieve constant runtime complexity most of the time
- Evaluates on outdoor experiments of a car like robot.
| Datasets & Benchmarks | |||
|
ARXIV 2015
Leal-Taixe2015ARXIV | |||
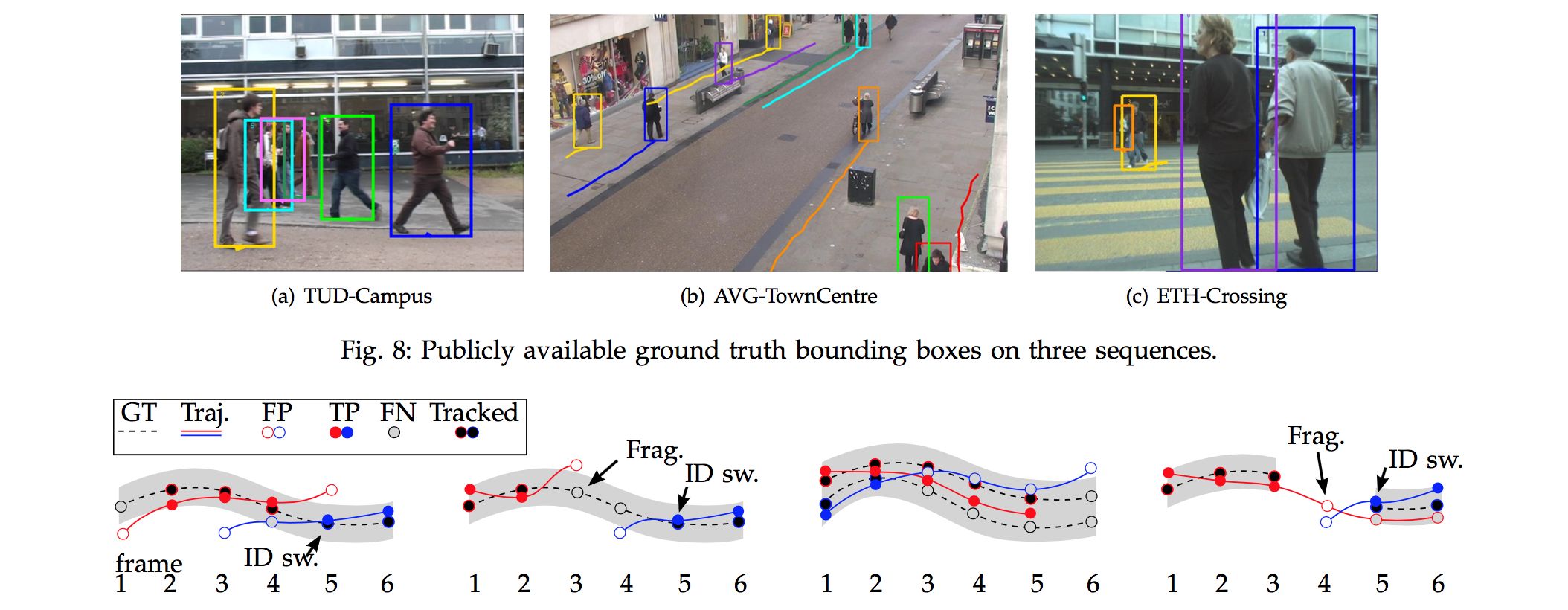
- Multiple object tracking (MOT) benchmark
- Collecting existing and new data
- Testing state-of-the-art methods on the datasets
- Creating a unified and centralized evaluation system
- 22 sequences, half for training and half for testing, with a total of 11286 frames
- Pre-computed object detections are provided.
- Discussing the strengths and weaknesses of multi-target tracking methods
| Datasets & Benchmarks Computer Vision Datasets | |||
|
ARXIV 2015
Leal-Taixe2015ARXIV | |||
- Multiple object tracking (MOT) benchmark
- Collecting existing and new data
- Testing state-of-the-art methods on the datasets
- Creating a unified and centralized evaluation system
- 22 sequences, half for training and half for testing, with a total of 11286 frames
- Pre-computed object detections are provided.
- Discussing the strengths and weaknesses of multi-target tracking methods
| Object Tracking Datasets | |||
|
ARXIV 2015
Leal-Taixe2015ARXIV | |||
- Multiple object tracking (MOT) benchmark
- Collecting existing and new data
- Testing state-of-the-art methods on the datasets
- Creating a unified and centralized evaluation system
- 22 sequences, half for training and half for testing, with a total of 11286 frames
- Pre-computed object detections are provided.
- Discussing the strengths and weaknesses of multi-target tracking methods
| Object Tracking Metrics | |||
|
ARXIV 2015
Leal-Taixe2015ARXIV | |||
- Multiple object tracking (MOT) benchmark
- Collecting existing and new data
- Testing state-of-the-art methods on the datasets
- Creating a unified and centralized evaluation system
- 22 sequences, half for training and half for testing, with a total of 11286 frames
- Pre-computed object detections are provided.
- Discussing the strengths and weaknesses of multi-target tracking methods
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
CVPR 2013
Lee2013CVPR | |||
- Visual ego-motion estimation algorithm for self-driving car
- Modeling multi-camera system as a generalized camera
- Applying non-holonomic motion constraint of a car (Ackerman motion model)
- Novel 2-point minimal solution for the generalized essential matrix
- General case with at least one inter-camera correspondence and special case with only intra-camera correspondences
- Efficient implementation within RANSAC for robust estimation
- Comparison on a large real-world dataset with minimal overlapping field-of-views against GPS/INS ground truth
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
IROS 2013
Lee2013IROS | |||
- Proposes a method to compute the pose-graph loop-closure constraints using multiple overlapping field-of-views cameras mounted on a self-driving car
- Contributions:
- Shows that the relative pose for the loop-closure constraint can be computed directly from the epipolar geometry of a multi-camera system
- Avoids the additional time complexities from the reconstruction of 3D scene points
- Provides greater flexibility in choosing a configuration for the multi-camera system to cover a wider field-of-view to avoid missing out any loop-closure opportunities
- Evaluates on ParkingGarage01, ParkingGarage02 and Campu01 datasets
| Mapping, Localization & Ego-Motion Estimation Metrics | |||
|
IROS 2013
Lee2013IROS | |||
- Proposes a method to compute the pose-graph loop-closure constraints using multiple overlapping field-of-views cameras mounted on a self-driving car
- Contributions:
- Shows that the relative pose for the loop-closure constraint can be computed directly from the epipolar geometry of a multi-camera system
- Avoids the additional time complexities from the reconstruction of 3D scene points
- Provides greater flexibility in choosing a configuration for the multi-camera system to cover a wider field-of-view to avoid missing out any loop-closure opportunities
- Evaluates on ParkingGarage01, ParkingGarage02 and Campu01 datasets
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
CVPR 2014
Lee2014CVPR | |||
- Relative pose estimation of a multi-camera system with known vertical directions (known absolute roll and pitch angles)
- Problems with the previous approaches:
- The high number of correspondences needed
- Identifying the correct solution from many solutions
- Strict assumption on the planarity of ground
- Minimal 4-point and linear 8-point algorithms within RANSAC
- 4-point algorithm
- Hidden variable resultant method
- 8-degree univariate polynomial that gives up to 8 real solutions
- Linear 8-point algorithm: an alternative solution for a degenerated case of SVD
- Four fish-eye cameras fixed onto a car for ego-motion estimation
- Evaluated on simulations and real-world datasets
| Object Tracking Methods | |||
|
CVPR 2007
Leibe2007CVPR | |||
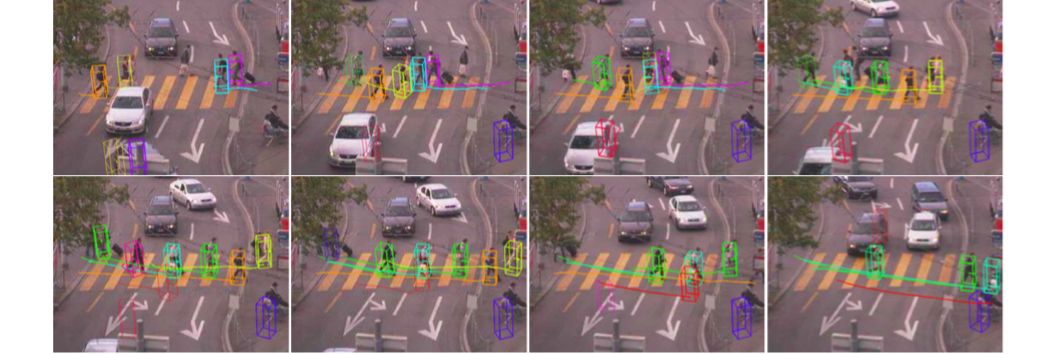
- Presents an integrated system for dynamic scene analysis on a mobile platform
- Contributions:
- Presents a multi-view/multi-category object detection module that can detect objects
- Shows how knowledge about the scene geometry can be used to improve recognition performance and to fuse the outputs of multiple detectors
- Demonstrates how 2D detections can be integrated over time to arrive at accurate 3D localization of static objects
- In order to deal with moving objects, proposes a tracking approach which formulates the tracking problem as space-time trajectory analysis followed by hypothesis selection.
- Evaluates on 2 video sequence datasets introduced in the paper
| Object Detection Methods | |||
|
IJCV 2008
Leibe2008IJCV | |||
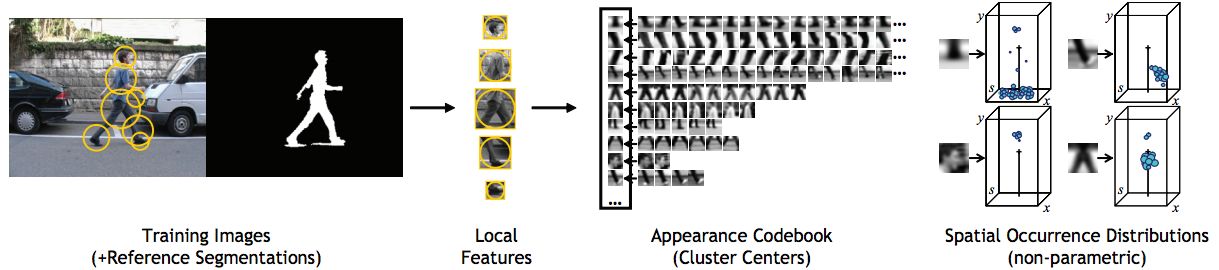
- Proposes a method for learning the appearance and spatial structure of a visual object category in order to recognize novel objects of that category, localize them in cluttered real-world scenes, and automatically segment them from the background
- Addresses object detection and segmentation not as separate entities, but as two closely collaborating processes
- Presents a local-feature based approach that combines both capabilities into a common probabilistic framework
- Initial recognition phase initializes the top-down segmentation process with a possible object location
- segmentation permits the recognition stage to focus its effort on object pixels and discard misleading influences from the background
- Uses segmentation in turn to improve recognition
- Evaluates on UIUC Cars, CalTech Cars,TUD Motorbikes, VOC05 Motorbikes, Leeds Cows, TUD Pedestrians datasets
| Object Tracking Methods | |||
|
PAMI 2008
Leibe2008PAMI | |||
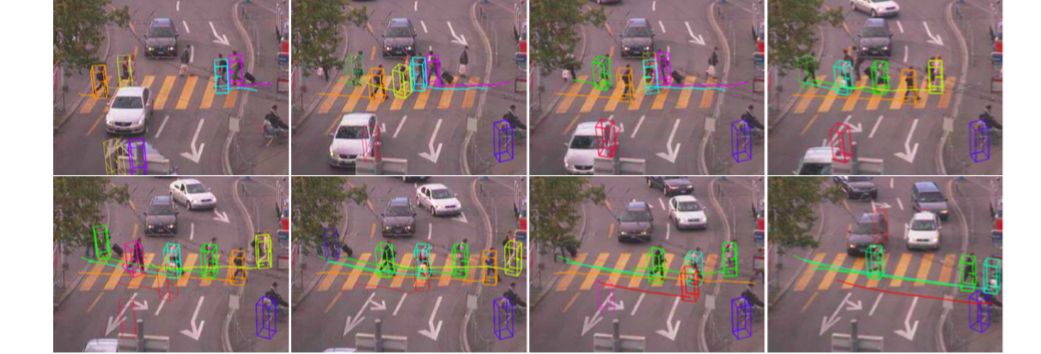
- Builds an integrated system for dynamic 3D scene analysis from a moving platform
- Presents a novel approach for multi-object tracking integrating recognition, re-construction & tracking in a collaborative framework
- Contributions:
- Uses SfM to estimate scene geometry at each time step
- Uses recognition to pick out objects of interest & separate them from the dynamically changing background
- Uses the output of multiple single-view object detectors & integrates continuously reestimated scene geometry constraints
- Uses tracking for temporal context to individual object detections
- Evaluates on 2 video sequence datasets introduced in the paper
| Object Tracking State of the Art on MOT & KITTI | |||
|
ICCV 2015
Lenz2015ICCV | |||
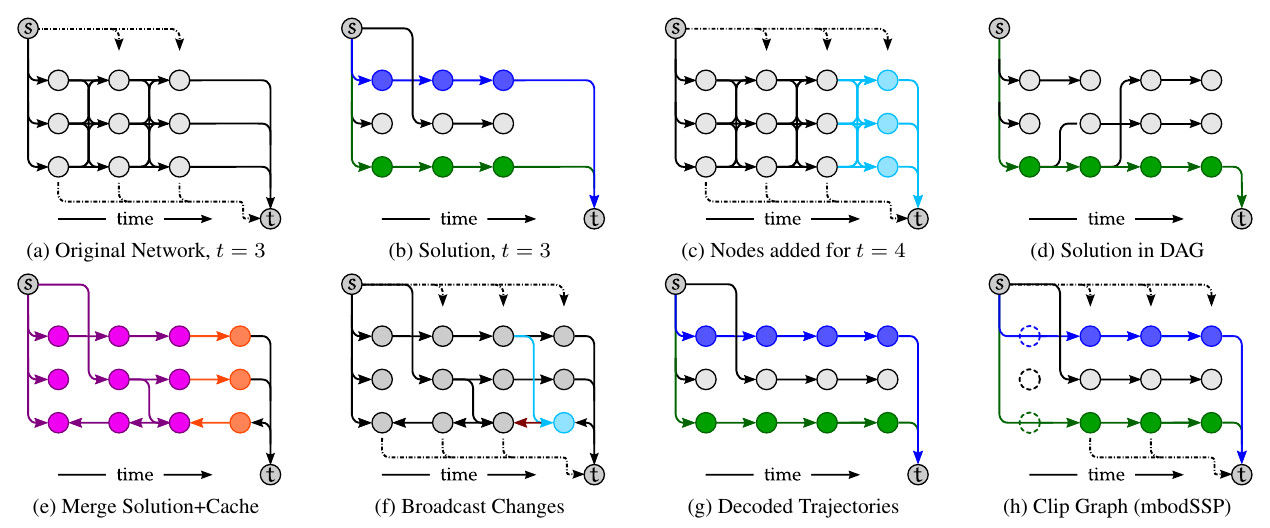
- Limitations of min-cost flow formulations for tracking-by-detection (eg, Nevatia):
- Require whole video as batch (no online computation)
- Scale badly in memory and computation
- Contributions:
- Dynamic successive shortest path algorithm & extension to online processing
- Approximate solver with bounded memory and computation
- Evaluation on KITTI 2012 and PETS 2009 benchmarks
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
RSS 2013
Leutenegger2013RSS | |||
- A joint non-linear cost function to optimize an IMU error + landmark reprojection error in a fully probabilistic manner
- Non-linear optimization approaches vs. filtering schemes
- Tightly coupled vs. loosely coupled approaches for visual-inertial fusion
- Marginalization of old states to maintain a bounded-sized optimization window for real-time performance
- A fully probabilistic derivation of IMU error terms, including the respective information matrix
- Building a pose graph without expressing global pose uncertainty
- Both the hardware and the algorithms for accurate real-time SLAM, including robust keypoint matching and outlier rejection using inertial cues
- Evaluated using a stereo-camera/IMU setup
| Semantic Segmentation Methods | |||
|
BMVC 2015
Levi2015BMVC | |||
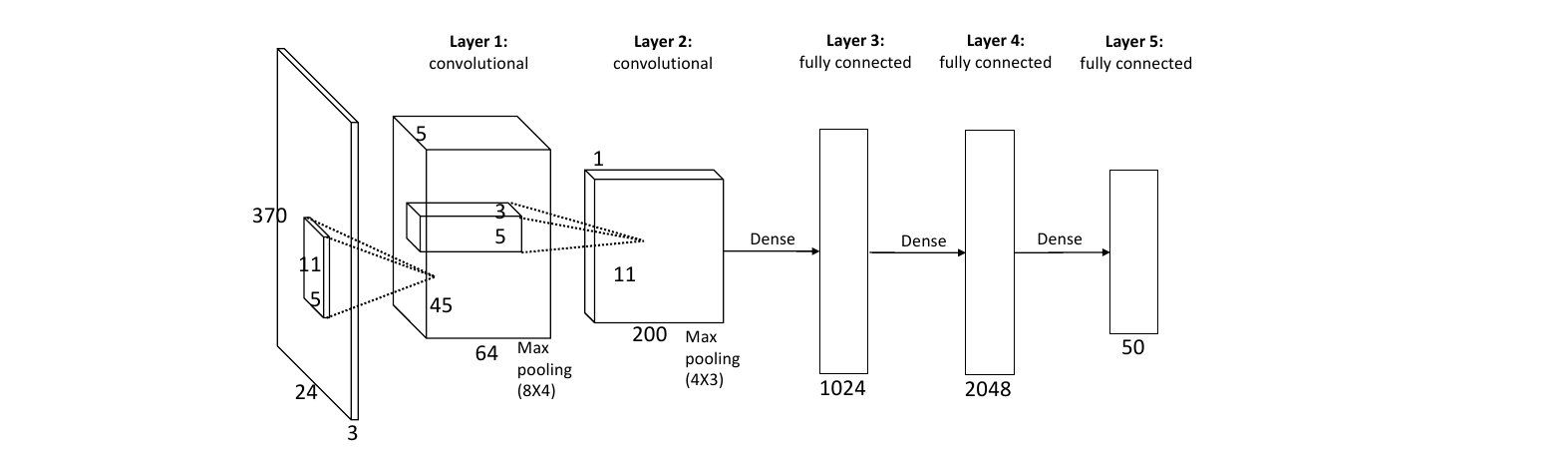
- Obstacle avoidance for mobile robotics and autonomous driving
- Detection of the closest obstacle in each direction from a driving vehicle using single color camera
- Reduction of the problem in a column-wise regression problem solved with a deep CNN
- Divide the image into columns
- For each column the network estimates the pixel location of the bottom point of the closest obstacle
- Loss function based on a semi-discrete representation of the obstacle position probability
- Trained with ground truth generated from laser-scanner point cloud
- Outperforms existing camera-based methods including ones using stereo on KITTI
- Achieving among the best results for road segmentation on KITTI
| Object Detection Methods | |||
|
RSS 2016
Li2016RSS | |||
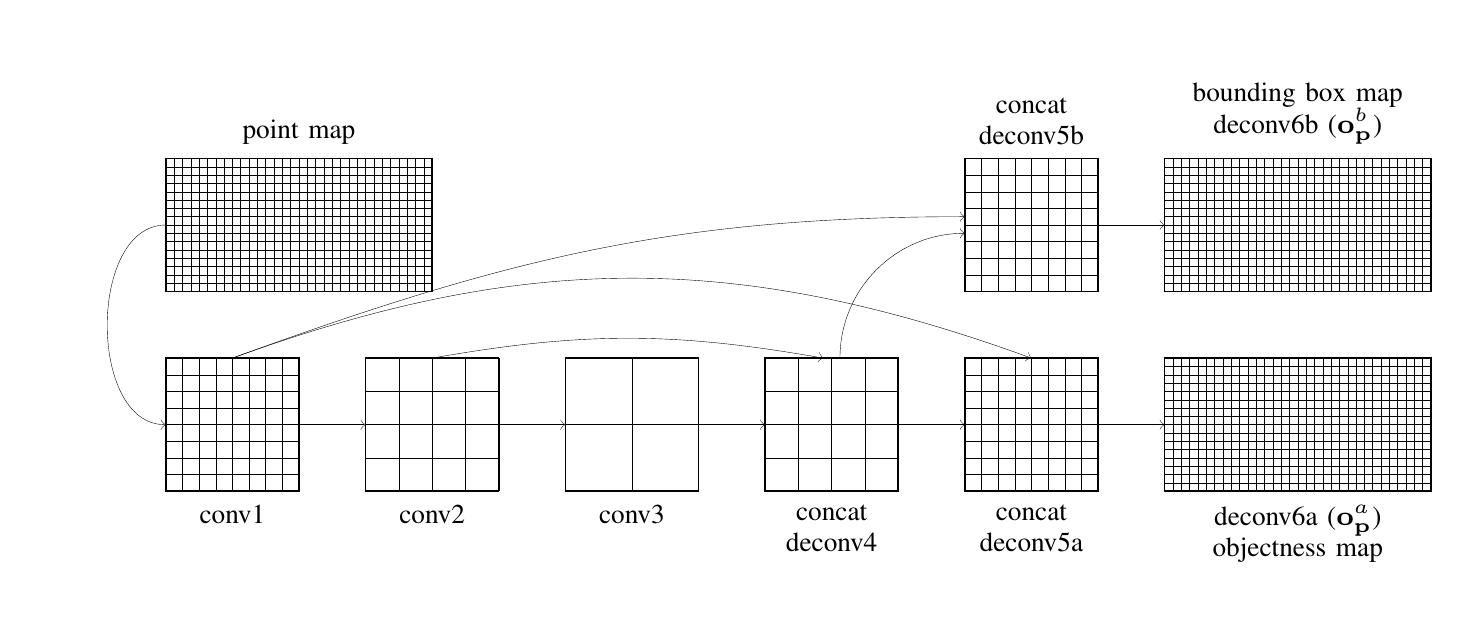
- Transferring fully convolutional network techniques to the vehicle detection task from the range data of Velodyne Lidar
- Representing the data in a 2D point map
- Using single 2D end-to-end fully convolutional network to predict the objectness confidence and bounding box simultaneously
- Bounding box encoding allows to predict full 3D bounding boxes even with 2D CNN
- State-of-the-art performance on KITTI dataset
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
ICCV 2009
Li2009ICCV | |||

- Landmark classification on geotagged photos from Flickr
- 30 million images, 2 million of which labeled into one of 500 categories
- Bag-of-word models using structured SVM classifiers with vector-quantized SIFT features
- Structured SVM to predict the sequence of category labels for a photo stream
- Accuracy comparable to that of humans
- Textual tags and temporal constraints leads to significant improvements in classification rate.
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
ECCV 2012
Li2012ECCV | |||
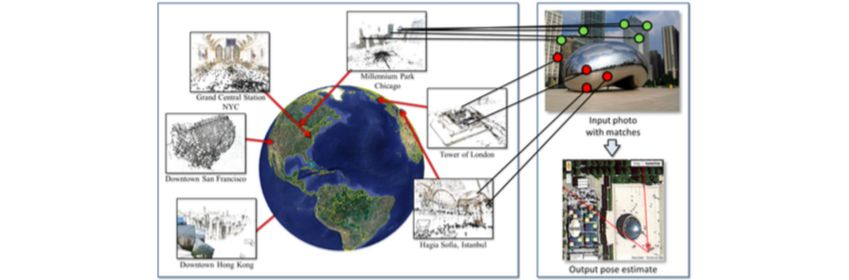
- Addresses the problem of determining where a photo was taken by estimating a full 6-DOF-plus-intrincs camera pose with respect to a large geo-registered 3D point cloud
- Contributions:
- Observes that 3D points produced by SfM methods often have strong co-occurrence relationships
- Finds such statistical co-occurrences by analyzing the large numbers of images in 3D SfM models
- Presents a bidirectional matching scheme aimed at boosting the recovery of true correspondences between image features and model points
- Evaluates on Landmarks, San Francisco, Quad datasets
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
CVPR 2013
Lin2013CVPR | |||
- Current approach to image geolocalization problem:
- By matching the query image to a database of georeferenced photographs
- Only works for famous landmarks, but not for the unremarkable scenes
- Relationship between aerial view and ground-level data
- Overhead appearance and land cover survey data
- Densely available for nearly all of the Earth
- Rich enough for unambiguous matching
- A cross-view feature translation approach
- A new dataset with ground-level, aerial, and land cover attribute images for training
- An aerial image classifier based on ground level scene matches
- Output of a query: a probability density over the region of interest
- Experiments over a 1600 km^2 region containing a variety of scenes and land cover types
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
CVPR 2015
Lin2015CVPR | |||

- Presents the first general technique for the challenging problem of matching street-level and aerial view images and evaluated it for the task of image geolocalizaiton.
- Contributions:
- Localizes a photo without using ground-level reference imagery by matching to aerial imagery
- Presents a novel method to create a large-scale cross-view training dataset from public data sources
- Examine traditional computer vision features and several recent deep learning strategies in novel cross-domain learning task
- Evaluates on new introduced dataset of pairs of Google street-view images and their corresponding aerial images
| Datasets & Benchmarks | |||
|
ECCV 2014
Lin2014ECCV | |||

- New dataset to advance state-of-the-art in object recognition, segmentation and captioning
- Collection of images of complex everyday scenes containing common objects in their natural context
- Objects are labeled using per-instance segmentations
- Dataset contains photos of 91 objects types with a total of 2.5 million labeled instances in 328k images
- Extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation
- Detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet and Sun
- Baseline performance analysis for bounding box and segmentation detection using Deformable Parts Model
| Datasets & Benchmarks Computer Vision Datasets | |||
|
ECCV 2014
Lin2014ECCV | |||
- New dataset to advance state-of-the-art in object recognition, segmentation and captioning
- Collection of images of complex everyday scenes containing common objects in their natural context
- Objects are labeled using per-instance segmentations
- Dataset contains photos of 91 objects types with a total of 2.5 million labeled instances in 328k images
- Extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation
- Detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet and Sun
- Baseline performance analysis for bounding box and segmentation detection using Deformable Parts Model
| Object Detection Datasets | |||
|
ECCV 2014
Lin2014ECCV | |||
- New dataset to advance state-of-the-art in object recognition, segmentation and captioning
- Collection of images of complex everyday scenes containing common objects in their natural context
- Objects are labeled using per-instance segmentations
- Dataset contains photos of 91 objects types with a total of 2.5 million labeled instances in 328k images
- Extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation
- Detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet and Sun
- Baseline performance analysis for bounding box and segmentation detection using Deformable Parts Model
| Semantic Segmentation Datasets | |||
|
ECCV 2014
Lin2014ECCV | |||
- New dataset to advance state-of-the-art in object recognition, segmentation and captioning
- Collection of images of complex everyday scenes containing common objects in their natural context
- Objects are labeled using per-instance segmentations
- Dataset contains photos of 91 objects types with a total of 2.5 million labeled instances in 328k images
- Extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation
- Detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet and Sun
- Baseline performance analysis for bounding box and segmentation detection using Deformable Parts Model
| Semantic Instance Segmentation Methods | |||
|
ECCV 2014
Lin2014ECCV | |||
- New dataset to advance state-of-the-art in object recognition, segmentation and captioning
- Collection of images of complex everyday scenes containing common objects in their natural context
- Objects are labeled using per-instance segmentations
- Dataset contains photos of 91 objects types with a total of 2.5 million labeled instances in 328k images
- Extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation
- Detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet and Sun
- Baseline performance analysis for bounding box and segmentation detection using Deformable Parts Model
| Semantic Instance Segmentation Datasets | |||
|
ECCV 2014
Lin2014ECCV | |||
- New dataset to advance state-of-the-art in object recognition, segmentation and captioning
- Collection of images of complex everyday scenes containing common objects in their natural context
- Objects are labeled using per-instance segmentations
- Dataset contains photos of 91 objects types with a total of 2.5 million labeled instances in 328k images
- Extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation
- Detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet and Sun
- Baseline performance analysis for bounding box and segmentation detection using Deformable Parts Model
| Semantic Instance Segmentation Metrics | |||
|
ECCV 2014
Lin2014ECCV | |||
- New dataset to advance state-of-the-art in object recognition, segmentation and captioning
- Collection of images of complex everyday scenes containing common objects in their natural context
- Objects are labeled using per-instance segmentations
- Dataset contains photos of 91 objects types with a total of 2.5 million labeled instances in 328k images
- Extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation
- Detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet and Sun
- Baseline performance analysis for bounding box and segmentation detection using Deformable Parts Model
| Semantic Instance Segmentation State of the Art on Cityscapes | |||
|
ECCV 2014
Lin2014ECCV | |||
- New dataset to advance state-of-the-art in object recognition, segmentation and captioning
- Collection of images of complex everyday scenes containing common objects in their natural context
- Objects are labeled using per-instance segmentations
- Dataset contains photos of 91 objects types with a total of 2.5 million labeled instances in 328k images
- Extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation
- Detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet and Sun
- Baseline performance analysis for bounding box and segmentation detection using Deformable Parts Model
| Semantic Segmentation Methods | |||
|
CVPR 2015
Long2015CVPR | |||
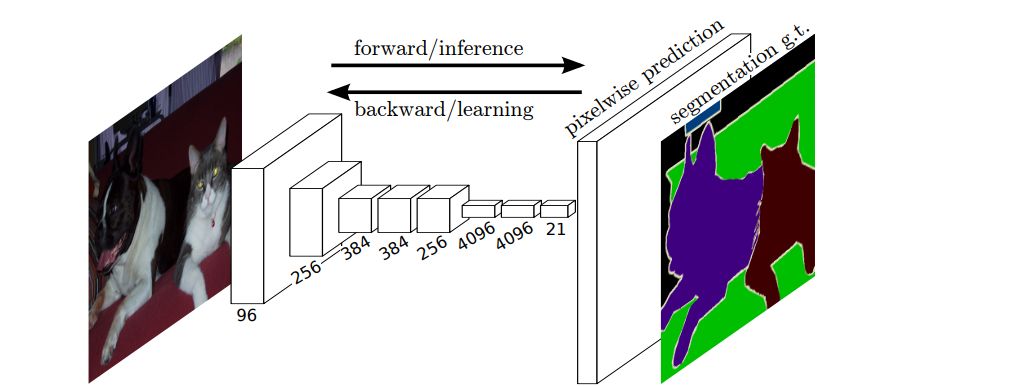
- First work to train FCNs end-to-end for pixelwise prediction.
- The network predict dense outputs from arbitrary-sized inputs.
- Both learning and inference are performed whole image at a time by dense feed forward computation and backpropagation.
- In-network upsampling layers enable pixelwise prediction and learning in nets with subsampled pooling.
- Show that a fully convolutional network trained end-to-end, pixels-to-pixels on semantic segmentation exceeds the state-of-the-art without further machinery.
- Demonstrate performance on PASCAL VOC 2011-2, NYUDv2, and SIFT Flow.
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
Nature 1981
Longuet-Higgins1981Nature | |||
| Object Detection Methods | |||
|
SIGGRAPH 2015
Loper2015SIGGRAPH | |||
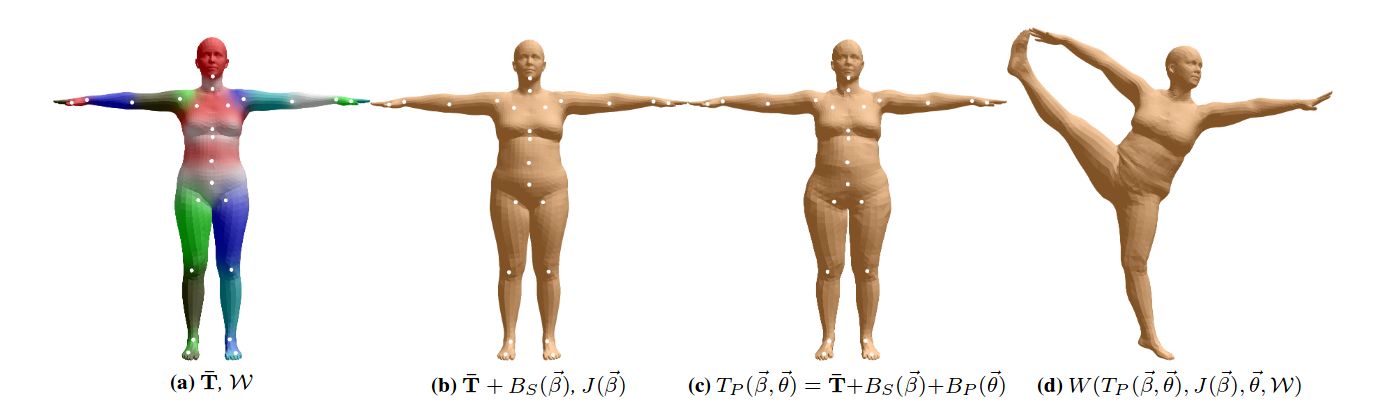
- Learned model of human body shape and pose dependent shap variation
- More accurate than previous models and compatible wit existing graphics pipelines
- Skinned Multi Person Linear model (SMPL) is a skinned vertex-based model
- Parameters of model are learned from data including rest pose template, blend weights, pose-dependent blend shapes, identity-dependent blend shapes and regressors from vertices to joint locations
- Using linear or dual-quaternion blend skinning outperforms a Blend-SCAPE model
- Extend SMPL to realistically model dynamic soft-tissue deformations
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
SIGGRAPH 1987
Lorensen1987SIGGRAPH | |||
- Marching cubes: triangle models of density surfaces from 3D data
- Goal: to locate the surface in a logical cube created from eight pixels; four each from two adjacent slices
- Based on how the surface intersects a cube, then moving (or marching) to the next cube
- Enumerating 256 ways a surface can intersect the cube
- Reducing from 256 cases to 14 patterns using two different symmetries of the cube
- An index as a pointer into an edge table that gives all edge intersections for a given cube configuration
- Using the index to tell which edge the surface intersects
- Initially proposed for medical data
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
TR 2016
Lowry2016TR | |||
- A comprehensive review of the current state of place recognition research, including its relationship with SLAM, localization, mapping, and recognition
- Introducing the concepts behind place recognition
- The role of place recognition in the animal kingdom
- How a "place" is defined in a robotics context
- The major components of a place recognition system
- Discussing how place recognition solutions can implicitly or explicitly account for appearance change within the environment
- A discussion on the future of visual place recognition with respect to advances in deep learning, semantic scene understanding, and video description
| Stereo Methods | |||
|
CVPR 2016
Luo2016CVPR | |||
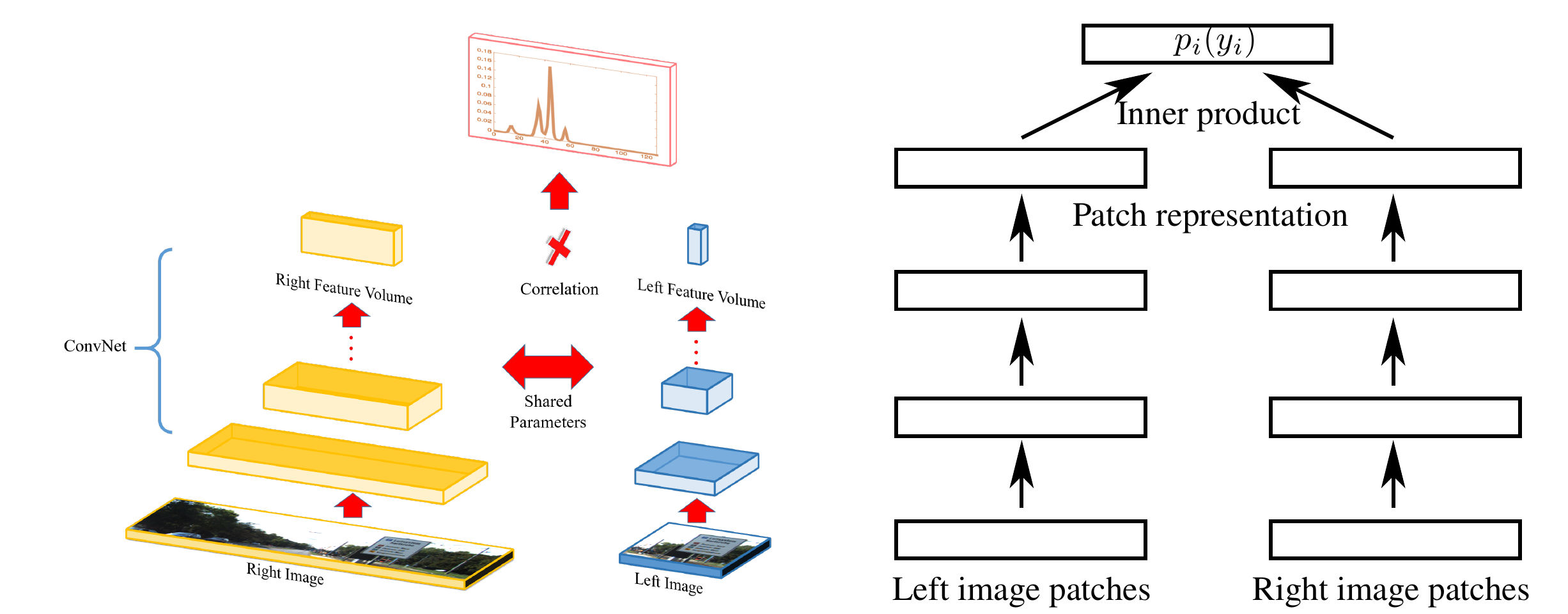
- Siamese networks for stereo perform well but are slow
- They propose a very fast matching network
- Product layer between the siamese networks instead of concatenation
- Consider multi-class classification problem with the possible disparities as classes
- Calibrated scores allow to outperform existing approaches
- Consider several MRFs for smoothing the matching results (cost aggregation, semi global block matching and slanted plane)
- Evaluation on KITTI 2012 and 2015 benchmarks
| 3D Scene Flow Methods | |||
|
ECCV 2016
Lv2016ECCV | |||
- Dynamic 3D scene as a collection of rigidly moving planar segments
- Previous work: discrete-continuous optimization problem
- Proposed: A purely continuous formulation which can be solved more efficiently
- A factor graph formulation that decomposes the problem into photometric, geometric, and smoothing constraints
- High-quality initialization
- Refining the geometry and motion of the scene followed by a global nonlinear refinement using Levenberg-Marquard
- Evaluated on KITTI Scene Flow benchmark
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
RSS 2015
Lynen2015RSS | |||
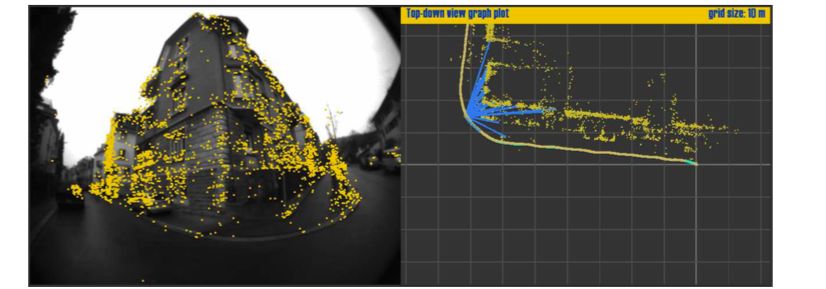
- Demonstrates that large-scale, real-time pose estimation and tracking can be performed on mobile platforms with limited resources without the use of an external server
- Contributions:
- Proposes a large-scale system that entirely runs on devices with limited computational & memory resources while offering accurate, real-time localization
- Proposes a direct inclusion of 2D-3D matches from global localization into the local visual-inertial estimator
- Leads to smoother trajectories & faster run-times compared to sliding window Bundle Adjustment
- Evaluates on dataset introduced in the paper
| Optical Flow Methods | |||
|
PAMI 2013
MacAodha2013PAMI | |||

- Presents a supervised learning based method to estimate a per-pixel confidence for optical flow vectors
- Contributions:
- Evaluates the proposed optical flow confidence measure on new flow algorithms & several new sequences
- Compares to other confidence measures
- Proposes separate confidence in X and Y directions
- improves accuracy for optical flow by automatically combining known constituent algorithms
- Evaluates on Middlebury sequences and synthetic sequences introduced in the paper
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
IJRR 2016
Maddern2016IJRR | |||
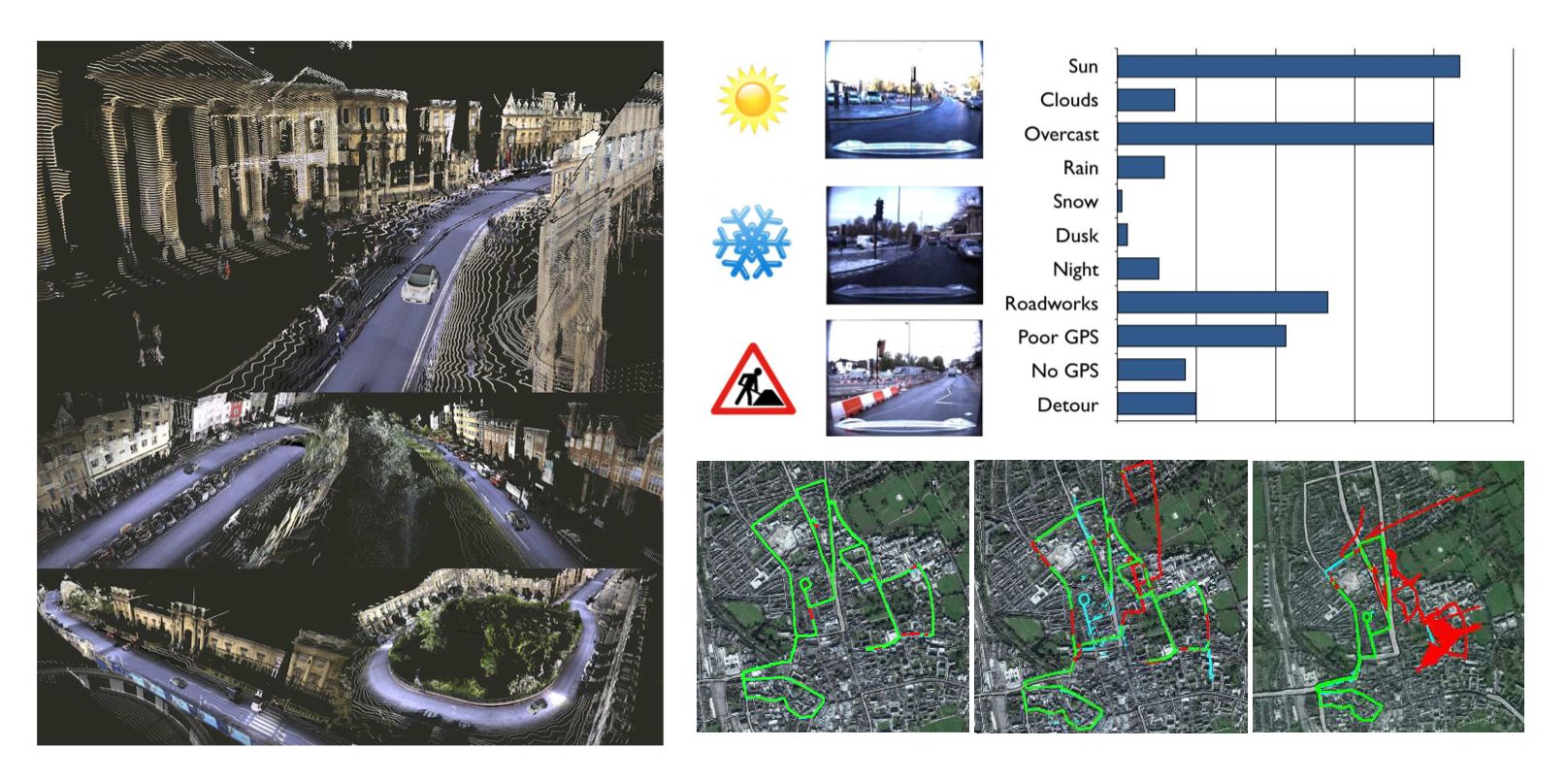
- The Oxford RobotCar Dataset for autonomous driving
- 1000km of recorded driving with almost 20 million images collected from 6 cameras mounted to the vehicle, along with LIDAR, GPS and INS ground truth
- Diverse weather conditions, including heavy rain, night, direct sunlight and snow
- Recording significant changes on road and building works over a year
- Goal: long-term localization and mapping for autonomous vehicles in real-world, dynamic urban environments
| Mapping, Localization & Ego-Motion Estimation Datasets | |||
|
IJRR 2016
Maddern2016IJRR | |||
- The Oxford RobotCar Dataset for autonomous driving
- 1000km of recorded driving with almost 20 million images collected from 6 cameras mounted to the vehicle, along with LIDAR, GPS and INS ground truth
- Diverse weather conditions, including heavy rain, night, direct sunlight and snow
- Recording significant changes on road and building works over a year
- Goal: long-term localization and mapping for autonomous vehicles in real-world, dynamic urban environments
| Semantic Segmentation Methods | |||
|
NIPS 2013
Mansinghka2013NIPS | |||
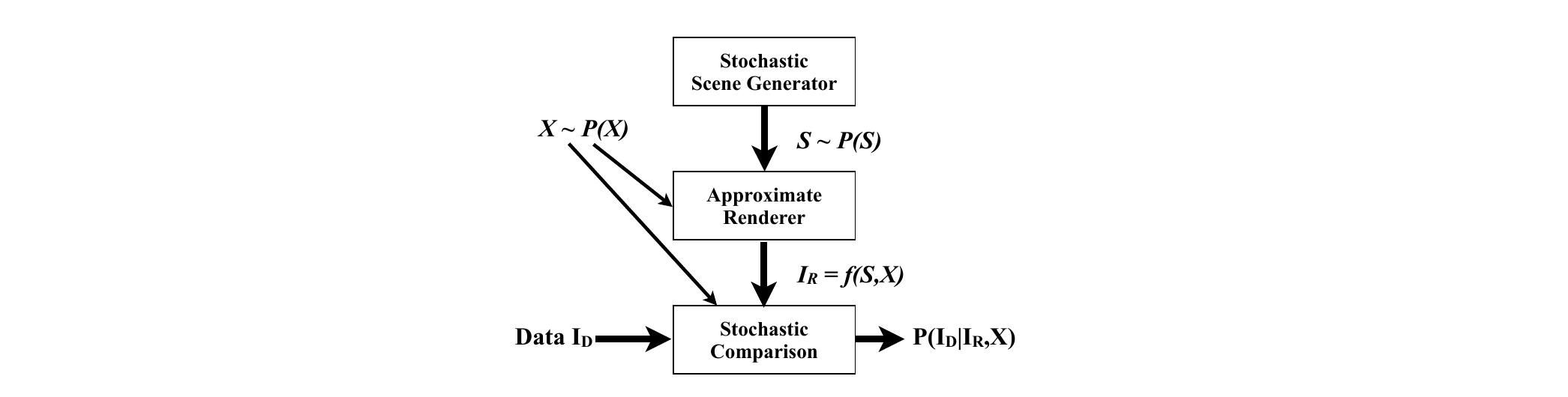
- Computer vision as Bayesian inverse problem to computer graphics has proved difficult to directly implement
- Short, simple probabilistic graphics programs that define flexible generative models and automatically invert them to interpret real-world images
- Generative probabilistic graphics programs consist of a stochastic scene generator, a renderer based on graphics software and a stochastic likelihood model
- Stochastic likelihood model links the renderer's output and the data
- Latent variables adjust the fidelity of the renderer and the tolerance of the likelihood
- Automatic Metropolis-Hastings transition operators are used to invert the probabilistic graphics programs
- Demonstration on reading sequence of degraded and adversarially obscured characters and inferring 3D road models (KITTI dataset)
| Semantic Segmentation Methods | |||
|
CVPR 2015
Martinovic2015CVPR | |||
- Semantic segmentation of 3D city models
- Starting from an SfM reconstruction, classification and facade modelling purely in 3D
- No need for slow image-based semantic segmentation methods
- High quality labellings, with significant speed benefits (20times faster, entire streets in a matter of minutes)
- Combining a state-of-the-art 2D classifier: further boosting the performance (slower)
- A novel facade separation based on the results of semantic facade analysis
- 3D-specific principles like alignment, symmetry in a framework optimized using integer quadratic programming formulation
- Evaluated on Rue-Monge2014
| Semantic Segmentation Methods | |||
|
IJCV 2016
Mathias2016IJCV | |||
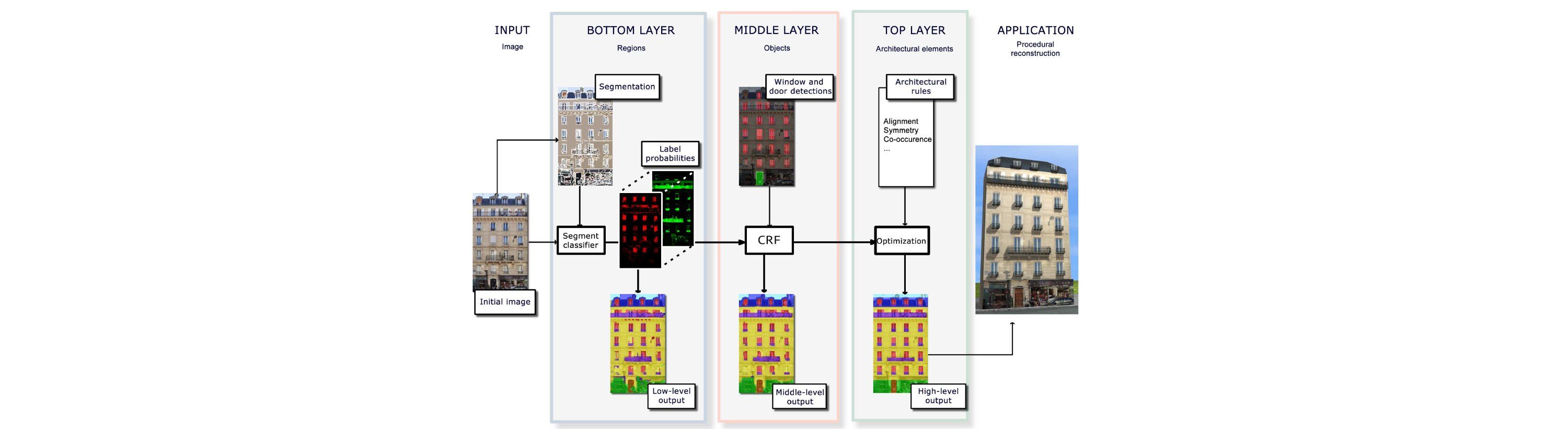
- Semantic segmentation of building facades
- Three distinct layers representing different levels of abstraction:
- Segmentation into regions with probability distribution over semantic classes
- Detect objects to improve initial labeling with object detector
- Combination of segmentation and object detection with a CRF
- Incorporate additional meta-knowledge in form of weak architectural principles which enforces architectural plausibility
- Outperform state-of-the-art on ECP and eTRIMS dataset
- Output of highest layer used for procedural building reconstruction
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
CVPR 2016
Mattyus2016CVPR | |||
- Fine-grained segmentation for fully autonomous systems parking spots, side-walk, background, number and location of road lanes
- Alternatives:
- Many man-hours of laborious and tedious labelling
- Imagery/LIDAR from millions of cars
- Using monocular aerial imagery, topology of the road network from OpenStreetMap, and stereo images taken from a camera on top of a car
- Accurate alignment between two types of imagery
- A set of potentials exploiting semantic cues, road constraints, relationships between parallel roads, and smoothness assumptions
- Enhancing KITTI with aerial images: Air-Ground-KITTI
- Significantly reduced alignment error compared to a GPS+IMU system
| Semantic Segmentation Methods | |||
|
CVPR 2016
Mattyus2016CVPR | |||
- Fine-grained segmentation for fully autonomous systems parking spots, side-walk, background, number and location of road lanes
- Alternatives:
- Many man-hours of laborious and tedious labelling
- Imagery/LIDAR from millions of cars
- Using monocular aerial imagery, topology of the road network from OpenStreetMap, and stereo images taken from a camera on top of a car
- Accurate alignment between two types of imagery
- A set of potentials exploiting semantic cues, road constraints, relationships between parallel roads, and smoothness assumptions
- Enhancing KITTI with aerial images: Air-Ground-KITTI
- Significantly reduced alignment error compared to a GPS+IMU system
| Semantic Segmentation Methods | |||
|
ICCV 2015
Mattyus2015ICCV | |||
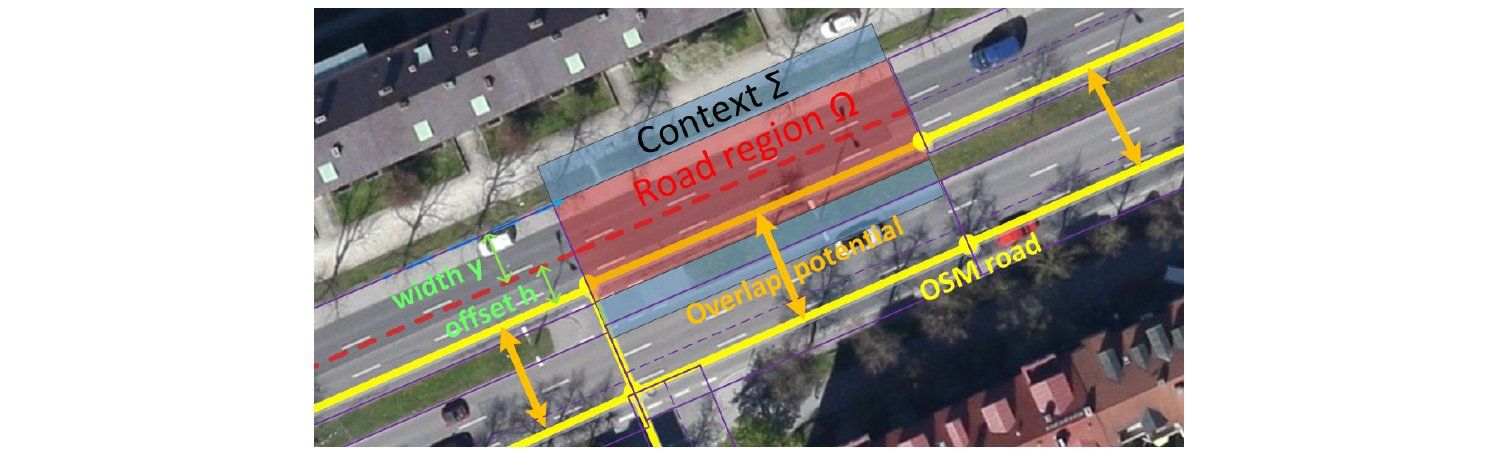
- Exploit aerial images in order to enhance freely available world maps (eg, with road geometry)
- Formulation as inference in a Markov random field
- Parametrized in terms of the location of road-segment centerlines and width
- Parametrization allows efficient inference and returns only topologically correct roads
- Energy encodes the appearance of roads, edge information, car detection, contextual features, relations between nearby roads as well as smoothness between the line segments
- All OpenStreetMaps roads in the whole world can be segmented in a single day using small cluster of 10 computers
- Good generalization: can be trained using only 1.5km^2 aerial imagery and produce very accurate results in any location across the world
- Outperforming state-of-the-art on two novel benchmarks
| Datasets & Benchmarks | |||
|
CVPR 2016
Mayer2016CVPR | |||

- Introduces a synthetic dataset containing over 35000 stereo image pairs with ground truth disparity, optical flow, and scene flow
- Synthetic dataset suite consists of three subsets
- FlyingThings3D is 25000 stereo frames with ground truth data of everyday objects flying along randomized 3D trajectories
- Monkaa contains nonrigid and softly articulated motion as well as visually challenging fur, made from the open source Blender assets of the animated short film Monkaa
- The Driving dataset is comprises naturalistic, dynamic street scenes from the viewpoint of a driving car, made to resemble the KITTI datasets
- Demonstrates that the dataset can indeed be used to successfully train large convolutional networks
| Datasets & Benchmarks Computer Vision Datasets | |||
|
CVPR 2016
Mayer2016CVPR | |||
- Introduces a synthetic dataset containing over 35000 stereo image pairs with ground truth disparity, optical flow, and scene flow
- Synthetic dataset suite consists of three subsets
- FlyingThings3D is 25000 stereo frames with ground truth data of everyday objects flying along randomized 3D trajectories
- Monkaa contains nonrigid and softly articulated motion as well as visually challenging fur, made from the open source Blender assets of the animated short film Monkaa
- The Driving dataset is comprises naturalistic, dynamic street scenes from the viewpoint of a driving car, made to resemble the KITTI datasets
- Demonstrates that the dataset can indeed be used to successfully train large convolutional networks
| Datasets & Benchmarks Synthetic Data Generation using Game Engines | |||
|
CVPR 2016
Mayer2016CVPR | |||
- Introduces a synthetic dataset containing over 35000 stereo image pairs with ground truth disparity, optical flow, and scene flow
- Synthetic dataset suite consists of three subsets
- FlyingThings3D is 25000 stereo frames with ground truth data of everyday objects flying along randomized 3D trajectories
- Monkaa contains nonrigid and softly articulated motion as well as visually challenging fur, made from the open source Blender assets of the animated short film Monkaa
- The Driving dataset is comprises naturalistic, dynamic street scenes from the viewpoint of a driving car, made to resemble the KITTI datasets
- Demonstrates that the dataset can indeed be used to successfully train large convolutional networks
| Stereo Methods | |||
|
CVPR 2016
Mayer2016CVPR | |||
- Introduces a synthetic dataset containing over 35000 stereo image pairs with ground truth disparity, optical flow, and scene flow
- Synthetic dataset suite consists of three subsets
- FlyingThings3D is 25000 stereo frames with ground truth data of everyday objects flying along randomized 3D trajectories
- Monkaa contains nonrigid and softly articulated motion as well as visually challenging fur, made from the open source Blender assets of the animated short film Monkaa
- The Driving dataset is comprises naturalistic, dynamic street scenes from the viewpoint of a driving car, made to resemble the KITTI datasets
- Demonstrates that the dataset can indeed be used to successfully train large convolutional networks
| Stereo Datasets | |||
|
CVPR 2016
Mayer2016CVPR | |||
- Introduces a synthetic dataset containing over 35000 stereo image pairs with ground truth disparity, optical flow, and scene flow
- Synthetic dataset suite consists of three subsets
- FlyingThings3D is 25000 stereo frames with ground truth data of everyday objects flying along randomized 3D trajectories
- Monkaa contains nonrigid and softly articulated motion as well as visually challenging fur, made from the open source Blender assets of the animated short film Monkaa
- The Driving dataset is comprises naturalistic, dynamic street scenes from the viewpoint of a driving car, made to resemble the KITTI datasets
- Demonstrates that the dataset can indeed be used to successfully train large convolutional networks
| Stereo State of the Art on KITTI | |||
|
CVPR 2016
Mayer2016CVPR | |||
- Introduces a synthetic dataset containing over 35000 stereo image pairs with ground truth disparity, optical flow, and scene flow
- Synthetic dataset suite consists of three subsets
- FlyingThings3D is 25000 stereo frames with ground truth data of everyday objects flying along randomized 3D trajectories
- Monkaa contains nonrigid and softly articulated motion as well as visually challenging fur, made from the open source Blender assets of the animated short film Monkaa
- The Driving dataset is comprises naturalistic, dynamic street scenes from the viewpoint of a driving car, made to resemble the KITTI datasets
- Demonstrates that the dataset can indeed be used to successfully train large convolutional networks
| Optical Flow Methods | |||
|
CVPR 2016
Mayer2016CVPR | |||
- Introduces a synthetic dataset containing over 35000 stereo image pairs with ground truth disparity, optical flow, and scene flow
- Synthetic dataset suite consists of three subsets
- FlyingThings3D is 25000 stereo frames with ground truth data of everyday objects flying along randomized 3D trajectories
- Monkaa contains nonrigid and softly articulated motion as well as visually challenging fur, made from the open source Blender assets of the animated short film Monkaa
- The Driving dataset is comprises naturalistic, dynamic street scenes from the viewpoint of a driving car, made to resemble the KITTI datasets
- Demonstrates that the dataset can indeed be used to successfully train large convolutional networks
| 3D Scene Flow Datasets | |||
|
CVPR 2016
Mayer2016CVPR | |||
- Introduces a synthetic dataset containing over 35000 stereo image pairs with ground truth disparity, optical flow, and scene flow
- Synthetic dataset suite consists of three subsets
- FlyingThings3D is 25000 stereo frames with ground truth data of everyday objects flying along randomized 3D trajectories
- Monkaa contains nonrigid and softly articulated motion as well as visually challenging fur, made from the open source Blender assets of the animated short film Monkaa
- The Driving dataset is comprises naturalistic, dynamic street scenes from the viewpoint of a driving car, made to resemble the KITTI datasets
- Demonstrates that the dataset can indeed be used to successfully train large convolutional networks
| Sensors Camera Models | |||
|
ICRA 2007
Mei2007ICRA | |||
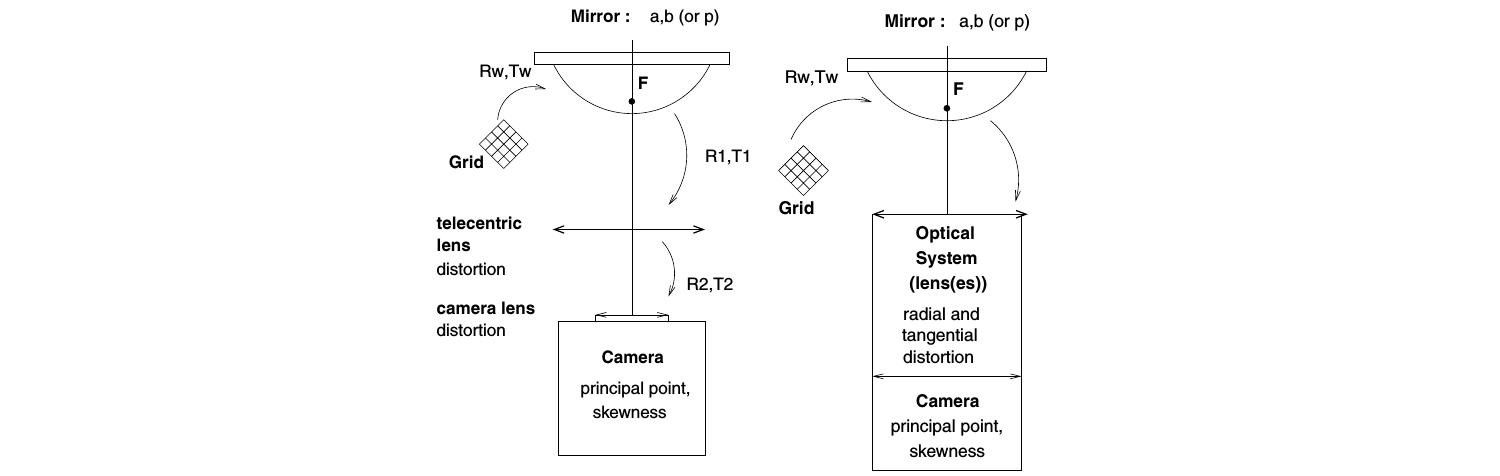
- Flexible approach for calibrating omnidirectional single viewpoint sensors from planar grids
- Based on exact theoretical projection function with added well identified parameters to model real-world errors
- Reduce large number of parameters necessary for Gonzalez-Barbosa method using the assumption that the errors are small due to the assembly of the system
- Using the unified model of Barreto-Geyer to obtain a calibration valid for all central catadioptric systems
- Selection of only four points necessary for the initialization of each calibration grid
- Validation with calibration of parabolic, hyperbolic, folded mirror, wide-angle and spherical sensors
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
CVPR 2015
Menze2015CVPR | |||
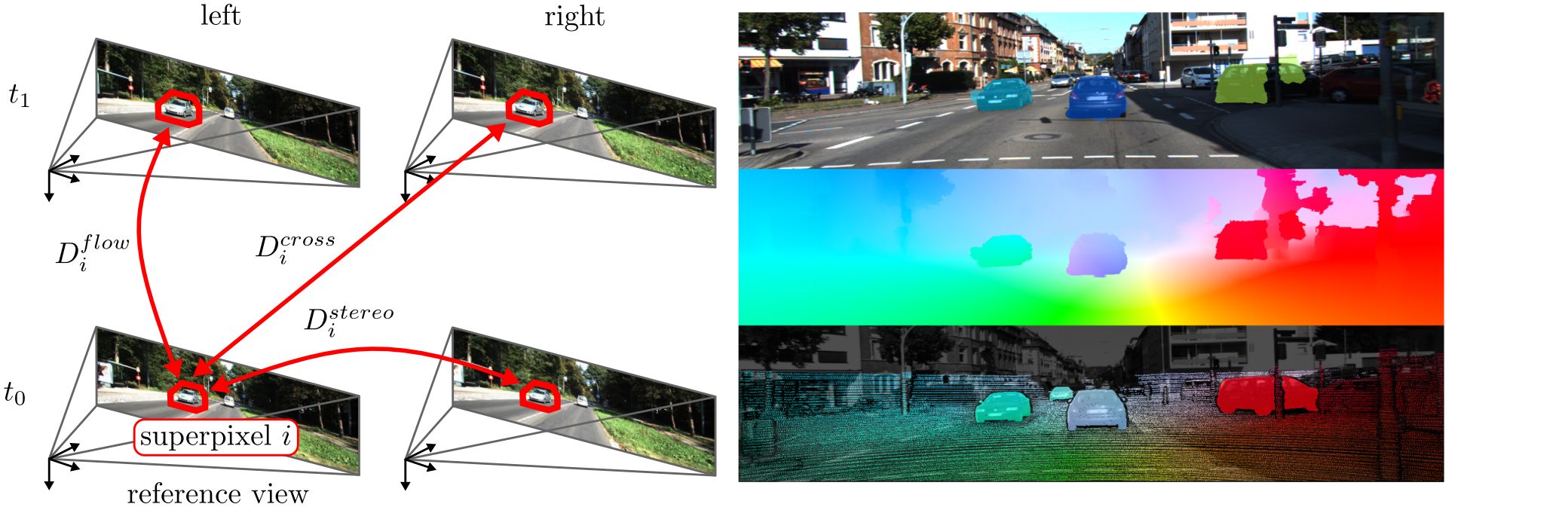
- Existing methods don't exploit fact that outdoor scenes can be decomposed into small number of independently moving 3D objects
- Absence of realistic benchmarks with scene flow ground truth
- Contributions:
- Exploits the decomposition of the scene as collection of rigid objects
- Reasoning jointly about this decomposition as well as the geometry and motion of objects in the scene
- Introduces the first realistic and large-scale scene flow dataset
- Evaluates on stereo and flow KITTI benchmarks
| Stereo Metrics | |||
|
CVPR 2015
Menze2015CVPR | |||
- Existing methods don't exploit fact that outdoor scenes can be decomposed into small number of independently moving 3D objects
- Absence of realistic benchmarks with scene flow ground truth
- Contributions:
- Exploits the decomposition of the scene as collection of rigid objects
- Reasoning jointly about this decomposition as well as the geometry and motion of objects in the scene
- Introduces the first realistic and large-scale scene flow dataset
- Evaluates on stereo and flow KITTI benchmarks
| Optical Flow Methods | |||
|
CVPR 2015
Menze2015CVPR | |||
- Existing methods don't exploit fact that outdoor scenes can be decomposed into small number of independently moving 3D objects
- Absence of realistic benchmarks with scene flow ground truth
- Contributions:
- Exploits the decomposition of the scene as collection of rigid objects
- Reasoning jointly about this decomposition as well as the geometry and motion of objects in the scene
- Introduces the first realistic and large-scale scene flow dataset
- Evaluates on stereo and flow KITTI benchmarks
| Optical Flow State of the Art on KITTI | |||
|
CVPR 2015
Menze2015CVPR | |||
- Existing methods don't exploit fact that outdoor scenes can be decomposed into small number of independently moving 3D objects
- Absence of realistic benchmarks with scene flow ground truth
- Contributions:
- Exploits the decomposition of the scene as collection of rigid objects
- Reasoning jointly about this decomposition as well as the geometry and motion of objects in the scene
- Introduces the first realistic and large-scale scene flow dataset
- Evaluates on stereo and flow KITTI benchmarks
| Optical Flow Discussion | |||
|
CVPR 2015
Menze2015CVPR | |||
- Existing methods don't exploit fact that outdoor scenes can be decomposed into small number of independently moving 3D objects
- Absence of realistic benchmarks with scene flow ground truth
- Contributions:
- Exploits the decomposition of the scene as collection of rigid objects
- Reasoning jointly about this decomposition as well as the geometry and motion of objects in the scene
- Introduces the first realistic and large-scale scene flow dataset
- Evaluates on stereo and flow KITTI benchmarks
| 3D Scene Flow Problem Definition | |||
|
CVPR 2015
Menze2015CVPR | |||
- Existing methods don't exploit fact that outdoor scenes can be decomposed into small number of independently moving 3D objects
- Absence of realistic benchmarks with scene flow ground truth
- Contributions:
- Exploits the decomposition of the scene as collection of rigid objects
- Reasoning jointly about this decomposition as well as the geometry and motion of objects in the scene
- Introduces the first realistic and large-scale scene flow dataset
- Evaluates on stereo and flow KITTI benchmarks
| 3D Scene Flow Methods | |||
|
CVPR 2015
Menze2015CVPR | |||
- Existing methods don't exploit fact that outdoor scenes can be decomposed into small number of independently moving 3D objects
- Absence of realistic benchmarks with scene flow ground truth
- Contributions:
- Exploits the decomposition of the scene as collection of rigid objects
- Reasoning jointly about this decomposition as well as the geometry and motion of objects in the scene
- Introduces the first realistic and large-scale scene flow dataset
- Evaluates on stereo and flow KITTI benchmarks
| 3D Scene Flow State of the Art on KITTI | |||
|
CVPR 2015
Menze2015CVPR | |||
- Existing methods don't exploit fact that outdoor scenes can be decomposed into small number of independently moving 3D objects
- Absence of realistic benchmarks with scene flow ground truth
- Contributions:
- Exploits the decomposition of the scene as collection of rigid objects
- Reasoning jointly about this decomposition as well as the geometry and motion of objects in the scene
- Introduces the first realistic and large-scale scene flow dataset
- Evaluates on stereo and flow KITTI benchmarks
| Optical Flow Methods | |||
|
GCPR 2015
Menze2015GCPR | |||
- Optical flow as a discrete inference problem in a CRF, followed by sub-pixel refinement
- Diverse (500) flow proposals by approximate nearest neighbour search based on appearance (Daisy), and by respecting NMS constraints
- Pre-computation of truncated pairwise potentials, further accelerated via hashing
- BCD by iteratively updating alternating image rows and columns
- Post-processing as forward backward consistency check and removing small segments
- Epic Flow for interpolation
- Evaluated on Sintel and KITTI benchmarks
| 3D Scene Flow Methods | |||
|
ISA 2015
Menze2015ISA | |||

- Existing slanted plane models for scene flow estimation only reason about segmentation and the motion of the vehicles in the scene
- Contributions:
- Jointly reasons about 3D scene flow as well as the pose, shape and motion of vehicles in the scene
- Incorporates a deformable CAD model into a slanted-plane CRF for scene flow estimation
- Enforces shape consistency between the rendered 3D models and the superpixels in the image
- Evaluates on scene flow benchmark on KITTI
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
CVPR 2009
Micusik2009CVPR | |||

- Unified framework for creating 3D city models
- Exploiting image segmentation cues, dominant scene orientations and piecewise planar structures
- Pose estimation with a modified SURF-based matching approach to exploit properties of the panoramic camera
- Multi-view stereo method that operates directly on panoramas while enforcing the piecewise planarity constraint in the sweeping stage
- Depth fusion method which exploits the constraints of urban environments combines advantages from volumetric- and viewpoint-based fusion
- Avoids expensive voxelization of space and operates directly on 3D reconstructed points through effective kd-tree
- Final surface by tessellation of backprojections of the points into the reference image
- Demonstration on two street-view sequences, only qualitative results
| Datasets & Benchmarks | |||
|
ARXIV 2016
Milan2016ARXIV | |||
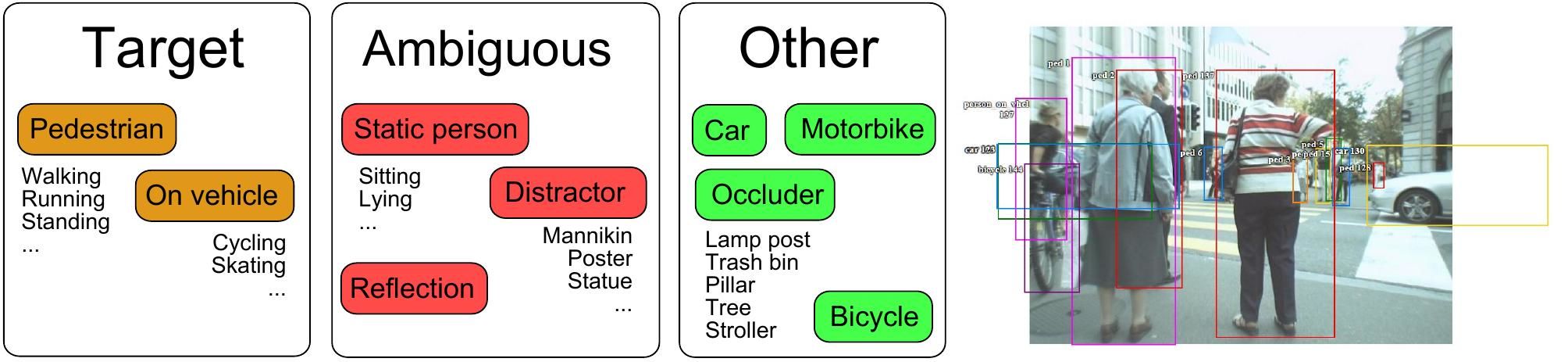
- Standardized benchmark for Multi-Object tracking
- New releases of MOTChallenge
- Unlike the initial release
- Carefully annotated by researchers following a consistent protocol
- Significant increase in the number of labeled boxes, 3 times more targets
- Multi object classes besides pedestrians
- Visibility for every single object of interest
| Object Tracking Methods | |||
|
ARXIV 2016
Milan2016ARXIV | |||
- Standardized benchmark for Multi-Object tracking
- New releases of MOTChallenge
- Unlike the initial release
- Carefully annotated by researchers following a consistent protocol
- Significant increase in the number of labeled boxes, 3 times more targets
- Multi object classes besides pedestrians
- Visibility for every single object of interest
| Object Tracking Datasets | |||
|
ARXIV 2016
Milan2016ARXIV | |||
- Standardized benchmark for Multi-Object tracking
- New releases of MOTChallenge
- Unlike the initial release
- Carefully annotated by researchers following a consistent protocol
- Significant increase in the number of labeled boxes, 3 times more targets
- Multi object classes besides pedestrians
- Visibility for every single object of interest
| Object Tracking Methods | |||
|
PAMI 2014
Milan2014PAMI | |||

- Contributions:
- Proposes an energy that corresponds to a more complete representation of the problem, rather than one that is amenable to global optimization
- Besides the image evidence, the energy function takes into account physical constraints, such as target dynamics, mutual exclusion, and track persistence
- Constructs a optimization scheme that alternates between continuous conjugate gradient descent and discrete trans-dimensional jump moves
- Evaluates on sequences from VS-PETS 2009/2010, TUD-Stadtmitte benchmarks
| Object Tracking Methods | |||
|
CVPR 2013
Milan2013CVPR | |||
- Tracking multiple targets in crowded scenarios
- Modelling mutual exclusion between distinct targets both at the data association and at the trajectory level
- Using a mixed discrete-continuous CRF
- Exclusion between conflicting observations with supermodular pairwise terms
- Exclusion between trajectories with pairwise global label costs
- A statistical analysis of ground-truth trajectories for modelling data fidelity, target dynamics, and inter-target occlusion
- An expansion move-based optimization scheme
- Evaluated on the PETS S2.L1, and four more sequences from PETS benchmark, TUD-Stadtmitte, and Bahnhof, Sunny Day sequences from ETH Mobile Scene dataset
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
GCPR 2015
Mirabdollah2015GCPR | |||
- Real-time and robust monocular visual odometry
- Iterative 5-point method to estimate initial camera motion parameters within RANSAC
- Landmark localization with uncertainties using a probabilistic triangulation method
- Robust tracking of low quality features on ground planes to estimate scale of motion
- Minimization of a cost function:
- Epipolar geometry constraints for far landmarks
- Projective constraints for close landmarks
- Real-time due to iterative estimation of only the last camera pose (landmark positions from probabilistic triangulation method)
- Evaluated on KITTI visual odometry dataset
| Object Tracking Methods | |||
|
ECCV 2012
Mitzel2012ECCV | |||
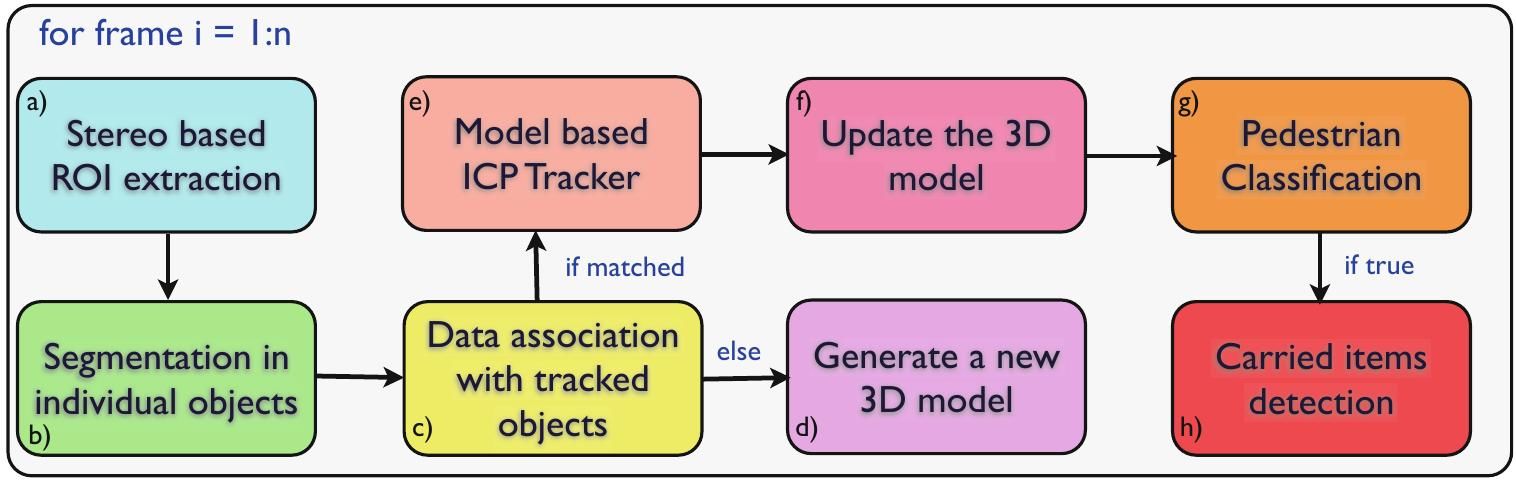
- Mobile multi-object tracking in challenging street scenes
- Tracking-by-detection limits to object categories of pre-trained detector models
- Tracking-before-detection approach that can track known and unknown object categories
- Noisy stereo depth data used to segment and track objects in 3D
- Novel, compact 3D representation allows to track robustly large variety of objects while building up models of their 3D shape online
- Comparison of the representation with a learned statistical shape template allows to detect anomalous shapes such as carried items
- Evaluation on several challenging video sequences of busy pedestrian zones, the BAHNHOF and SUNNY DAY dataset 1
1. Ess, A., Leibe, B., Schindler, K., Van Gool, L.: Robust Multi-Person Tracking from a Mobile Platform. PAMI 31(10), 18311846 (2009)
| Semantic Segmentation Methods | |||
|
ARXIV 2014
Moh2014ARXIV | |||
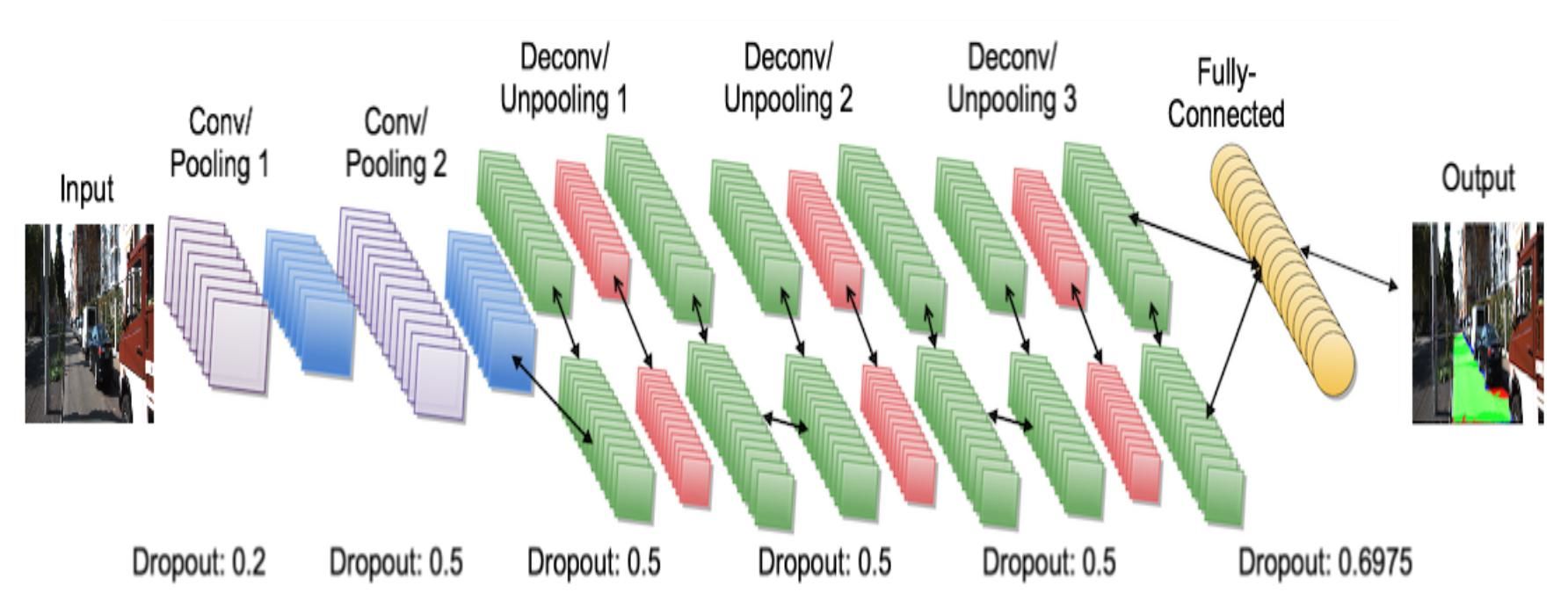
- Labeling each pixel in an image with the category it belongs to
- Using raw pixels instead of superpixels
- Combine deep deconvolutional neural networks with CNNs
- Multi patch training makes it possible to effectively learn spatial priors from scenes
- End-to-end training system without requiring post-processing
- Evaluated on Stanford Background, SIFT Flow, CamVid, and KITTI
| Semantic Segmentation Methods | |||
|
CPIA 2015
Montoya2015CPIA | |||
- Semantic segmentation of urban areas in high-resolution aerial images
- Highly heterogeneous object appearances and shape
- Using high-level shape representations as class-specific object priors
- Buildings by sets of compact polygons
- Roads as a collection of long, narrow segments 1
- Pixel-wise classifier to learn local co-occurrence patterns
- Hypotheses generation for possible road segments and segments of buildings in a data-driven manner
- Inference in a CRF with higher-order potentials
- Accuracies of > 80 on Vaihingen dataset
1. Mind the Gap: Modeling Local and Global Context in (Road) Networks, GCPR 2014
| Sensors Camera Models | |||
|
RSS 2015
Mueggler2015RSS | |||

- Ego-motion estimation for an event-based vision sensor using a continuous-time framework
- Directly integrating the information conveyed by the sensor
- Pose trajectory is approximated by a smooth curve using cubic splines in the space of rigid-body motions
- Optimization according a geometrically meaningful error measure in the image plane to the observed events
- Evaluation on datasets acquired from sensor-in-the-loop simulations and onboard a quadrotor performing flips with ground truth
| Semantic Segmentation Methods | |||
|
ECCV 2010
Munoz2010ECCV | |||
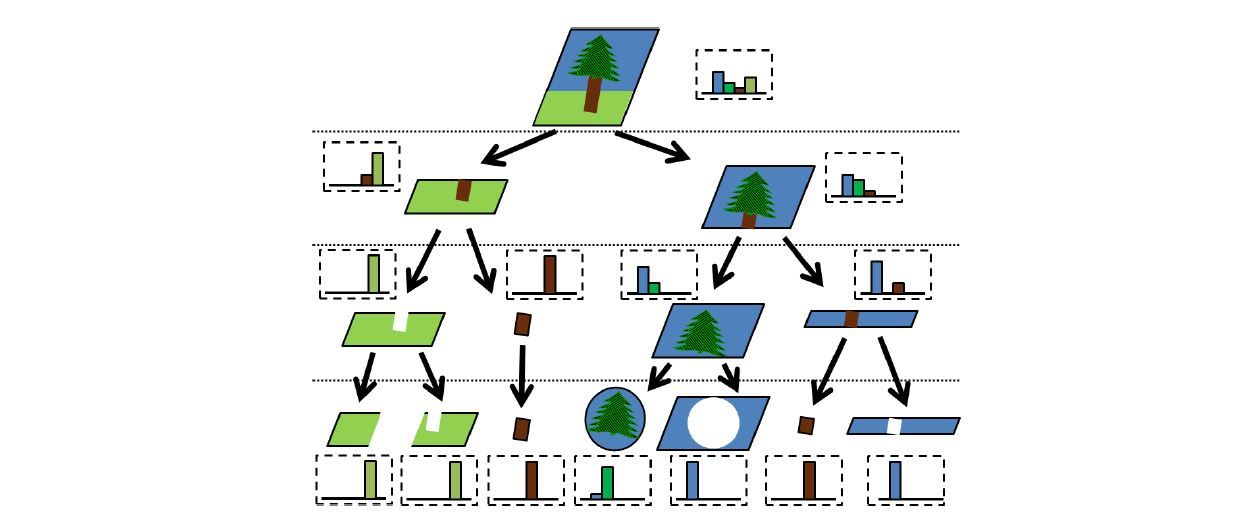
- Hierarchical approach for labeling semantic objects and regions in scenes
- Using a decomposition of the image in order to encode relational and spatial information
- Directly training a hierarchical inference procedure inspired by message passing
- Breaking the complex inference problem into a hierarchical series of simple subproblems
- Each subproblem is designed to capture the image and contextual statistics in the scene
- Training in sequence to ensure robustness to likely errors earlier in the inference sequence
- Evaluation on MSRC-21 and Stanford Background datasets
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
TR 2015
Mur-Artal2015TR | |||
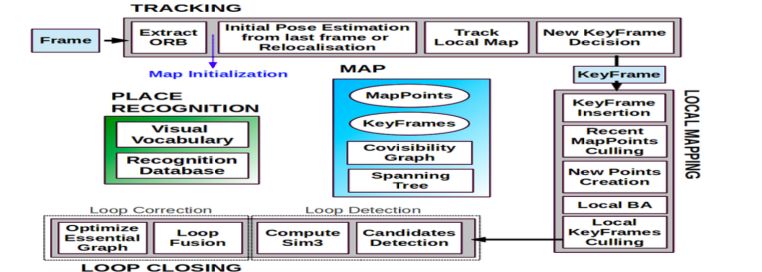
- Proposes a feature-based monocular SLAM system that operates in real time, in small and large, indoor and outdoor environments
- Contributions:
- Uses same features for all tasks: tracking, mapping, relocalization and loop closing
- Real time operation in large environments
- Real time loop closing based on the optimization of a pose graph
- Real time camera relocalization with significant invariance to viewpoint and illumination
- New initialization procedure based on model selection
- A survival of the fittest approach to map point and keyframe selection
- Evaluates on sequences from NewCollege, TUM RGB-D and KITTI datasets
| Multi-view 3D Reconstruction Problem Definition | |||
|
CGF 2013
Musialski2013CGF | |||
- Challenges - Full automation, Quality & scalability, data acquisition constraints
- Point Clouds & Cameras - introduce the Fundamentals of Stereo Vision, provides the key concepts of image-based automatic Structure from Motion methodology, and Multi-View Stereo approaches
- Buildings & Semantics - Approaches which aim at reconstructing whole buildings from various input sources, such as a set of photographs or laser-scanned points, typically by fitting some parametrised top-town building model
- Facades & Images - Approaches aiming at the reconstruction and representation of facades
- Blocks & Cities - The problem of measuring and documenting the world is the objective of the photogrammetry and remote sensing community
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
ISMAR 2011
Newcombe2011ISMAR | |||
| Semantic Segmentation Methods | |||
|
SIGGRAPH 2013
Niesner2013SIGGRAPH | |||
- Existing volumetric fusion methods produce high quality reconstructions but have large memory footprint.
- Hierarchical data structures are more memory efficient but do not parallelize efficiently.
- Contributions:
- Exploits this underlying sparsity in the TSDF representation.
- Uses a simple hashing scheme to compactly store, access and update an implicit surface representation
- Real time performance without compromising on scale or quality
- Evaluates on stereo and flow KITTI benchmarks
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
SIGGRAPH 2013
Niesner2013SIGGRAPH | |||
- Existing volumetric fusion methods produce high quality reconstructions but have large memory footprint.
- Hierarchical data structures are more memory efficient but do not parallelize efficiently.
- Contributions:
- Exploits this underlying sparsity in the TSDF representation.
- Uses a simple hashing scheme to compactly store, access and update an implicit surface representation
- Real time performance without compromising on scale or quality
- Evaluates on stereo and flow KITTI benchmarks
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
IROS 2004
Oh2004IROS | |||
- Map-based priors for localization using the semantic information available in maps
- Biases the motion model towards areas of higher probability
- Easily incorporated in the particle filter by means of a pseudo likelihood under a particular assumption
- Localization with noisy sensors results in far more stable local tracking
- Experimental results on a GPS-based outdoor people tracker
| Semantic Segmentation Methods | |||
|
IROS 2016
Oliveira2016IROS | |||
- An incremental 3D representation from 3D range measurements
- Macro scale polygonal primitives vs. micro scale primitives (not compact)
- Motivation:
- Processing large amounts of 3D data
- Large number of well defined geometric structures
- Reconstruction of large scale scenarios
- Update of geometric polygonal primitives over time with fresh sensor data
- Accurate, compact, and efficient descriptions of the scene
- Evaluated on a data-set from MIT, taken from their participation in the DARPA Urban Challenge
| Scene Understanding Methods | |||
|
RAS 2016
Oliveira2016RAS | |||

- Incremental 3D representation of a scene from continuous stream of 3D range sensor
- Using Macro scale polygonal primitives to model the scene
- Representation of the scene is a list of large scale polygons describing the geometric structure
- Approach to update the geometric polygonal primitives over time using fresh sensor data
- Produces accurate descriptions of the scene and is computationally very efficient compared to other reconstruction methods
- Evaluation on a dataset from the MIT team taken in the DARPA Urban Challenge
| Scene Understanding Discussion | |||
|
RAS 2016
Oliveira2016RAS | |||
- Incremental 3D representation of a scene from continuous stream of 3D range sensor
- Using Macro scale polygonal primitives to model the scene
- Representation of the scene is a list of large scale polygons describing the geometric structure
- Approach to update the geometric polygonal primitives over time using fresh sensor data
- Produces accurate descriptions of the scene and is computationally very efficient compared to other reconstruction methods
- Evaluation on a dataset from the MIT team taken in the DARPA Urban Challenge
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
ICRA 2010
Paul2010ICRA | |||
- A probabilistic framework for appearance based navigation and mapping using spatial and visual appearance data
- A bag-of-words approach in which positive or negative observations of visual words in a scene are used to discriminate between already visited and new places
- Explicitly modelling of the spatial distribution of visual words as a random graph in which nodes are visual words and edges are distributions over distances
- Representing locations as random graphs and learning a generative model over word occurrences as well as their spatial distributions
- Special care for multi-modal distributions of inter-word spacing and for sensor errors both in word detection and distances
- Viewpoint invariant inter-word distances as strong place signatures
- Evaluated on a dataset gathered within New College, Oxford
- Increased precision-recall area compared to a state-of-the-art visual appearance only
- Reduced false positive and false negative rate by capturing spatial information, particularly in loop closure decision hinges
| Mapping, Localization & Ego-Motion Estimation Metrics | |||
|
ICRA 2010
Paul2010ICRA | |||
- A probabilistic framework for appearance based navigation and mapping using spatial and visual appearance data
- A bag-of-words approach in which positive or negative observations of visual words in a scene are used to discriminate between already visited and new places
- Explicitly modelling of the spatial distribution of visual words as a random graph in which nodes are visual words and edges are distributions over distances
- Representing locations as random graphs and learning a generative model over word occurrences as well as their spatial distributions
- Special care for multi-modal distributions of inter-word spacing and for sensor errors both in word detection and distances
- Viewpoint invariant inter-word distances as strong place signatures
- Evaluated on a dataset gathered within New College, Oxford
- Increased precision-recall area compared to a state-of-the-art visual appearance only
- Reduced false positive and false negative rate by capturing spatial information, particularly in loop closure decision hinges
| Object Detection Methods | |||
|
PAMI 2015
Pepik2015PAMI | |||
- Joint object localization and viewpoint estimation
- Motivation
- Limited expressiveness of 2D feature-based models
- 3D object representations which can be robustly matched to image evidence
- Extension of DPM to include viewpoint information and part-level 3D geometry information
- DPM as a structured output prediction task
- Consistency between parts across viewpoints
- Modelling the parts positions and displacement distributions in 3D
- Continuous appearance model
- Several different models with different level of expressiveness
- Leveraging 3D information from CAD data
- Better than the state-of-the-art multi-view and 3D object detectors on KITTI, 3D object classes, Pascal3D+, Pascal VOC 2007, EPFL multi-view cars
| Semantic Segmentation Methods | |||
|
BMVC 2011
Pfeiffer2011BMVC | |||
- Medium level representation: thin planar rectangles called Stixels
- Motivation:
- Dominance of horizontal, vertical planar surfaces in man-made environments
- Structured access to the scene data
- Half a million disparity measurements to a few hundred Stixels only
- Difference to BadinoDAGM20091:
- A unified global optimal scheme
- Objects at multiple depths in a column
- Dynamic programming to incorporate real-world constraints (gravity, ordering)
- An optimal segmentation with respect to free space and obstacle information
- Results for stereo vision and laser data, but applicable to 3D data from other sensors
1. The stixel world - a compact medium level representation of the 3d-world. DAGM 2009
| Semantic Segmentation Methods | |||
|
IV 2010
Pfeiffer2010IV | |||
- Pose and motion estimation of moving obstacles in traffic scenes
- Stixel World is a compact and flexible representation but do not allow to infer motion information
- Dense disparity images are used for the free space computation and extraction of the static stixel representation
- Tracking of stixels using 6-Vision Kalman filter framework and dense optical flow
- Lateral as well as longitudinal motion is estimated for each stixel
- Simplifies grouping of stixels based on the motion as well as detection of moving obstacles
- Demonstration on recorded data
| Semantic Segmentation Methods | |||
|
IROS 2015
Pinggera2015IROS | |||

- Existing methods designed for robust generic obstacle detection based on geometric criteria work best only in close to medium range applications
- Contributions:
- Presents a novel method for the joint detection and localization of distant obstacles using a stereo vision system on a moving platform
- The proposed algorithm is based on statistical hypothesis tests using local geometric criteria and can implicitly handle non-flat ground surfaces
- Operates directly on image data instead of precomputed stereo disparity maps
- Evaluates on stereo sequences introduced in Cordts et al., Object-level Priors for Stixel Generation
| Semantic Segmentation Methods | |||
|
IROS 2016
Pinggera2016IROS | |||

- Reliable detection of small obstacles from a moving vehicle using stereo vision
- Statistical planar hypothesis tests in disparity space directly on stereo image data, assessing free-space and obstacle hypotheses
- Introduce midlevel obstacle representation Cluster-Stixels based on the original point-based output
- Does not depend on a global road model and handles static and moving obstacles
- Evaluation on a novel lost-cargo image sequence dataset comprising more than two thousand frames with pixel-wise annotations
- Comparison to several stereo-based baseline methods and runs at 20Hz on 2 mega-pixel stereo imagery
- Small obstalces down to the height of 5 cm can successfully be detected at 20 m
| Object Detection Methods | |||
|
CVPR 2016
Pishchulin2016CVPR | |||

- Existing methods for human pose estimation use two-stage strategies that separate the detection and pose estimation steps
- Contributions:
- Proposes a new formulation as a joint subset partitioning and labeling problem (SPLP) of a set of body-part hypotheses generated with CNN-based part detectors
- SPLP model jointly infers the number of people, their poses, spatial proximity, and part level occlusions
- Results show that a joint formulation is crucial to disambiguate multiple and potentially overlapping persons
- Evaluates on LSP and MPII single-person benchmarks and MPII and WAF multi-person benchmarks
| Object Detection Methods | |||
|
CVPR 2012
Pishchulin2012CVPR | |||
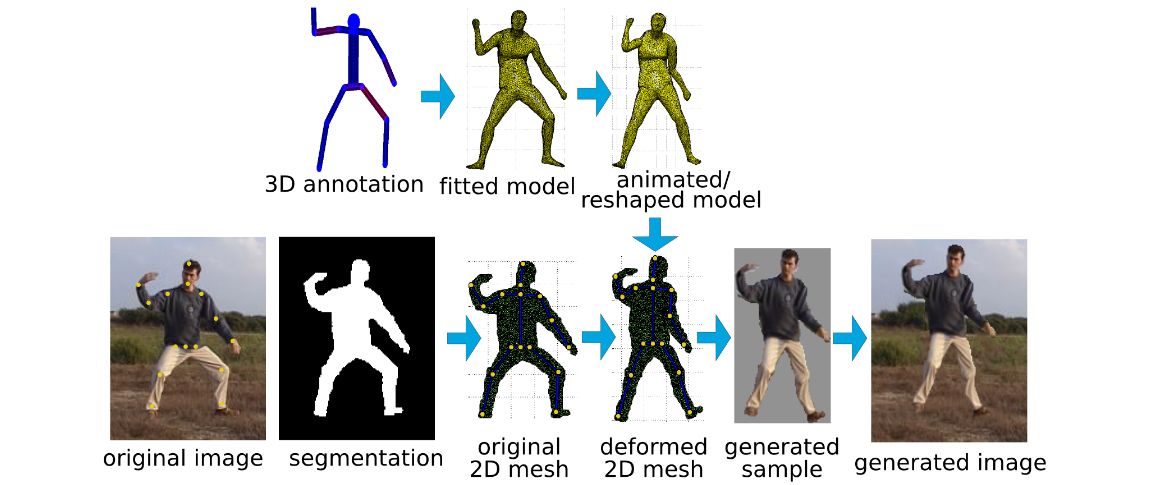
- So far human detection and pose approaches require large datasets
- Captured variations of datasets w.r.t. appearance, shape and pose are often uncontrolled
- Propose new technique to extend existing sets while explicitly controlling pose and shape variations
- Build on recent advances in computer graphics to generate realistic samples
- Validation of effectiveness on articulated human detection and articulated pose estimation
- Close to state-of-the-art results on Image Parsing human pose estimation benchmark
- Define a new challenge of combined articulated human detection and pose estimation in real world
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
IJCV 2008
Pollefeys2008IJCV | |||
- Large scale, real-time 3D reconstruction incorporating GPS and INS or traditional SfM
- Motivation:
- The massive amounts of data
- Lack of public high-quality ground-based models
- Real-time performance (30Hz) using graphics hardware and standard CPUs
- Extending state-of-the-art for robustness and variability necessary for outside:
- Large dynamic range: automatic gain adaptation for real-time stereo estimation
- Fusion with GPS and inertial measurements using a Kalman filter
- Two-step stereo reconstruction process exploiting the redundancy across frames
- Real urban video sequences with hundreds of thousands of frames on GPU
| Optical Flow Problem Definition | |||
|
IUW 1984
Quam1984IUW | |||
- Technique to automatically produce digital terrain models from stereo pairs of aerial images
- Coarse-to-fine hierarchical control structure for global constraint propagation and efficiency
- Images are geometrically warped according to the coarser level estimates
- Surface interpolation algorithm is proposed to fill holes where the matching fails
- Experimental results on Phoenix Mountain Park data set presented and compared to ETL
| 3D Scene Flow Methods | |||
|
ECCV 2010
Rabe2010ECCV | |||
- Estimating the three-dimensional motion vector field from stereo image sequences
- Combining variational optical flow with Kalman filtering for temporal smoothness
- Real-time with parallel implementation on a GPU and an FPGA
- Comparing
- Differential motion field estimation from optical flow (Horn & Schunck) and stereo (SGM)
- Variational scene flow from two frames
- Kalman filtered method, using dense optical flow and stereo (Dense6D)
- Filtered variational scene flow approach (Variational6D)
- Dense6D and Variational6D perform similarly, the latter is computationally more complex.
| Optical Flow Methods | |||
|
ECCV 2014
Ranftl2014ECCV | |||

- Total Generalized Variation
- Performs quite well favoring piecewise affine solutions
- Local nature can suffer from ambiguities in the data and cannot accurately locate discontinuities
- Contribution
- Non local TGV that allows to incorporate prior information as image gradients
- Scale invariant Census using a radial sampling strategy
- Evaluation on Sintel and KITTI 2012
| Stereo Methods | |||
|
SSVM 2013
Ranftl2013SSVM | |||
- Approximate minimization of variational models with Total Generalized Variation regularization (TGV) and non-convex data terms
- Motivation:
- TGV is arguably a better prior than TV (piecewise affine solutions)
- TGV is restricted to convex data terms
- Convex approximations to the non-convex problem (coarse-to-fine warping: loss of details)
- Decomposition of the functional into two subproblems which can be solved globally
- One is convex, the other by lifting the functional to a higher dimensional space, where it is convex
- Significant improvement compared to coarse-to-fine warping on stereo
- Evaluated on KITTI stereo and Middlebury high-resolution benchmarks
| Sensors Camera Models | |||
|
RAL 2016
Rebecq2016RAL | |||
- Event-based Visual Odometry algorithm
- Compared to standard cameras, event cameras are unaffected by motion blur and strong illumination changes.
- Tracking fast camera motions while recovering a semi-dense 3D map of the environment
- event-based tracking based on image-to-model alignment using edge maps
- event-based 3D reconstruction algorithm in a parallel fashion
- The same pipeline to reconstruct intensity images from the binary event stream
- Real-time on CPU with several hundred pose estimates per second
| Object Detection Methods | |||
|
NIPS 2015
Ren2015NIPS | |||
- Region Proposal Network (RPN) for object detection
- Simultaneous prediction of object bounds and objectness scores at each position
- Region proposals are the computational bottleneck for state-of-the-art detectors.
- End-to-end training to generate region proposals for Fast R-CNN
- Nearly cost-free region proposals
- RPNs: a kind of fully-convolutional network (FCN)
- Alternating optimization to train RPN and Fast R-CNN with shared features
- 5 fps (including all steps) on a GPU
- State-of-the-art object detection accuracy on PASCAL VOC 2007
| Object Detection State of the Art on KITTI | |||
|
NIPS 2015
Ren2015NIPS | |||
- Region Proposal Network (RPN) for object detection
- Simultaneous prediction of object bounds and objectness scores at each position
- Region proposals are the computational bottleneck for state-of-the-art detectors.
- End-to-end training to generate region proposals for Fast R-CNN
- Nearly cost-free region proposals
- RPNs: a kind of fully-convolutional network (FCN)
- Alternating optimization to train RPN and Fast R-CNN with shared features
- 5 fps (including all steps) on a GPU
- State-of-the-art object detection accuracy on PASCAL VOC 2007
| Object Tracking Datasets | |||
|
NIPS 2015
Ren2015NIPS | |||
- Region Proposal Network (RPN) for object detection
- Simultaneous prediction of object bounds and objectness scores at each position
- Region proposals are the computational bottleneck for state-of-the-art detectors.
- End-to-end training to generate region proposals for Fast R-CNN
- Nearly cost-free region proposals
- RPNs: a kind of fully-convolutional network (FCN)
- Alternating optimization to train RPN and Fast R-CNN with shared features
- 5 fps (including all steps) on a GPU
- State-of-the-art object detection accuracy on PASCAL VOC 2007
| Object Tracking State of the Art on MOT & KITTI | |||
|
NIPS 2015
Ren2015NIPS | |||
- Region Proposal Network (RPN) for object detection
- Simultaneous prediction of object bounds and objectness scores at each position
- Region proposals are the computational bottleneck for state-of-the-art detectors.
- End-to-end training to generate region proposals for Fast R-CNN
- Nearly cost-free region proposals
- RPNs: a kind of fully-convolutional network (FCN)
- Alternating optimization to train RPN and Fast R-CNN with shared features
- 5 fps (including all steps) on a GPU
- State-of-the-art object detection accuracy on PASCAL VOC 2007
| Semantic Instance Segmentation Methods | |||
|
NIPS 2015
Ren2015NIPS | |||
- Region Proposal Network (RPN) for object detection
- Simultaneous prediction of object bounds and objectness scores at each position
- Region proposals are the computational bottleneck for state-of-the-art detectors.
- End-to-end training to generate region proposals for Fast R-CNN
- Nearly cost-free region proposals
- RPNs: a kind of fully-convolutional network (FCN)
- Alternating optimization to train RPN and Fast R-CNN with shared features
- 5 fps (including all steps) on a GPU
- State-of-the-art object detection accuracy on PASCAL VOC 2007
| Semantic Instance Segmentation State of the Art on Cityscapes | |||
|
NIPS 2015
Ren2015NIPS | |||
- Region Proposal Network (RPN) for object detection
- Simultaneous prediction of object bounds and objectness scores at each position
- Region proposals are the computational bottleneck for state-of-the-art detectors.
- End-to-end training to generate region proposals for Fast R-CNN
- Nearly cost-free region proposals
- RPNs: a kind of fully-convolutional network (FCN)
- Alternating optimization to train RPN and Fast R-CNN with shared features
- 5 fps (including all steps) on a GPU
- State-of-the-art object detection accuracy on PASCAL VOC 2007
| Optical Flow Methods | |||
|
CVPR 2015
Revaud2015CVPR | |||
- Approach for optical flow estimation particularly targeting large displacements with significant occlusions
- It consists of two steps: begin{enumerate}
- Dense matching by edge-preserving interpolation from sparse set of matches
- Variational energy minimization initialized with dense matches end{enumerate}
- First step relies on edge-aware geodesic distance tailored to handle occlusions and motion boundaries
- Propose a fast approximation scheme for the geodesic distance
- EpicFlow was evaluated on Sintel, Kitti and Middlebury
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
ECCV 2016
Richter2016ECCV | |||
- Creating pixel-accurate semantic label maps for images extracted from computer games
- A wrapper between the game and the graphics hardware
- Pixel-accurate object signatures across time and instances
- By hashing distinct rendering resources such as geometry, textures, and shaders
- 25 thousand images
- Models trained with game data and just 1⁄3 of the CamVid training set outperform models trained on the complete CamVid training set
| Datasets & Benchmarks Synthetic Data Generation using Game Engines | |||
|
ECCV 2016
Richter2016ECCV | |||
- Creating pixel-accurate semantic label maps for images extracted from computer games
- A wrapper between the game and the graphics hardware
- Pixel-accurate object signatures across time and instances
- By hashing distinct rendering resources such as geometry, textures, and shaders
- 25 thousand images
- Models trained with game data and just 1⁄3 of the CamVid training set outperform models trained on the complete CamVid training set
| Semantic Segmentation Datasets | |||
|
ECCV 2016
Richter2016ECCV | |||
- Creating pixel-accurate semantic label maps for images extracted from computer games
- A wrapper between the game and the graphics hardware
- Pixel-accurate object signatures across time and instances
- By hashing distinct rendering resources such as geometry, textures, and shaders
- 25 thousand images
- Models trained with game data and just 1⁄3 of the CamVid training set outperform models trained on the complete CamVid training set
| Semantic Segmentation Methods | |||
|
CVPR 2017
Riegler2017CVPR | |||
- Deep and high resolution 3D convolutional networks for 3D tasks including 3D object classification, orientation estimation, and point cloud labelling
- High activations only near the object boundaries
- More memory and computation on relevant dense regions by exploiting sparsity
- Hierarchically partitioning of the space using a set of unbalanced octrees where each leaf node stores a pooled feature representation
- Deeper networks without compromising resolution
- Convolution, pooling, unpooling directly defined on this structure
- Higher input resolutions with significant speed-ups
- Particularly beneficial for orientation estimation and semantic point cloud labelling
- Evaluated on ModelNet10, RueMonge2014
| Semantic Segmentation Methods | |||
|
ECCV 2014
Riemenschneider2014ECCV | |||
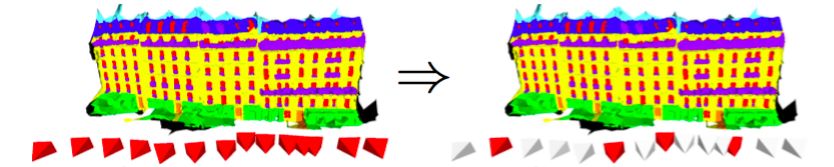
- View overlap is ignored by existing work in semantic scene labelling, and features in all views for all surface parts are extracted redundantly and expensively
- Contributions:
- Proposes an alternative approach for multi-view semantic labelling, efficiently combining the geometry of the 3D model and the appearance of a single, appropriately chosen view - denoted as reducing view redundancy
- Show the beneficial effect of reducing the initial labelling to a well-chosen subset of discriminative surface parts, and then using these labels to infer the labels of the remaining surface. This is denoted as scene coverage
- Accelerates the labelling by two orders of magnitude and make a finer-grained labelling of large models (e.g. of cities) practically feasible
- Provides a new 3D dataset of densely labelled images
| Semantic Segmentation Methods | |||
|
MICCAI 2015
Ronneberger2015MICCAI | |||
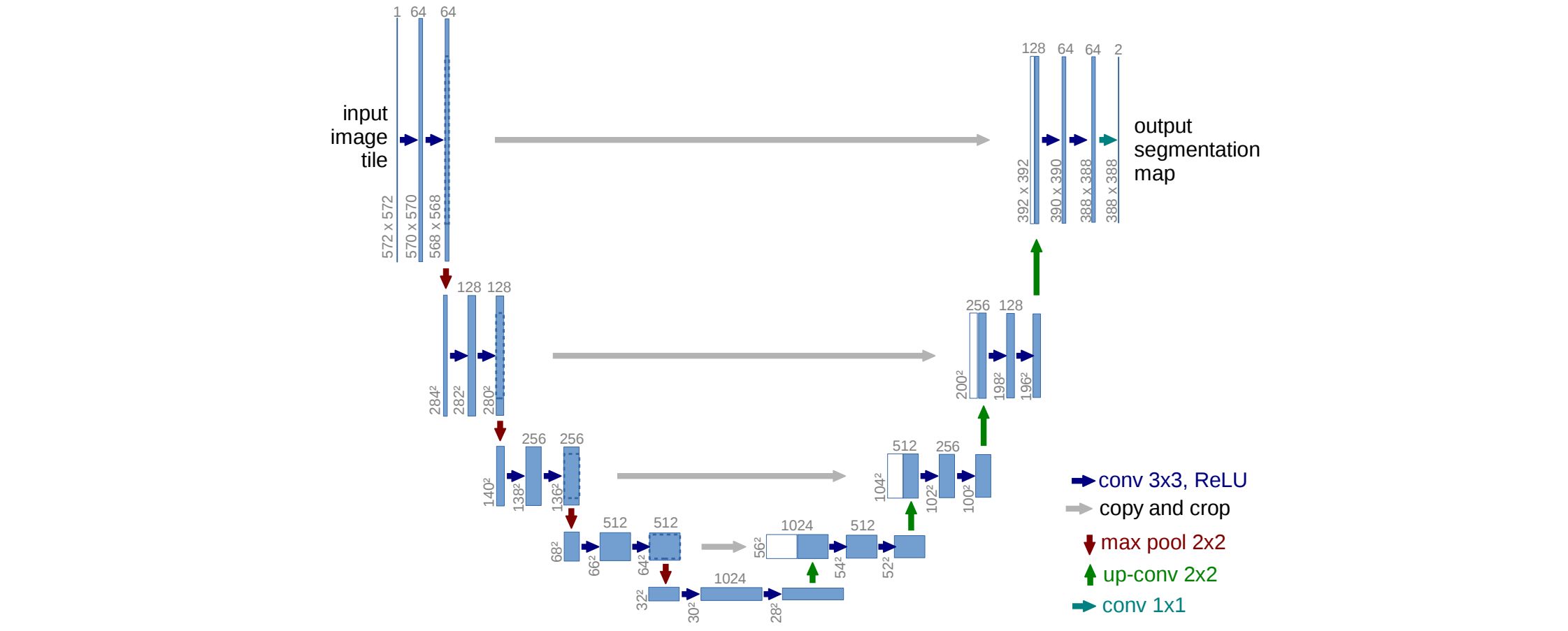
- Existing patch based CNN methods don't exploit the context effectively and are slow.
- Contributions:
- Introduces a new U-shaped architecture for segmenting whole image in a single pass.
- Supplements usual contracting part of a CNN with upsampling operators
- Allows to propagate context information to higher resolution layers.
- Evaluates on ISBI cell tracking challenge and EM segmentation challenge.
| Datasets & Benchmarks Autonomous Driving Datasets | |||
|
CVPR 2016
Ros2016CVPR | |||

- Proposes to use a virtual world to automatically generate realistic synthetic images with pixel-level semantic segmentation annotation
- Contributions:
- A new dataset SYNTHIA, for semantic segmentation of driving scenes with more than 213,400 syn- thetic images including both, random snapshots and video sequences in a virtual city
- Images are generated simulating different seasons, weather and illumination conditions from multiple view-points
- Experiments showed that SYNTHIA is good enough to produce good segmentations by itself on real datasets, dramatically boosting accuracy in combination with real data.
| Datasets & Benchmarks Synthetic Data Generation using Game Engines | |||
|
CVPR 2016
Ros2016CVPR | |||
- Proposes to use a virtual world to automatically generate realistic synthetic images with pixel-level semantic segmentation annotation
- Contributions:
- A new dataset SYNTHIA, for semantic segmentation of driving scenes with more than 213,400 syn- thetic images including both, random snapshots and video sequences in a virtual city
- Images are generated simulating different seasons, weather and illumination conditions from multiple view-points
- Experiments showed that SYNTHIA is good enough to produce good segmentations by itself on real datasets, dramatically boosting accuracy in combination with real data.
| Semantic Segmentation Datasets | |||
|
CVPR 2016
Ros2016CVPR | |||
- Proposes to use a virtual world to automatically generate realistic synthetic images with pixel-level semantic segmentation annotation
- Contributions:
- A new dataset SYNTHIA, for semantic segmentation of driving scenes with more than 213,400 syn- thetic images including both, random snapshots and video sequences in a virtual city
- Images are generated simulating different seasons, weather and illumination conditions from multiple view-points
- Experiments showed that SYNTHIA is good enough to produce good segmentations by itself on real datasets, dramatically boosting accuracy in combination with real data.
| Stereo Datasets | |||
|
CVPR 2016
Ros2016CVPR | |||
- Proposes to use a virtual world to automatically generate realistic synthetic images with pixel-level semantic segmentation annotation
- Contributions:
- A new dataset SYNTHIA, for semantic segmentation of driving scenes with more than 213,400 syn- thetic images including both, random snapshots and video sequences in a virtual city
- Images are generated simulating different seasons, weather and illumination conditions from multiple view-points
- Experiments showed that SYNTHIA is good enough to produce good segmentations by itself on real datasets, dramatically boosting accuracy in combination with real data.
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
ICCV 2015
Sattler2015ICCV | |||
- Large-scale structure-based localization
- Problem: ineffective descriptor matching due to large memory footprint and the strictness of the ratio test in 3D
- Previous approaches:
- Smart compression of the 3D model
- Clever sampling strategies for geometric verification
- Implicit feature matching by quantization into a fine vocabulary
- Using all the 3D points and standard sampling
- Locally unique 2D-3D point assignment by a simple voting strategy to enforce the co-visibility of the selected 3D points
- Evaluation on SF-0, Landmarks datasets
- State-of-the-art performance with reduced memory footprint by storing only visual word labels
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
PAMI 2016
Sattler2016PAMI | |||
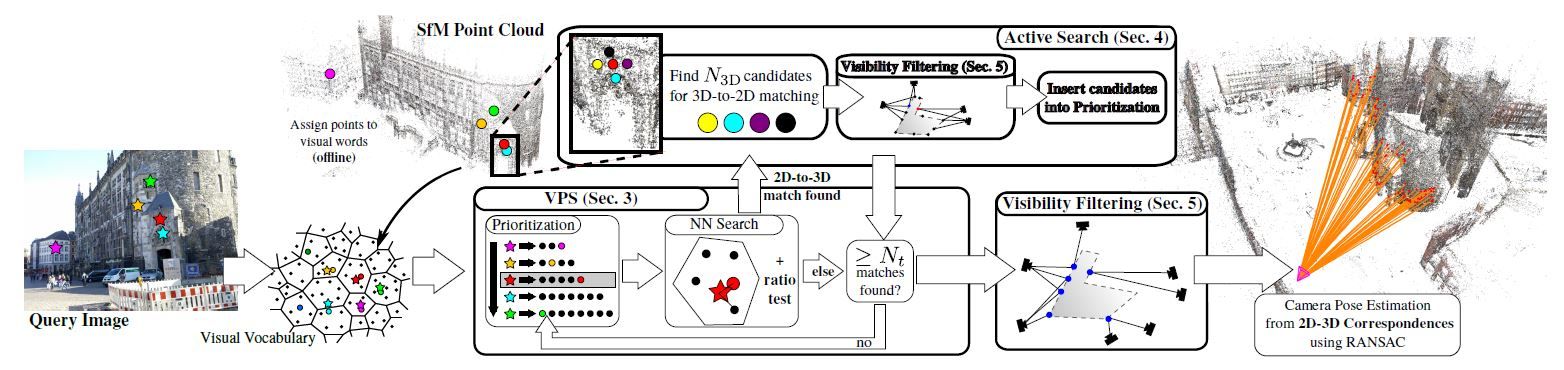
- Accurately determining the position and orientation from which an image was taken using SfM point clouds
- Direct matching strategy comparing descriptors of the 2D query features and the 3D points in the model
- Vocabulary-based prioritized matching step is able to consider features more likely to yield 2D-to-3D matches
- Terminating the correspondence search as soon as enough matches have been found
- Visibility information from reconstruction process used to improve the efficiency
- Efficiently handling large-scale 3D models
- Evaluation on Dubrovnik, Rome and Vienna dataset used as standard benchmark for image-based localization
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
PAMI 2016
Sattler2016PAMI | |||
- Accurately determining the position and orientation from which an image was taken using SfM point clouds
- Direct matching strategy comparing descriptors of the 2D query features and the 3D points in the model
- Vocabulary-based prioritized matching step is able to consider features more likely to yield 2D-to-3D matches
- Terminating the correspondence search as soon as enough matches have been found
- Visibility information from reconstruction process used to improve the efficiency
- Efficiently handling large-scale 3D models
- Evaluation on Dubrovnik, Rome and Vienna dataset used as standard benchmark for image-based localization
| Optical Flow Methods | |||
|
CVPRWORK 2015
Savva2015CVPRWORK | |||
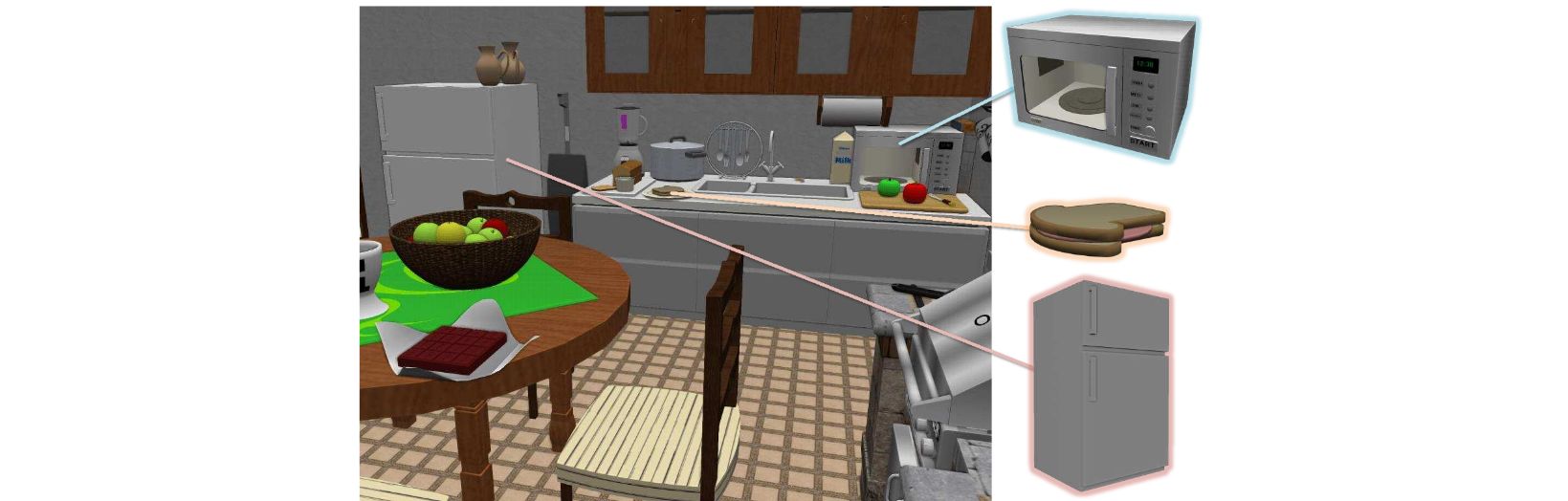
- Create a richly-annotated 3D model dataset
- Identifying and connecting a set of physical properties to 3D models
- Provide data on physical sizes, static support, attachment surface, material compositions, and weights
- Leverage observations of 3D scenes (images and text) to collect these property priors
- Augmentation of 3D models with these properties
- Semantically rich, multi-layered dataset of common indoor objects
- Demonstration by improving 3D scene synthesis systems
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
RAM 2011
Scaramuzza2011RAM | |||
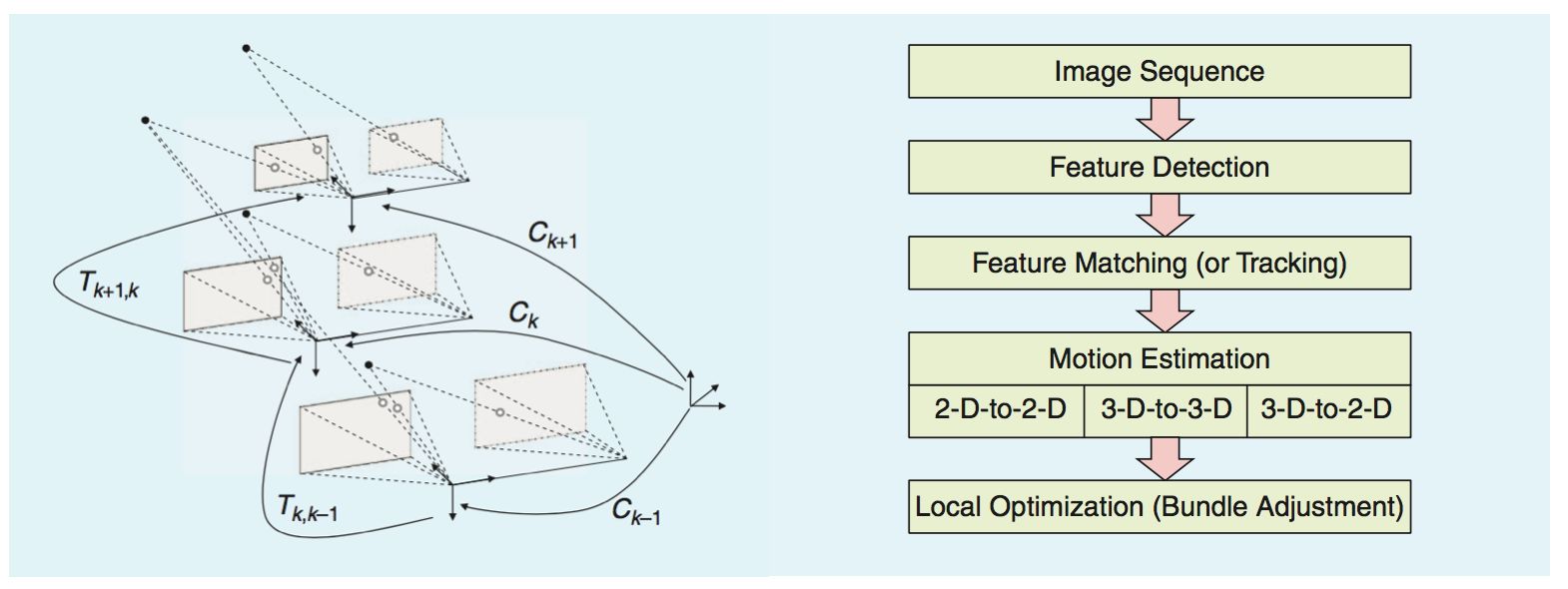
- Tutorial and survey on Visual Odometry (VO)
- Historical review of the research from 1980 to 2011 and its fundamentals
- A brief discussion on camera modeling and calibration
- Feature matching, robustness, and applications
- Error modeling, location recognition (or loop-closure detection), and bundle adjustment
- Guidelines and references to algorithms to build a complete VO system
- A discussion on VO applications
- A table of VO code available
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
RAM 2011
Scaramuzza2011RAM | |||
- Tutorial and survey on Visual Odometry (VO)
- Historical review of the research from 1980 to 2011 and its fundamentals
- A brief discussion on camera modeling and calibration
- Feature matching, robustness, and applications
- Error modeling, location recognition (or loop-closure detection), and bundle adjustment
- Guidelines and references to algorithms to build a complete VO system
- A discussion on VO applications
- A table of VO code available
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
ICRA 2009
Scaramuzza2009ICRA | |||
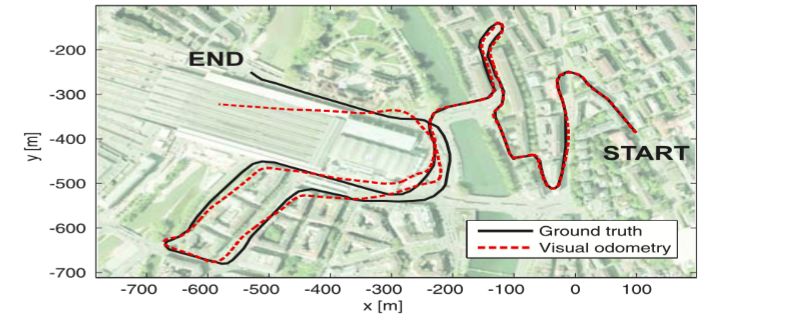
- Presents a system capable of recovering the trajectory of a vehicle from the video input of a single camera at a very high frame-rate
- Contributions:
- The algorithm proposes a novel way of removing the outliers of the feature matching process
- Show that by exploiting the nonholonomic constraints of wheeled vehicles it is possible to use a restrictive motion model
- This allows to parameterize the motion with only 1 feature correspondence
- Evaluates on real traffic sequencees in the city center of Zurich
| Sensors Camera Models | |||
|
IROS 2006
Scaramuzza2006IROS | |||
- Fast and automatic calibration of central omnidirectional cameras, both dioptric and catadioptric
- Requiring a few images of a checker board, and clicking on its corner points
- No need for specific model of the omnidirectional sensor
- Imaging function by a Taylor series expansion whose coefficients are estimated by
- solving a four-step least-squares linear minimization problem
- a non-linear refinement based on the maximum likelihood criterion
- Evaluation on both simulated and real data
- Showing calibration accuracy by projecting the color information of a calibrated camera on real 3D points extracted by a 3D sick laser range finder
- A Matlab toolbox
| Sensors Camera Models | |||
|
TR 2008
Scaramuzza2008TR | |||

- Describes a real-time algorithm for computing the ego-motion of a vehicle relative to the road
- Uses as input only those images provided by a single omnidirectional camera mounted on the roof of the vehicle
- The front ends of the system are two different trackers:
- The first one is a homography-based tracker that detects and matches robust scale-invariant features that most likely belong to the ground plane
- The second one uses an appearance-based approach and gives high-resolution estimates of the rotation of the vehicle
- Camera trajectory estimated from omnidirectional images over a distance of 400m. For performance evaluation, the estimated path is superimposed onto a satellite image
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
TR 2008
Scaramuzza2008TR | |||
- Describes a real-time algorithm for computing the ego-motion of a vehicle relative to the road
- Uses as input only those images provided by a single omnidirectional camera mounted on the roof of the vehicle
- The front ends of the system are two different trackers:
- The first one is a homography-based tracker that detects and matches robust scale-invariant features that most likely belong to the ground plane
- The second one uses an appearance-based approach and gives high-resolution estimates of the rotation of the vehicle
- Camera trajectory estimated from omnidirectional images over a distance of 400m. For performance evaluation, the estimated path is superimposed onto a satellite image
| Multi-view 3D Reconstruction State of the Art on ETH3D & Tanks and Temples | |||
|
ECCV 2016
Schoenberger2016ECCV | |||
| Datasets & Benchmarks Computer Vision Datasets | |||
|
GCPR 2014
Scharstein2014GCPR | |||

- Improving Middlebury stereo benchmark with new sequences
- A new level of challenge for stereo algorithms, both in terms of resolution and scene complexity
- A structured lighting system for high-resolution stereo datasets of static indoor scenes
- Highly accurate ground-truth disparities: a disparity accuracy of 0.2 pixels on most observed surfaces, including half-occluded regions
- 33 new 6-megapixel datasets
- Each dataset contains images with
- multiple exposures and multiple ambient illuminations
- both perfect and realistic imperfect rectification
- accurate 1D and 2D floating-point disparities
| Datasets & Benchmarks Computer Vision Datasets | |||
|
CVPR 2003
Scharstein2003CVPR | |||

- Middlebury stereo benchmark
- A technique for acquiring high-complexity stereo image pairs
- Pixel-accurate correspondence information
- Using structured light: projecting one or more special light patterns onto a scene in order to directly acquire a range map of the scene, typically using a single camera and a single projector
- Experimented with two different kinds of structured light
- binary Gray codes (more reliable)
- continuous sine waves (improving is left as future work)
| Datasets & Benchmarks | |||
|
IJCV 2002
Scharstein2002IJCV | |||

- Presents a taxonomy of dense, two-frame stereo methods designed to assess the different components of individual stereo algorithms
- Uses this taxonomy to highlight the most important features of existing stereo algorithms and to study important algorithmic components in isolation
- Provides a test bed for the quantitative evaluation of stereo algorithms with sample implementations along with test data
- Produces new calibrated multi-view stereo data sets with hand-labeled ground truth
- Performs an extensive experimental investigation in order to assess the impact of the different algorithmic components
- Demonstrates the limitations of local methods & assesses the value of different global techniques &s their sensitivity to key parameters
| Datasets & Benchmarks Computer Vision Datasets | |||
|
IJCV 2002
Scharstein2002IJCV | |||
- Presents a taxonomy of dense, two-frame stereo methods designed to assess the different components of individual stereo algorithms
- Uses this taxonomy to highlight the most important features of existing stereo algorithms and to study important algorithmic components in isolation
- Provides a test bed for the quantitative evaluation of stereo algorithms with sample implementations along with test data
- Produces new calibrated multi-view stereo data sets with hand-labeled ground truth
- Performs an extensive experimental investigation in order to assess the impact of the different algorithmic components
- Demonstrates the limitations of local methods & assesses the value of different global techniques &s their sensitivity to key parameters
| Stereo Methods | |||
|
IJCV 2002
Scharstein2002IJCV | |||
- Presents a taxonomy of dense, two-frame stereo methods designed to assess the different components of individual stereo algorithms
- Uses this taxonomy to highlight the most important features of existing stereo algorithms and to study important algorithmic components in isolation
- Provides a test bed for the quantitative evaluation of stereo algorithms with sample implementations along with test data
- Produces new calibrated multi-view stereo data sets with hand-labeled ground truth
- Performs an extensive experimental investigation in order to assess the impact of the different algorithmic components
- Demonstrates the limitations of local methods & assesses the value of different global techniques &s their sensitivity to key parameters
| Stereo Datasets | |||
|
IJCV 2002
Scharstein2002IJCV | |||
- Presents a taxonomy of dense, two-frame stereo methods designed to assess the different components of individual stereo algorithms
- Uses this taxonomy to highlight the most important features of existing stereo algorithms and to study important algorithmic components in isolation
- Provides a test bed for the quantitative evaluation of stereo algorithms with sample implementations along with test data
- Produces new calibrated multi-view stereo data sets with hand-labeled ground truth
- Performs an extensive experimental investigation in order to assess the impact of the different algorithmic components
- Demonstrates the limitations of local methods & assesses the value of different global techniques &s their sensitivity to key parameters
| Multi-view 3D Reconstruction Datasets | |||
|
IJCV 2002
Scharstein2002IJCV | |||
- Presents a taxonomy of dense, two-frame stereo methods designed to assess the different components of individual stereo algorithms
- Uses this taxonomy to highlight the most important features of existing stereo algorithms and to study important algorithmic components in isolation
- Provides a test bed for the quantitative evaluation of stereo algorithms with sample implementations along with test data
- Produces new calibrated multi-view stereo data sets with hand-labeled ground truth
- Performs an extensive experimental investigation in order to assess the impact of the different algorithmic components
- Demonstrates the limitations of local methods & assesses the value of different global techniques &s their sensitivity to key parameters
| Semantic Segmentation Methods | |||
|
IV 2016
Schneider2016IV | |||
- Joint inference of geometric and semantic layout of a scene using stixels
- Geometry as a dense disparity map (SGM)
- Semantics as a pixel-level semantic scene labelling (CNNs)
- Stixel representation with object class information
- Better than original Stixel model in terms of geometric accuracy
- Complexity (time): linear in the number of object classes (15 Hz on 2 MP images)
- Evaluated on the subset of KITTI 2012 annotated semantically, KITTI 2015 (only disparity), Cityscapes (only semantics)
| Sensors Camera Models | |||
|
IROS 2014
Schoenbein2014IROS | |||
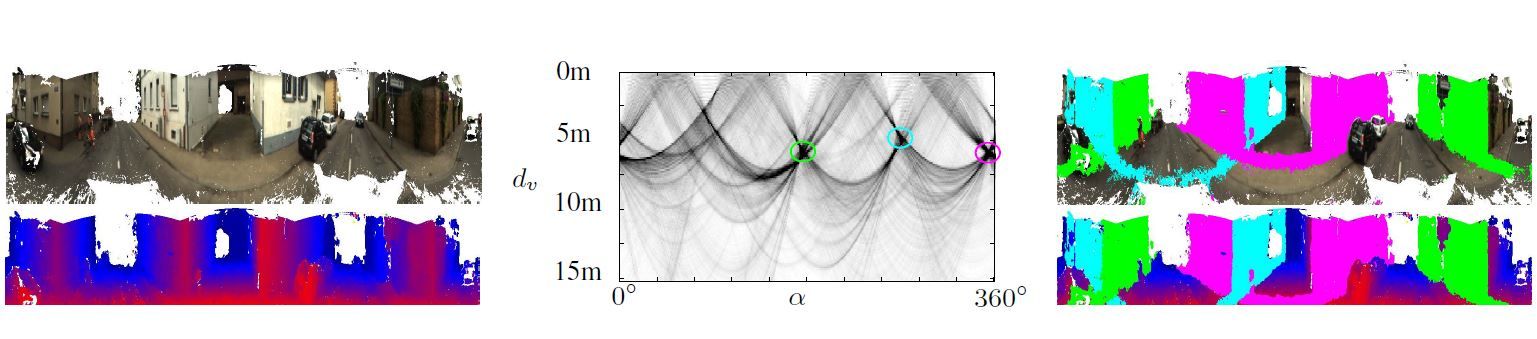
- High-quality omnidirectional 3D reconstruction from catadioptric stereo video sequences
- Optimization of depth jointly in a unified omnidirectional space
- Applying plane-based prior even though planes in 3D do not project to planes in the omnidirectional domain
- Omnidirectional slanted-plane Markov random field model
- Plane hypotheses are extracted using a novel voting scheme for 3D planes in omnidirectional space
- Evaluation on novel dataset captured using autonomous driving platform AnnieWAY with Velodyne HDL-64E laser scanner for ground truth depth
- Outperforms stereo matching techniques quantitatively and qualitatively
| Stereo Methods | |||
|
IROS 2014
Schoenbein2014IROS | |||
- High-quality omnidirectional 3D reconstruction from catadioptric stereo video sequences
- Optimization of depth jointly in a unified omnidirectional space
- Applying plane-based prior even though planes in 3D do not project to planes in the omnidirectional domain
- Omnidirectional slanted-plane Markov random field model
- Plane hypotheses are extracted using a novel voting scheme for 3D planes in omnidirectional space
- Evaluation on novel dataset captured using autonomous driving platform AnnieWAY with Velodyne HDL-64E laser scanner for ground truth depth
- Outperforms stereo matching techniques quantitatively and qualitatively
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
IROS 2014
Schoenbein2014IROS | |||
- High-quality omnidirectional 3D reconstruction from catadioptric stereo video sequences
- Optimization of depth jointly in a unified omnidirectional space
- Applying plane-based prior even though planes in 3D do not project to planes in the omnidirectional domain
- Omnidirectional slanted-plane Markov random field model
- Plane hypotheses are extracted using a novel voting scheme for 3D planes in omnidirectional space
- Evaluation on novel dataset captured using autonomous driving platform AnnieWAY with Velodyne HDL-64E laser scanner for ground truth depth
- Outperforms stereo matching techniques quantitatively and qualitatively
| Sensors Camera Models | |||
|
ICRA 2014
Schoenbein2014ICRA | |||
- Omnidirectional 3D reconstruction of augmented Manhattan worlds from catadioptric stereo video sequences
- Optimizing depth jointly in a unified omnidirectional space in contrast to constructing virtual perspective views
- An omnidirectional slanted-plane MRF model based on superpixels
- Plane-based prior models using a voting scheme for 3D planes in omnidirectional space
- Loopy BP to find the best plane hypothesis for each superpixel as a discrete labelling problem
- A new dataset captured using two horizontally aligned catadioptric cameras and a Velodyne HDL-64E laser scanner for ground truth depth (AnnieWAY)
- Better than existing stereo methods thanks to unified view, with reduced noise a compact plane representation
| Multi-view 3D Reconstruction State of the Art on ETH3D & Tanks and Temples | |||
|
CVPR 2016
Schoenberger2016CVPR | |||
| Datasets & Benchmarks | |||
|
CVPR 2017
Schoeps2017CVPR | |||

- A multi-view stereo benchmark with a diverse set of viewpoints and scene type
- Both indoor and outdoor scenes
- Using a high-precision laser scanner
- From hand-held mobile devices
- Capturing both high-resolution DSLR imagery and synchronized low-resolution stereo videos with varying fields-of-view
- High-resolution enables the evaluation of detailed 3D reconstructions and encourages memory and computationally efficient methods.
- A robust technique to align the images with the laser scan by minimizing photometric errors conditioned on the geometry
- An analysis of existing MVS algorithms on the benchmark
| Datasets & Benchmarks Computer Vision Datasets | |||
|
CVPR 2017
Schoeps2017CVPR | |||
- A multi-view stereo benchmark with a diverse set of viewpoints and scene type
- Both indoor and outdoor scenes
- Using a high-precision laser scanner
- From hand-held mobile devices
- Capturing both high-resolution DSLR imagery and synchronized low-resolution stereo videos with varying fields-of-view
- High-resolution enables the evaluation of detailed 3D reconstructions and encourages memory and computationally efficient methods.
- A robust technique to align the images with the laser scan by minimizing photometric errors conditioned on the geometry
- An analysis of existing MVS algorithms on the benchmark
| Stereo Datasets | |||
|
CVPR 2017
Schoeps2017CVPR | |||
- A multi-view stereo benchmark with a diverse set of viewpoints and scene type
- Both indoor and outdoor scenes
- Using a high-precision laser scanner
- From hand-held mobile devices
- Capturing both high-resolution DSLR imagery and synchronized low-resolution stereo videos with varying fields-of-view
- High-resolution enables the evaluation of detailed 3D reconstructions and encourages memory and computationally efficient methods.
- A robust technique to align the images with the laser scan by minimizing photometric errors conditioned on the geometry
- An analysis of existing MVS algorithms on the benchmark
| Multi-view 3D Reconstruction Datasets | |||
|
CVPR 2017
Schoeps2017CVPR | |||
- A multi-view stereo benchmark with a diverse set of viewpoints and scene type
- Both indoor and outdoor scenes
- Using a high-precision laser scanner
- From hand-held mobile devices
- Capturing both high-resolution DSLR imagery and synchronized low-resolution stereo videos with varying fields-of-view
- High-resolution enables the evaluation of detailed 3D reconstructions and encourages memory and computationally efficient methods.
- A robust technique to align the images with the laser scan by minimizing photometric errors conditioned on the geometry
- An analysis of existing MVS algorithms on the benchmark
| Multi-view 3D Reconstruction State of the Art on ETH3D & Tanks and Temples | |||
|
CVPR 2017
Schoeps2017CVPR | |||
- A multi-view stereo benchmark with a diverse set of viewpoints and scene type
- Both indoor and outdoor scenes
- Using a high-precision laser scanner
- From hand-held mobile devices
- Capturing both high-resolution DSLR imagery and synchronized low-resolution stereo videos with varying fields-of-view
- High-resolution enables the evaluation of detailed 3D reconstructions and encourages memory and computationally efficient methods.
- A robust technique to align the images with the laser scan by minimizing photometric errors conditioned on the geometry
- An analysis of existing MVS algorithms on the benchmark
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
IV 2013
Schreiber2013IV | |||
- Precise localization relative to the given map in real-world traffic scenarios
- Motivation:
- INS1 combining IMU2, GNSS3 cannot achieve precision required in typical traffic scenes (in the range of a few centimeters).
- A localization system that is independent of satellite systems
- Using a stereo camera system, IMU data of the vehicle, and a highly accurate map with curbs and road markings
- Beforehand creation of maps using an extended sensor setup
- Initialization using GNSS positiotion
- Kalman Filter based localization achieving an accuracy in the range of 10 cm in real-time
- Evaluation on a test track and approximately 50 km of rural roads
1. Inertial Navigation Systems
2. Inertial Measurement Unit
3. Global Navigation Satellite System
| Scene Understanding Methods | |||
|
ARXIV 2016
Seff2016ARXIV | |||
- Road layout inference from a single RGB image, without high-definition maps
- An automatically labelled, large-scale dataset
- By matching road vectors and meta-data from navigation maps with Google Street View images
- Ground truth road layout attributes
- Training AlexNet to predict the road layout attributes (a separate network for each task)
- Comparably to or better than the human baselines except for number of lanes estimation
- Possibility to extend to recommending safety improvements (e.g., suggesting an alternative speed limit for a street)
| Scene Understanding Discussion | |||
|
ARXIV 2016
Seff2016ARXIV | |||
- Road layout inference from a single RGB image, without high-definition maps
- An automatically labelled, large-scale dataset
- By matching road vectors and meta-data from navigation maps with Google Street View images
- Ground truth road layout attributes
- Training AlexNet to predict the road layout attributes (a separate network for each task)
- Comparably to or better than the human baselines except for number of lanes estimation
- Possibility to extend to recommending safety improvements (e.g., suggesting an alternative speed limit for a street)
| Datasets & Benchmarks Computer Vision Datasets | |||
|
CVPR 2006
Seitz2006CVPR | |||

- A survey and evaluation of multi-view stereo (MVS) algorithms on new datasets with high-accuracy ground truth
- Using a taxonomy that differentiates key properties of MVS algorithms based on the scene representation, photo-consistency measure, visibility model, shape prior, reconstruction algorithm, and initialization requirements
- The process of acquiring and calibrating MVS datasets with laser-scanned surface models
- A quantitative comparison of stereo algorithms on the acquired datasets assessing both the accuracy and the completeness
| Stereo Methods | |||
|
BMVC 2016
Seki2016BMVC | |||

- Confidence predictions for stereo matching and incorporating confidences into SGM
- Motivation: Limited accuracy of hand-crafted features for learning confidence measures
- Two-channel disparity patch as input to a CNN to predict if the disparity at the center pixel correct or not
- First channel by subtracting the disparity at the center pixel
- Second channel by converting the disparity map in the right image to the left image coordinate
- Confidence fusion by decreasing penalties at the high confidence pixels in SGM formulation
- Outperforms other confidence measures
- State-of-the-art results on KITTI benchmark with confidence fusion
| Semantic Segmentation Methods | |||
|
ICRA 2013
Sengupta2013ICRA | |||
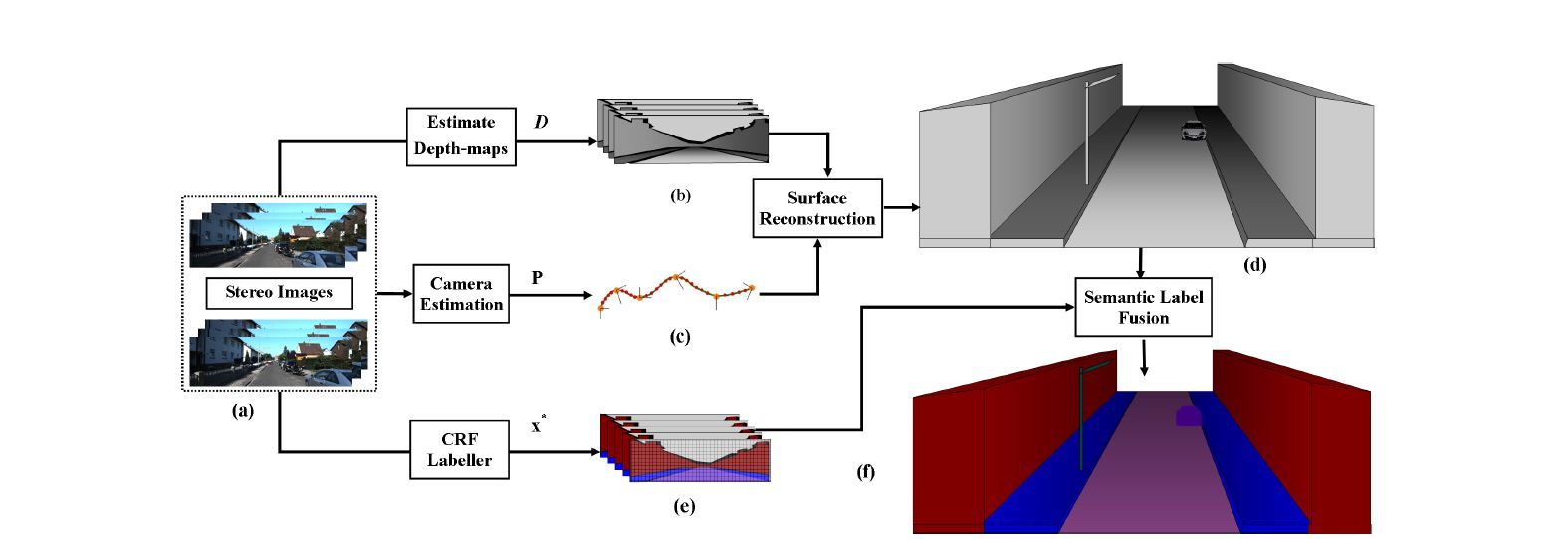
- Efficient and accurate dense 3D reconstruction with associated semantic labellings from street level stereo image pairs
- Using a robust visual odometry method with effective feature matching
- Depth-maps, generated from stereo, are fused into a global 3D volume online
- Labelling of street level images using a CRF exploiting stereo images
- Label estimates are aggregated to annotate the 3D volume
- Evaluation on KITTI odometry dataset with manual annotation for object class segmentation
| Mapping, Localization & Ego-Motion Estimation Mapping | |||
|
IROS 2012
Sengupta2012IROS | |||
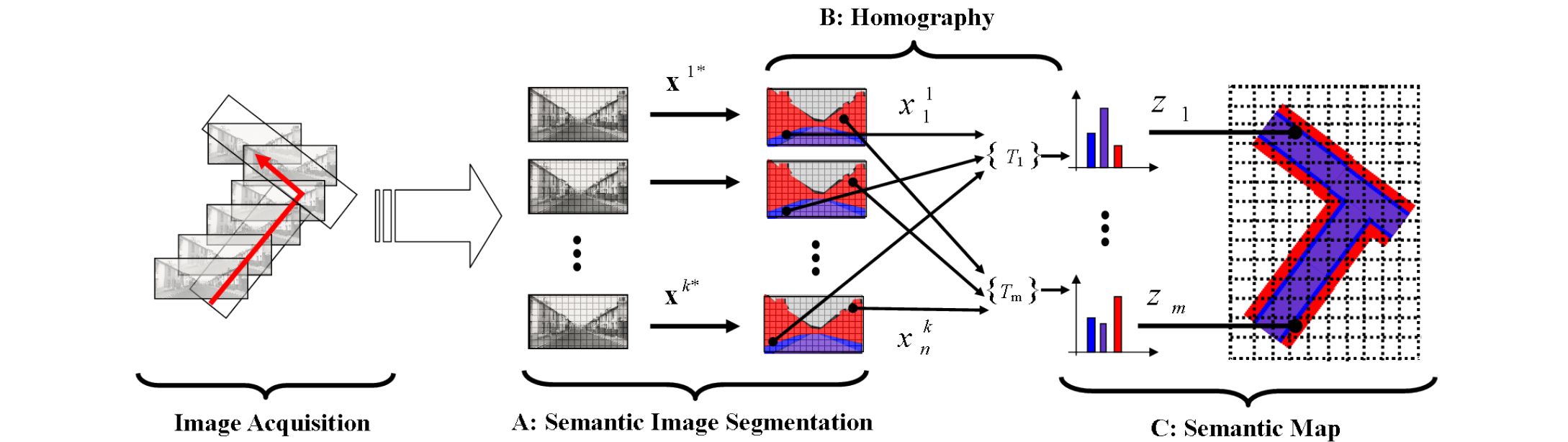
- Describes a method for producing a semantic map from multi-view street-level imagery
- Defines a semantic map as an overhead, or birds eye view of a region with associated semantic object labels, such as car, road and pavement
- Formulates the problem using two conditional random fields:
- The first is used to model the semantic image segmentation of the street view imagery treating each image independently
- The outputs of this stage are then aggregated over many images to form the input for our semantic map that is a second random field defined over a ground plane
- Each image is related by a geometrical function that back projects a region from the street view image into the overhead ground plane map.
- Evaluates on introduced and make publicly available, a new dataset created from real world data
| Object Detection Methods | |||
|
CVPR 2013
Sermanet2013CVPR | |||

- Convolutional network model for pedestrian detection
- Model uses
- multi-stage features
- connections that skip layers to integrate global information
- unsupervised method based on convolutional sparse coding
- Reported at that time the best results on all major pedestrian datasets (INRIA, GTSRB,SVHN)
| Optical Flow Methods | |||
|
CVPR 2016
Sevilla-Lara2016CVPR | |||

- Previous optical flow methods used generic, spatially homogeneous assumptions about the spatial structure
- Optical flow varies depending on object class
- Propose to segment the image into objects of different kinds
- Exploiting the recent advances in static semantic segmentation
- Different motion models for regions depending on the type of object
- Roads are modeled with homographies, vegetation with spatially smooth flow, independent moving objects with affine motion plus deviations
- Pose flow estimation problem using a novel formulation of localized layers
- Evaluation on KITTI 2015 and videos from Youtube
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
THREEDV 2014
Shan2014THREEDV | |||

- Geo-registering ground-based multi-view stereo models by ground-to-aerial image matching
- Fully automated matching method that handles ground to aerial viewpoint variation
- Approximate ground-based MVS model by GPS-based geo-registration using EXIF tags
- Retrieve oblique aerial views from Google Maps based on estimated geo-location
- Feature matches between ground and aerial images for pixel-level accuracy
- Large-scale experiments which consist of many popular outdoor landmarks in Rome using images from Flickr
- Outperforms state-of-the-art significantly and yields geo-registration at pixel-level accuracy
| End-to-End Learning for Autonomous Driving Methods | |||
|
NIPSWORK 2016
Sharifzadeh2016NIPSWORK | |||
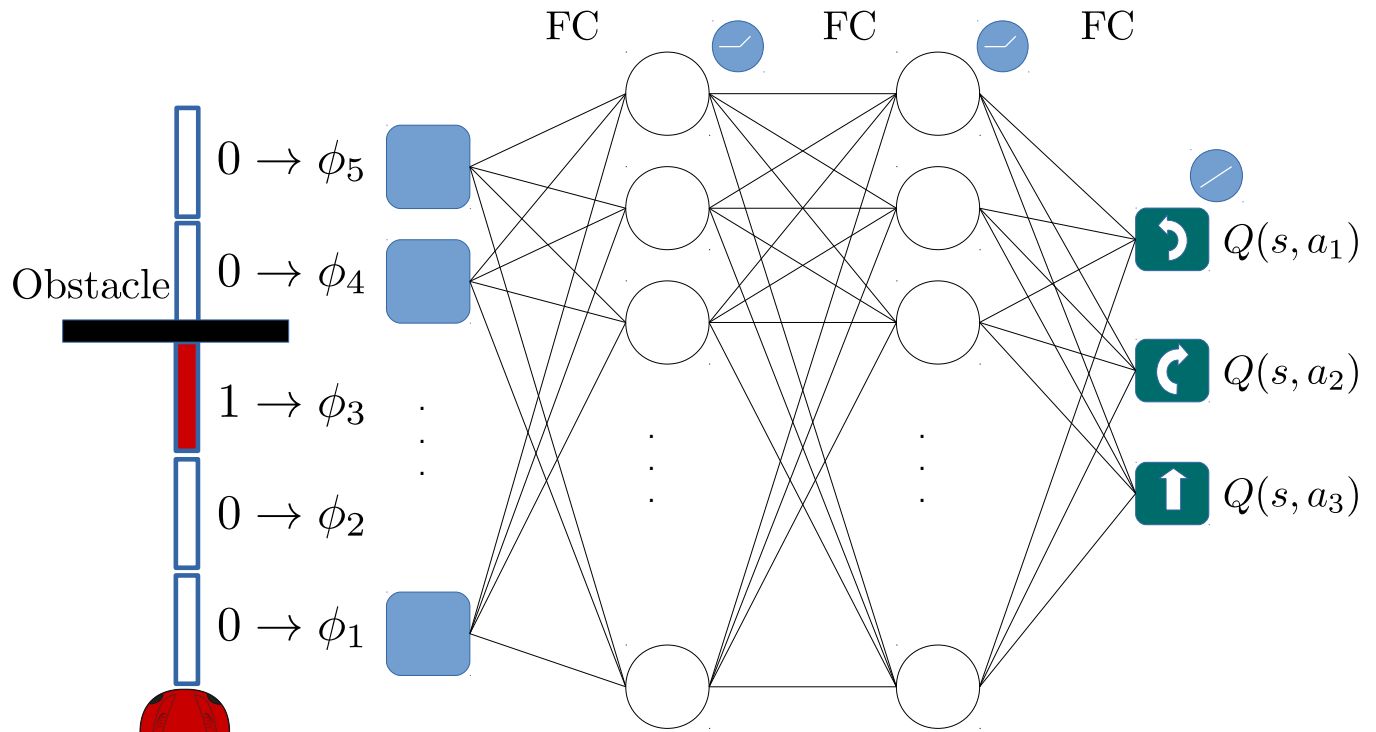
- Contributions:
- Proposes use of Deep Q-Networks as the refinement step in Inverse Reinforcement Learning approaches
- This allows extraction of the rewards in scenarios with large state spaces such as driving
- Simulated agent generates collision-free motions and performs human-like lane change behaviour
- Evaluate the performance in a simulation-based autonomous driving scenario
| Object Detection Methods | |||
|
IV 2004
Shashua2004IV | |||

- Functional and architectural breakdown of a monocular pedestrian detection system targeting on-board driving assistance application
- Single-frame classification based on a novel scheme of breaking down the class variability
- Repeatedly training a set of relatively simple classifiers on clusters of training set
- Integration of additional cues in a final system measured over time (dynamic gait, motion parallax, stability of re-detection)
- Training and evaluation on recorded data
| Semantic Segmentation Methods | |||
|
TextonBoost for Image Understanding: Multi-Class Object Recognition and Segmentation by Jointly Modeling Texture, Layout, and Context[scholar]
|
IJCV 2009
Shotton2009IJCV | ||
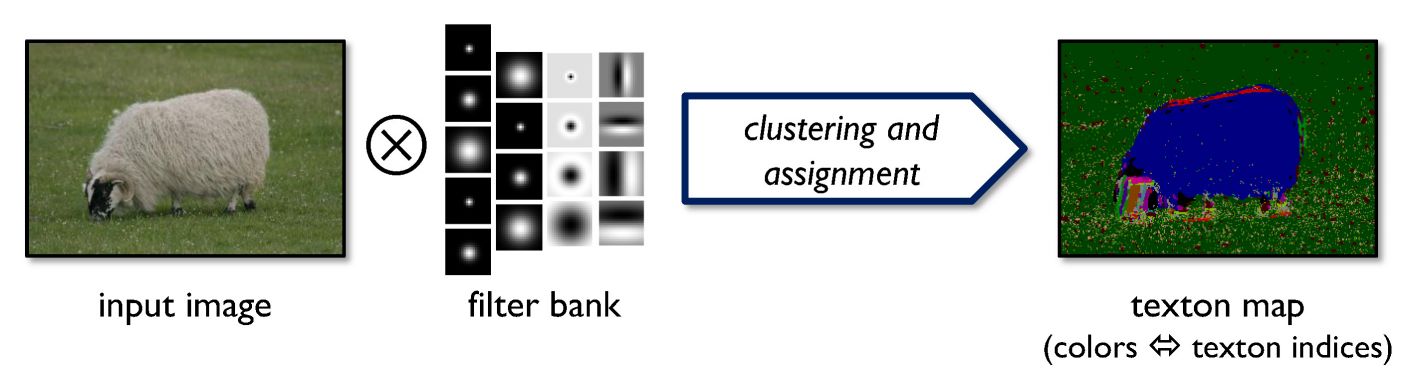
- Previous methods only exploited simple features such as color, edge and texture.
- They observed that more powerful features can significantly boost performance.
- Proposed an approach based on a novel type of features called texture-layout filter that exploits the textural appearance of objects, its layout and textural context.
- They combine texture-layout filters with lower-level image features in a CRF to obtain pixel-level segmentations.
- Randomized boosting & piecewise training techniques are exploited to efficiently train the model.
- Demonstrate performance on 4 different datasets including MSRC 21-class database.
| Optical Flow Methods | |||
|
CVPR 1991
Simoncelli1991CVPR | |||

- Extension of gradient methods to compute probability distributions of optical flow
- Distributions allow to represent uncertainties facilitating the combination with other cues
- Demonstration on a synthetic image sequence
- Probabilistic model accounts for errors in the flow estimation
- Also provide a few results on real images
| Semantic Segmentation Methods | |||
|
ICLR 2015
Simonyan2015ICLR | |||

- Existing work on ConvNet architecture design does not address the important aspect of ConvNet architecture depth.
- To this end, they fix other parameters of the architecture & steadily increase the depth of the network by adding more convolutional layers.
- Contributions:
- Evaluated very deep convolutional networks up to 19 weight layers for largescale image classification.
- Demonstrated that the representation depth is beneficial for the classification accuracy a conventional ConvNet architecture.
- Showed that their models generalize well to a wide range of tasks, matching or outperforming more complex recognition pipelines built around less deep image representations.
- Evaluates on ILSVRC classification and localisation tasks.
| Object Tracking Datasets | |||
|
CLEAR 2007
Stiefelhagen2007CLEAR | |||
- A summary of the first CLEAR evaluation on CLassification of Events, Activities and Relationships
- Definition of common evaluation tasks and metrics
- Tasks considered: person tracking, face detection and tracking, person identification, head pose estimation, vehicle tracking as well as acoustic scene analysis
- More than 20 sub-tasks including acoustic, visual and audio-visual analysis
- tracking tasks (faces/persons/vehicles,2D/3D,acoustic/visual/audio-visual)
- person identification tasks (acoustic, visual, audio-visual)
- head pose estimation (single view studio data, multi-view lecture data)
- acoustic scene analysis (events, environments)
- Different data domains and evaluation conditions
| Object Tracking Metrics | |||
|
CLEAR 2007
Stiefelhagen2007CLEAR | |||
- A summary of the first CLEAR evaluation on CLassification of Events, Activities and Relationships
- Definition of common evaluation tasks and metrics
- Tasks considered: person tracking, face detection and tracking, person identification, head pose estimation, vehicle tracking as well as acoustic scene analysis
- More than 20 sub-tasks including acoustic, visual and audio-visual analysis
- tracking tasks (faces/persons/vehicles,2D/3D,acoustic/visual/audio-visual)
- person identification tasks (acoustic, visual, audio-visual)
- head pose estimation (single view studio data, multi-view lecture data)
- acoustic scene analysis (events, environments)
- Different data domains and evaluation conditions
| Semantic Segmentation Methods | |||
|
The path less taken: A fast variational approach for scene segmentation used for closed loop control[scholar]
|
IROS 2016
Suleymanov2016IROS | ||
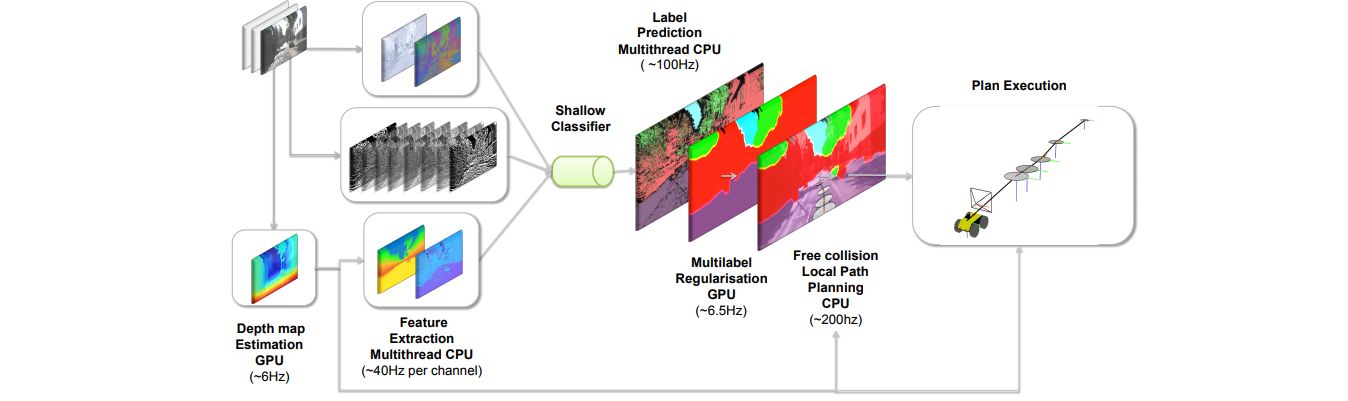
- Existing methods don't exploit fact that outdoor scenes can be decomposed into small number of independently moving 3D objects
- Absence of realistic benchmarks with scene flow ground truth
- Contributions:
- Propose an online system to detect collision-free traversable paths based on stereo estimation using a variational approach
- Also establishes a semantic segmentation of the scene
- Introduces the first realistic and large-scale scene flow dataset
- Evaluates on stereo and flow KITTI benchmarks
| Optical Flow Methods | |||
|
IJCV 2014
Sun2014IJCV | |||
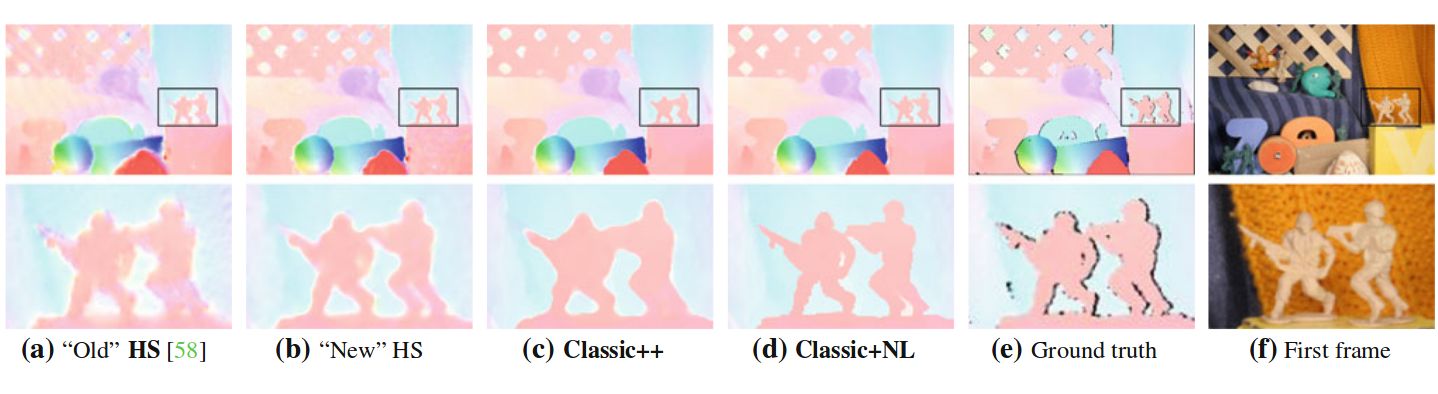
- Modern variational optical flow methods have not changed significantly in the formulation while steadily improving in performance
- Thorough analysis uncovers the reason for these advances
- Considering the objective function, optimization method and modern implementation practices
- Median filtering of intermediate flow fields improves robustness while leading to higher energy solutions
- Derivation of a new objective function from the median filtering heuristic
- Non-local smoothness term by including information about flow and image boundaries
- Evaluation on Middlebury, Sintel and KITTI
| Object Detection Methods | |||
|
CVPR 2015
Szegedy2015CVPR | |||
- Propose a deep convolutional neural network architecture called Inception.
- The main hallmark of this architecture is the improved utilization of the computing resources inside the network.
- This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant.
- To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing.
- Demonstrate performance on ILSVRC14 2014 competitions.
| Semantic Segmentation Methods | |||
|
CVPR 2015
Szegedy2015CVPR | |||
- Propose a deep convolutional neural network architecture called Inception.
- The main hallmark of this architecture is the improved utilization of the computing resources inside the network.
- This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant.
- To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing.
- Demonstrate performance on ILSVRC14 2014 competitions.
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
CVPR 2015
Szegedy2015CVPR | |||
- Propose a deep convolutional neural network architecture called Inception.
- The main hallmark of this architecture is the improved utilization of the computing resources inside the network.
- This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant.
- To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing.
- Demonstrate performance on ILSVRC14 2014 competitions.
| Semantic Instance Segmentation Methods | |||
|
GCPR 2016
Uhrig2016GCPR | |||
- Existing state-of-the-art methods have augmented convolutional neural networks (CNNs) with complex multitask architectures or computationally expensive graphical models
- Contributions:
- Presents a fully convolutional network that predicts pixel-wise depth, semantics, and instance-level direction cues for holistic scene understanding
- Instead of complex architectures or graphical models this performs post-processing using only standard computer vision techniques applied to the networks 3 output channels
- This approach does not depend on region proposals and scales for arbitrary numbers of object instances in an image
- Evaluates KITTI and Cityscapes instance segmentation datasets
| Object Detection Methods | |||
|
IJCV 2013
Uijlings2013IJCV | |||
- Problem of generating possible objection locations for object recognition
- Selective Search combines the strength of an exhaustive search and segmentation
- All possible objects locations are captured
- Image structure guides the sampling process
- Yields small set of data-driven, class-independent, high quality locations
- 99 recall and 0.879 Mean Average Best Overlap at 10,097 locations
- Demonstration with Bag-of-Words model for recognition
| Optical Flow Methods | |||
|
BC 1988
Uras1988BC | |||

- Shows that optical flow from a sequence of time-varying images is not in general an underconstrained problem
- Present a local optical flow algorithm
- Uses second order derivatives of image brightness pattern
- Avoids the aperture problem
- Obtained optical flow is very similar to the true motion field
- Demonstration on sequences of real images
| Semantic Segmentation Methods | |||
|
CVPR 2013
Valentin2013CVPR | |||
- Object labelling in 3D
- A triangulated meshed representation of the scene from multiple depth estimates
- TSDF followed by surface reconstruction
- CRF over the mesh combining information from
- Geometric properties (from the 3D mesh)
- Appearance properties (from images)
- Local interactions by difference in colour and geometry of neighbouring faces
- Evaluated in both indoor and outdoor scenes:
- Augmented version of the NYU indoor scene dataset
- Ground truth object labellings for the KITTI odometry dataset
| 3D Scene Flow Methods | |||
|
ICCV 1999
Vedula1999CVPR | |||
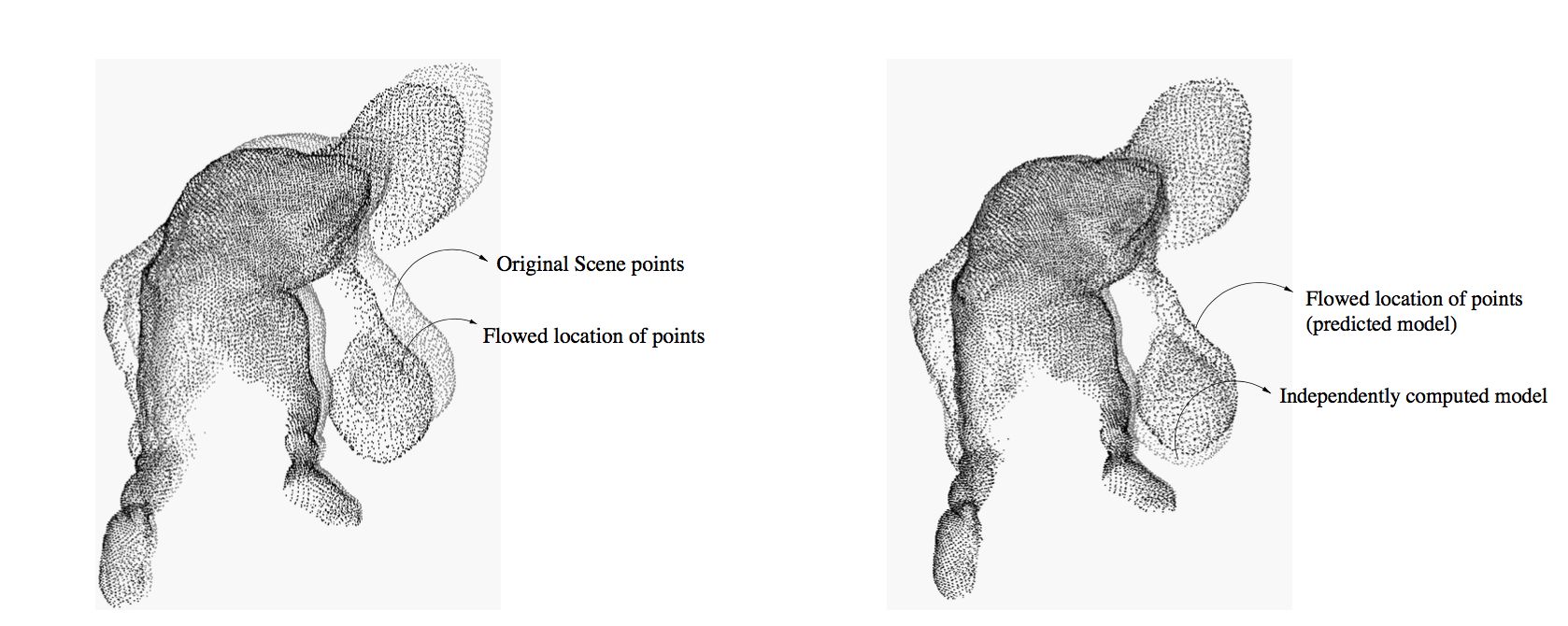
- A frame-work for the computation of dense, non-rigid scene flow from optical flow
- Preliminaries for scene flow
- A classification of the task into three major scenarios:
- complete instantaneous knowledge of the scene structure
- knowledge only of correspondence information
- no knowledge of the scene structure
- An algorithm for each scenario
| Semantic Segmentation Methods | |||
|
IJCV 2014
Verdie2014IJCV | |||
- Markov point processes are probabilistic models introduced to extend the traditional MRFs by using an object-based formalism
- Markov point processes can address object recognition problems by directly manipulating parametric entities in dynamic graphs,whereas MRFs are restricted to labeling problems in static graphs
- Contributions:
- Contrary to the conventional MCMC sampler which evolves solution by successive perturbations, it can perform a large number of perturbations simultaneously
- Proposes an efficient mechanism for modifications of objects by using spatial information extracted from the observed data
- Proposes an implementation on GPU which significantly reduces computation times with respect to existing algorithms
- To evaluate the performance of the sampler, proposes original point processe for detecting complex 3D objects in large-scale point clouds
| Semantic Segmentation Methods | |||
|
ECCV 2012
Vijayanarasimhan2012ECCV | |||
- Existing methods simply propagate annotations from arbitrarily selected frames and so may fail to best leverage the human effort invested
- Defines an active frame selection problem: select k frames for manual labeling, such that automatic pixel-level label propagation can proceed with minimal expected error
- Contributions:
- Proposes a solution that directly ties a joint frame selection criterion to the predicted errors of a flow-based random field propagation model
- Derives an efficient dynamic programming solution to optimize the criterion
- Shows how to automatically determine how many total frames k should be labeled in order to minimize the total manual effort & correcting propagation errors
- Evaluates on Labelme, Camseq, Segtrack, and Camvid datasets
| Semantic Segmentation Methods | |||
|
ICRA 2015
Vineet2015ICRA | |||
- Dense, large-scale, outdoor semantic reconstruction of a scene
- Near real-time using GPUs (features not included)
- Hash-based technique for large-scale fusion
- More reliable visual odometry instead of ICP camera pose estimation
- 2D features and unaries based on random forest classifier for semantic segmentation and transferring them to 3D volume
- An online volumetric mean-field inference algorithm for densely-connected CRFs
- A semantic fusion approach to handle dynamic objects
- Output: Per-voxel probability distribution instead of a single label
- Evaluated on KITTI
- Semantic fusion improves segmentation results, especially for cars.
- Reconstruction improves upon initial depth estimation.
- Sharp boundaries on sequences captured using a head-mounted stereo camera
| Object Detection Methods | |||
|
IJCV 2004
Viola2004IJCV | |||

- Face detection framework achieving high detection rates while being extremely efficient
- New image representation called Integral Image allows quick computation of features
- Simple and efficient classifier which is built using AdaBoost
- Combining classifiers in a cascade which allows quick exclusion of background regions
- Comparable performance to the best previous systems
- 15 frames per second on an conventional desktop
| Object Detection Methods | |||
|
IJCV 2005
Viola2005IJCV | |||
- Pedestrian detection system
- Detection style algorithm scans a detector over two consecutive frames
- Integrates image intensity information with motion information
- AdaBoost detects walking persons using appearance and motion
- Efficient representation of image motion
- Works on small scales (20x15), has low false positive rate and runs at 4 fps
| Optical Flow Methods | |||
|
GCPR 2013
Vogel2013GCPR | |||

- Appropriate data cost functions necessary for outdoor challenges like shadows, reflections
- Evaluation so far
- certain types of data costs
- data without outdoor challenges
- Contribution
- Systematic evaluation of pixel- and patch-based data costs (Brightness constancy, normalized cross correlation, mutual information, census transform)
- Approximation of census transform for gradient-based methods
- Unified state-of-the-art testbed
- Evaluation on realistic KITTI dataset
- On real world data patch-based perform better than pixel-based costs
- Census transform slightly outperforms all others
| Optical Flow Discussion | |||
|
GCPR 2013
Vogel2013GCPR | |||
- Appropriate data cost functions necessary for outdoor challenges like shadows, reflections
- Evaluation so far
- certain types of data costs
- data without outdoor challenges
- Contribution
- Systematic evaluation of pixel- and patch-based data costs (Brightness constancy, normalized cross correlation, mutual information, census transform)
- Approximation of census transform for gradient-based methods
- Unified state-of-the-art testbed
- Evaluation on realistic KITTI dataset
- On real world data patch-based perform better than pixel-based costs
- Census transform slightly outperforms all others
| 3D Scene Flow Methods | |||
|
IJCV 2015
Vogel2015IJCV | |||
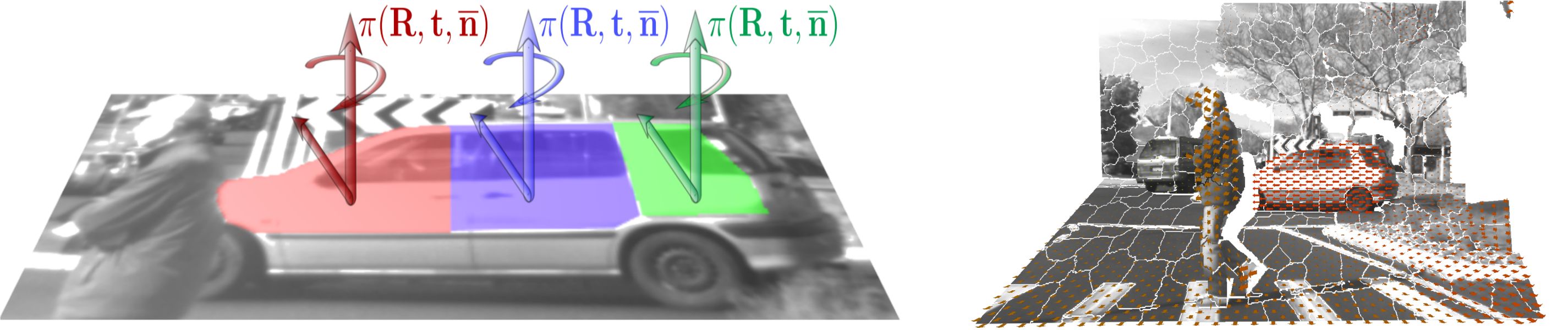
- Limitations of existing methods:
- Conventional pixel-based representations require large number of parameters leading to challenging inference
- Parameterize w.r.t. a single viewpoint and therefore may ignore important evidence present in other views
- Contributions:
- Represents dynamic scenes as a collection of planar regions, each undergoing a rigid motion
- Represents 3D shape and motion w.r.t. every image in a time interval while demanding consistency of the representations
- Evaluates on stereo and flow KITTI benchmarks
| 3D Scene Flow State of the Art on KITTI | |||
|
IJCV 2015
Vogel2015IJCV | |||
- Limitations of existing methods:
- Conventional pixel-based representations require large number of parameters leading to challenging inference
- Parameterize w.r.t. a single viewpoint and therefore may ignore important evidence present in other views
- Contributions:
- Represents dynamic scenes as a collection of planar regions, each undergoing a rigid motion
- Represents 3D shape and motion w.r.t. every image in a time interval while demanding consistency of the representations
- Evaluates on stereo and flow KITTI benchmarks
| 3D Scene Flow Discussion | |||
|
IJCV 2015
Vogel2015IJCV | |||
- Limitations of existing methods:
- Conventional pixel-based representations require large number of parameters leading to challenging inference
- Parameterize w.r.t. a single viewpoint and therefore may ignore important evidence present in other views
- Contributions:
- Represents dynamic scenes as a collection of planar regions, each undergoing a rigid motion
- Represents 3D shape and motion w.r.t. every image in a time interval while demanding consistency of the representations
- Evaluates on stereo and flow KITTI benchmarks
| Object Detection Methods | |||
|
RSS 2015
Wang2015RSS | |||
- Sliding window approach for laser-based 3D object detection
- A voting scheme by exploiting sparsity
- Enabling a search through all putative object locations at any orientation
- Mathematically equivalent to a convolution on a sparse feature grid (a linear classifier)
- Processing in full 3D, irrespective of the number of vantage points
- Highly parallelisable (processing 100K points at eight orientations in less than 0.5s)
- The best-in-class detection and timing for car, pedestrian and bicyclist on KITTI
| Object Tracking Datasets | |||
|
PAMI 2015
Wang2015PAMI | |||
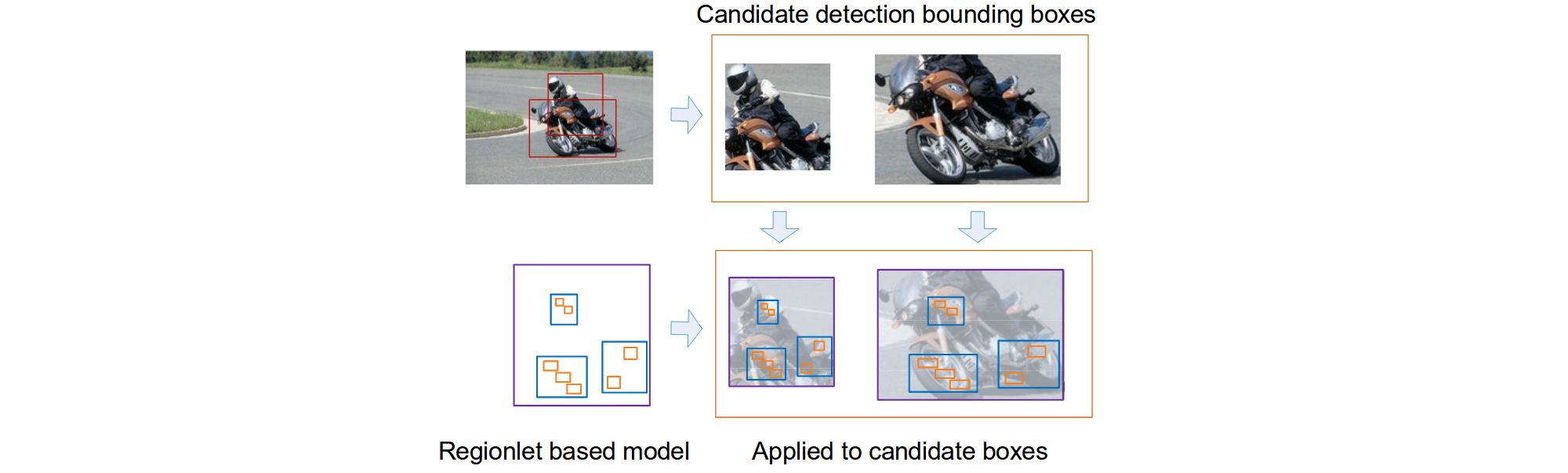
- Generic object detection demands for efficient, descriptive and flexible object representations
- Model an object class by a cascaded boosting classifier
- Integrates various types of features from competing local regions (Regionlets)
- Regionlets
- Feature extraction region proportionally to a detection window at any resolution
- Organized in small groups with stable relative positions
- Features are aggregated to a one-dimensional feature within one group
- Allow deformations within one group (object)
- Evaluate object bounding box proposal in selective search from segmentation cues
- Evaluation on PASCAL VOC 2007,2010 and ImageNet
| 3D Scene Flow Methods | |||
|
IJCV 2011
Wedel2011IJCV | |||
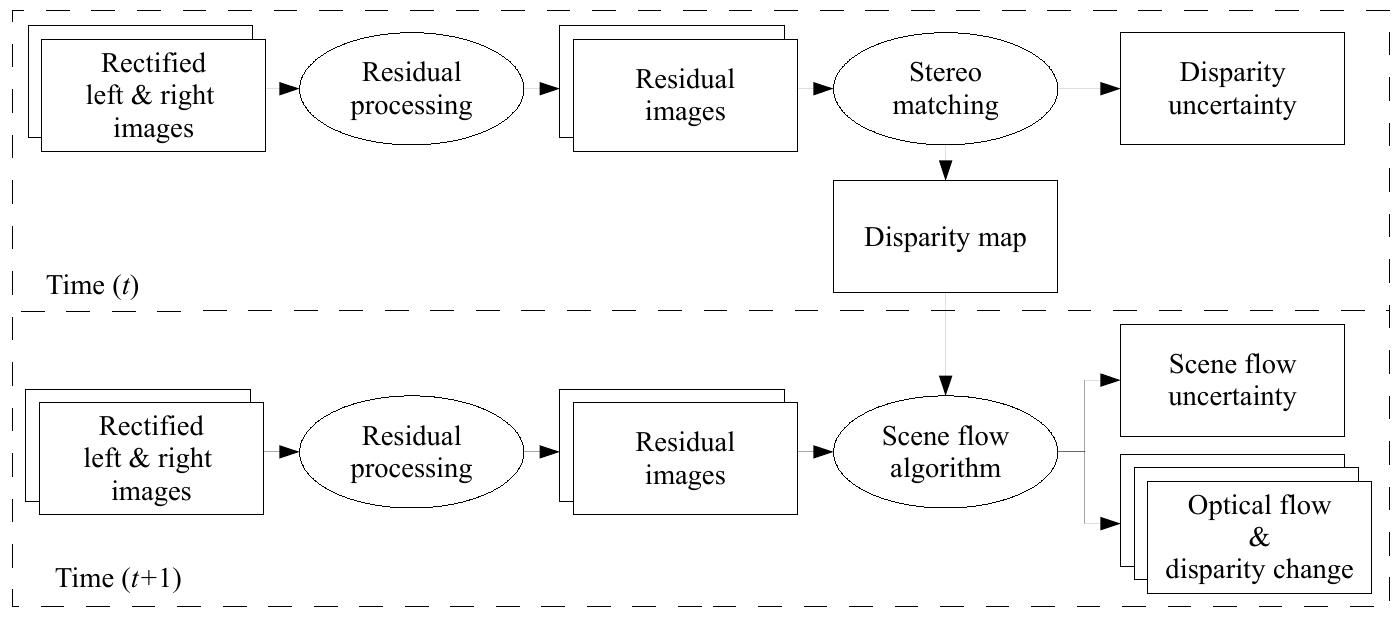
- 3D motion estimation using a variational framework and depth estimation
- Decoupling motion from depth estimation
- Allows to use most suitable method for the two problems
- Stereo matching used as constraint for the motion estimation
- Faster computation on FPGA (depth) and GPU (motion)
- Use TV-L2 smoothing to remove illumination differences between images
- Energy-based uncertainty measure from motion estimation improves motion segmentation
- Evaluation on the synthetic data (rotating sphere and Povray Traffic Scene)
- Qualitative results on real-world scenes
| Semantic Segmentation Methods | |||
|
TITS 2009
Wedel2009TITS | |||

- Planar road surface assumption is not modeling slope changes and cannot be used to restrict the free space
- Representation of the visible road surface based on general parametric B-spline curve
- Surface parameters are estimated from stereo measurements in the free space and are tracked over time using a Kalman filter
- Adopt a road-obstacle segmentation algorithm to use the B-spline road representation
- Evaluation on recorded data shows accurate free space estimation when the planar assumption fails
| 3D Scene Flow Methods | |||
|
ECCV 2008
Wedel2008ECCV | |||

- Scene flow using two consecutive image pairs from a stereo sequence
- Decoupling the position and velocity estimation steps
- Solving two sub-problems efficiently rather than the joint problem
- Choosing optimal methods for estimating both disparity and velocity
- Estimating dense velocities using a variational approach
- Results on synthetic and real-world scenes
| Semantic Segmentation Methods | |||
|
CVPR 2016
Wegner2016CVPR | |||
- Public tree cataloguing (of location and species of trees) system from online maps
- Motivation:
- Large-scale tree mapping project called Opentreemap
- Currently carried out with specialized imagery (LiDAR, hyperspectral) that is collected ad-hoc, and/or with in-person visits
- det2geo: detects the set of locations of objects of a given category
- geo2cat: computes the fine-grained category of the 3D object at a given location
- Challenge: Combining multiple aerial and street-level views
- Adapting state-of-the-art CNN-based object detectors and classifiers
- Pasadena Urban Trees dataset: 80,000 trees with geographic and species annotations
- Multi-view recognition over single view
- Mean average precision from 42 to 71 for tree detection
- Accuracy from 70 to 80 for tree species recognition
| Semantic Segmentation Methods | |||
|
CVPR 2013
Wegner2013CVPR | |||

- Extract road network from aerial images
- Problem: Pairwise potentials smooth out thin structures
- Novel CRF with higher-order cliques connecting superpixel along line segments as prior
- Sampling scheme that concentrates on most relevant cliques with a data-driven approach
- Random Forest unaries
- Evaluation on Graz and Vaihingen road network dataset
- Outperforms a simple smoothness and heuristic rule-based baseline
| Mapping, Localization & Ego-Motion Estimation Mapping | |||
|
CVPR 2013
Wegner2013CVPR | |||
- Extract road network from aerial images
- Problem: Pairwise potentials smooth out thin structures
- Novel CRF with higher-order cliques connecting superpixel along line segments as prior
- Sampling scheme that concentrates on most relevant cliques with a data-driven approach
- Random Forest unaries
- Evaluation on Graz and Vaihingen road network dataset
- Outperforms a simple smoothness and heuristic rule-based baseline
| Semantic Segmentation Methods | |||
|
JPRS 2015
Wegner2015JPRS | |||

- Road extraction usually tackled with rule-based approaches
- Extension of their work that was enforcing the road to lie on line segments
- Create a large, over-complete set of candidates with minimum cost paths
- Minimum cost paths allows the regularization to arbitrary paths
- Map inference in a high-order CRF is used to select the optimal candidates
- Random forest classifier used as unary
- Evaluation on Graz and Vaihingen road network dataset
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
THREEDV 2014
Wei2014THREEDV | |||
- Resolving local ambiguity of the disparity or flow
- by considering the semantic information
- without explicit object modelling
- Data driven approach:
- Transferring shape information from semantically matched patches in the database
- Relative-relationship transfer (by subtracting disparity at the center pixel) rather than data-term transfer (absolute values)
- Similar local shape information while absolute disparity values differ
- A standard MRF model using gradient descent for inference
- Comparable or better results on the KITTI stereo and flow datasets Improved results on the Sintel flow dataset
| Optical Flow Methods | |||
|
ICCV 2013
Weinzaepfel2013ICCV | |||
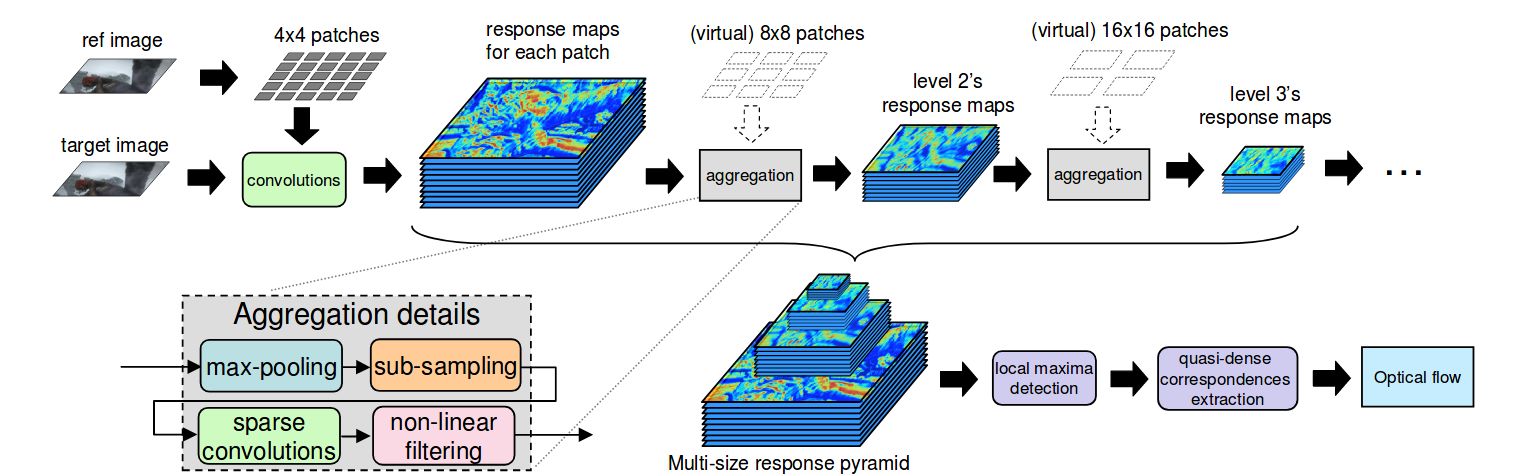
- Large displacements remains a open problem in optical flow estimation
- Propose a matching algorithm with a variational approach to obtain optical flow
- Descriptor matching algorithm building upon a multi-stage architecture
- Akin to deep convolutional nets using 6 layers, interleaving convolutions and max-pooling
- Dense sampling allows to efficiently retrieve quasi-dense correspondences
- Build-in smoothing effect on descriptors matches
- Evaluated on the MPI Sintel dataset
| 3D Scene Flow Methods | |||
|
ICCV 2013
Weinzaepfel2013ICCV | |||
- Large displacements remains a open problem in optical flow estimation
- Propose a matching algorithm with a variational approach to obtain optical flow
- Descriptor matching algorithm building upon a multi-stage architecture
- Akin to deep convolutional nets using 6 layers, interleaving convolutions and max-pooling
- Dense sampling allows to efficiently retrieve quasi-dense correspondences
- Build-in smoothing effect on descriptors matches
- Evaluated on the MPI Sintel dataset
| Semantic Segmentation Methods | |||
|
RSS 2015
Whelan2015RSS | |||
- Existing SLAM methods deal with large scale loop closures by partitioning the map and applying pose graph optimization.
- This sparse pose graph optimization is not optimal for dense visual SLAM systems.
- Contributions:
- Real time globally consistent reconstruction without pose graph optimization.
- Uses dense frame-to-model tracking and surfel based fusion.
- Incorporates local model-to-model loop closures with large scale loop closures.
- Evaluates for surface reconstruction accuracy on ICL-NUM dataset.
| Scene Understanding Methods | |||
|
ECCV 2010
Wojek2010ECCV | |||
- A probabilistic 3D scene model for multi-class object detection, object tracking, scene labelling, and 3D geometric relations
- A consistent 3D description of a scene using only monocular video
- Complex interactions like inter-object occlusion, physical exclusion between objects, geometric context
- RJMCMC for inference and HMM for long-term associations in scene tracking
- Better than state-of-the-art in 3D multi-people tracking (ETH-Loewenplatz)
- A new, challenging dataset for 3D tracking of cars and trucks: MPI-VehicleScenes
| Object Detection Methods | |||
|
DAGM 2008
Wojek2008DAGM | |||

- Powerful people detectors have been proposed
- Usually not each component is individually tested on publicly available datasets
- Thus, systematic comparison of the most prominent and successful people detectors is presented
- Based on evaluation a new detector is presented that is combining multiple features
- Outperforming the state-of-the-art at that time on INRIA person detection
| Scene Understanding Methods | |||
|
ECCV 2008
Wojek2008ECCV | |||
- Proposes a novel approach based on conditional random field (CRF) models to integrate both object detection and scene labeling in one framework
- Contributions:
- Formulates the integration as a joint labeling problem of object and scene classes
- Systematically integrates dynamic information for the object detection task as well as for the scene labeling task
- Evaluates on Sowerby database and a new dynamic scenes dataset
| Scene Understanding Methods | |||
|
CVPR 2011
Wojek2011CVPR | |||

- Monocular 3D scene tracking-by-detection witch explicit object-object occlusion reasoning
- Tracking the complete scene rather than an assembly of individuals
- Extension of detection approaches HOG and DPM to enable the detection of partially visible humans
- Integration of the detections into a 3D scene model
- Full object and object part detectors are combined in a mixture of experts based on visibility
- Visibility is obtained from the 3D scene model
- More robust detection and tracking of partially visible pedestrians
- Evaluation on two challenging sequences ETH-Linthescher and ETH-PedCross2 recorded from a moving car in busy pedestrian zones
| Scene Understanding Discussion | |||
|
CVPR 2011
Wojek2011CVPR | |||
- Monocular 3D scene tracking-by-detection witch explicit object-object occlusion reasoning
- Tracking the complete scene rather than an assembly of individuals
- Extension of detection approaches HOG and DPM to enable the detection of partially visible humans
- Integration of the detections into a 3D scene model
- Full object and object part detectors are combined in a mixture of experts based on visibility
- Visibility is obtained from the 3D scene model
- More robust detection and tracking of partially visible pedestrians
- Evaluation on two challenging sequences ETH-Linthescher and ETH-PedCross2 recorded from a moving car in busy pedestrian zones
| Scene Understanding Methods | |||
|
PAMI 2013
Wojek2013PAMI | |||
- A probabilistic 3D scene model for multi-class object detection, object tracking, scene labelling, and 3D geometric relations using monocular video as input
- Extension of Wojek2010ECCV1 with explicit occlusion reasoning for tracking objects that are partially occluded or that have never been observed to their full extent
- Evaluated on ETH-Loewenplatz, ETH-Linthescher, ETH-PedCross2, MPI-VehicleScenes
- Robust performance due to
- a strong tracking-by-detection framework with tracklets
- exploiting 3D scene context by combining multiple cues
- Explicit occlusion reasoning improves results on all sequences.
- Long-term tracking with an HMM does not lead to additional gains.
- Improvement over state-of-the-art object detectors, a stereo-based system, a competing monocular system, basic Kalman filters
1. Monocular 3D Scene Modeling and Inference: Understanding Multi-Object Traffic Scenes, ECCV 2010
| Scene Understanding Discussion | |||
|
PAMI 2013
Wojek2013PAMI | |||
- A probabilistic 3D scene model for multi-class object detection, object tracking, scene labelling, and 3D geometric relations using monocular video as input
- Extension of Wojek2010ECCV1 with explicit occlusion reasoning for tracking objects that are partially occluded or that have never been observed to their full extent
- Evaluated on ETH-Loewenplatz, ETH-Linthescher, ETH-PedCross2, MPI-VehicleScenes
- Robust performance due to
- a strong tracking-by-detection framework with tracklets
- exploiting 3D scene context by combining multiple cues
- Explicit occlusion reasoning improves results on all sequences.
- Long-term tracking with an HMM does not lead to additional gains.
- Improvement over state-of-the-art object detectors, a stereo-based system, a competing monocular system, basic Kalman filters
1. Monocular 3D Scene Modeling and Inference: Understanding Multi-Object Traffic Scenes, ECCV 2010
| Object Detection Methods | |||
|
CVPR 2009
Wojek2009CVPR | |||

- Detecting pedestrians using an onboard camera
- Existing methods rely on static image features only despite the obvious potential of motion information for people detection
- Contributions:
- Shows that motion cues provide a valuable feature, also for detection from a moving platform
- Shows that MPLBoost and histogram intersection kernel SVMs can successfully learn a multi-viewpoint pedestrian detector and often out- perform linear SVMs
- Introduces new realistic and publicly available onboard dataset (TUD-Brussels) containing multi-viewpoint data is introduced
- Evaluates on ETH-Person, TUD-Brussels dataset
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
CVPR 2016
Wolff2016CVPR | |||
- Detecting and matching building facades between aerial view and street-view images
- Challenges beyond patch matching and ground-level-only wide-baseline facade matching
- Exploiting the regularity of urban scene facades
- Using a lattice and its associated median tiles (motifs) as the basis for matching
- Joint regularity optimization problem, seeking well-defined features that reoccur across both facades to serve as match indicators
- Matching costs based on edge shape contexts, color features, and Gabor filter responses
- Evaluated on three cities
- Superior performance over baselines SIFT, Root-SIFT, and Scale- Selective Self-Similarity and Binary Coherent Edge descriptors
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
ICCV 2015
Workman2015ICCV | |||
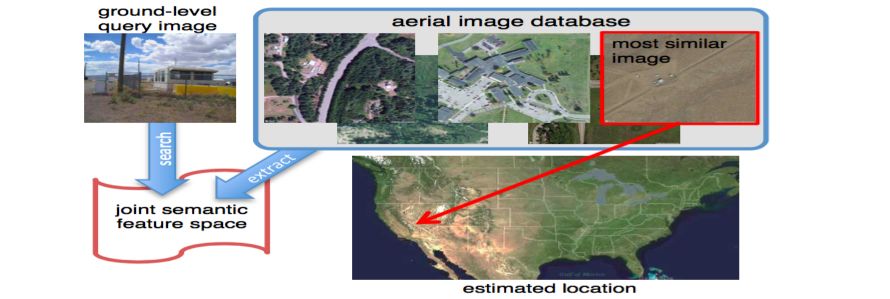
- Proposes to use deep convolutional neural networks to address the problem of cross-view image geolocalization
- Geolocation of a ground-level query image is estimated by matching to georeferenced aerial images
- Contributions:
- Evaluation of off-the-shelf CNN network architectures & target label spaces for the problem of cross- view localization
- Cross-view training for learning a joint semantic feature space from different image sources
- Evaluates on new dataset that contains pairs of aerial and ground-level images from across the United States.
| Object Tracking Methods | |||
|
Detection and Tracking of Multiple, Partially Occluded Humans by Bayesian Combination of Edgelet Part Detectors[scholar]
|
IJCV 2007
Wu2007IJCV | ||
| Object Detection Methods | |||
|
PAMI 2016
Wu2016PAMI | |||
- Car detection and viewpoint estimation from images
- And-Or model embeds a grammar for representing large structural and appearance variations in a reconfigurable hierarchy
- Learning an And-Or model that takes into account structural and appearance variations at multi-car, single-car and part levels jointly
- Learning process consists of two stages in a weakly supervised way
- The structure of the model is learned mining multi-car contextual patterns, occlusion configurations, combination of parts
- Model parameters are jointly trained using Weak-Label Structural SVM
- Evaluation of car detection with KITTI, PASCAL VOC2007 car dataset, and two self-collected car dataset and car viewpoint estimation with PASCAL VOC2006, PASCAL3D+
| Optical Flow Methods | |||
|
CVPR 2015
Wulff2015CVPR | |||
- Representing optical flow as a weighted sum of the basis flow fields
- Given a set of sparse matches, regressing to dense optical flow using a learned set of full-frame basis flow fields
- Learning the principal components using flow computed from four Hollywood movies
- Very fast (200ms/frame), but too smooth
- Sparse layered flow, each layer is PCA-Flow (3.2s/frame)
- Evaluated on Sintel and KITTI 2012 benchmarks
| Object Tracking Methods | |||
|
ICCV 2015
Xiang2015ICCV | |||
- Online multi-object tracking (MOT)
- Challenge: robustly associating noisy, new detections with previously tracked objects
- Formulated as decision making in Markov Decision Processes (MDPs), where the lifetime of an object is modeled with a MDP
- Data association (learning a similarity function) as learning a policy for the MDP as in reinforcement learning
- Benefiting from both offline- and online-learning for data association
- The birth/death and appearance/disappearance of targets by treating them as state transitions in the MDP
- Better than the state-of-the-art on MOT Benchmark
| Object Tracking State of the Art on MOT & KITTI | |||
|
ICCV 2015
Xiang2015ICCV | |||
- Online multi-object tracking (MOT)
- Challenge: robustly associating noisy, new detections with previously tracked objects
- Formulated as decision making in Markov Decision Processes (MDPs), where the lifetime of an object is modeled with a MDP
- Data association (learning a similarity function) as learning a policy for the MDP as in reinforcement learning
- Benefiting from both offline- and online-learning for data association
- The birth/death and appearance/disappearance of targets by treating them as state transitions in the MDP
- Better than the state-of-the-art on MOT Benchmark
| Object Detection State of the Art on KITTI | |||
|
CVPR 2015
Xiang2015CVPR | |||
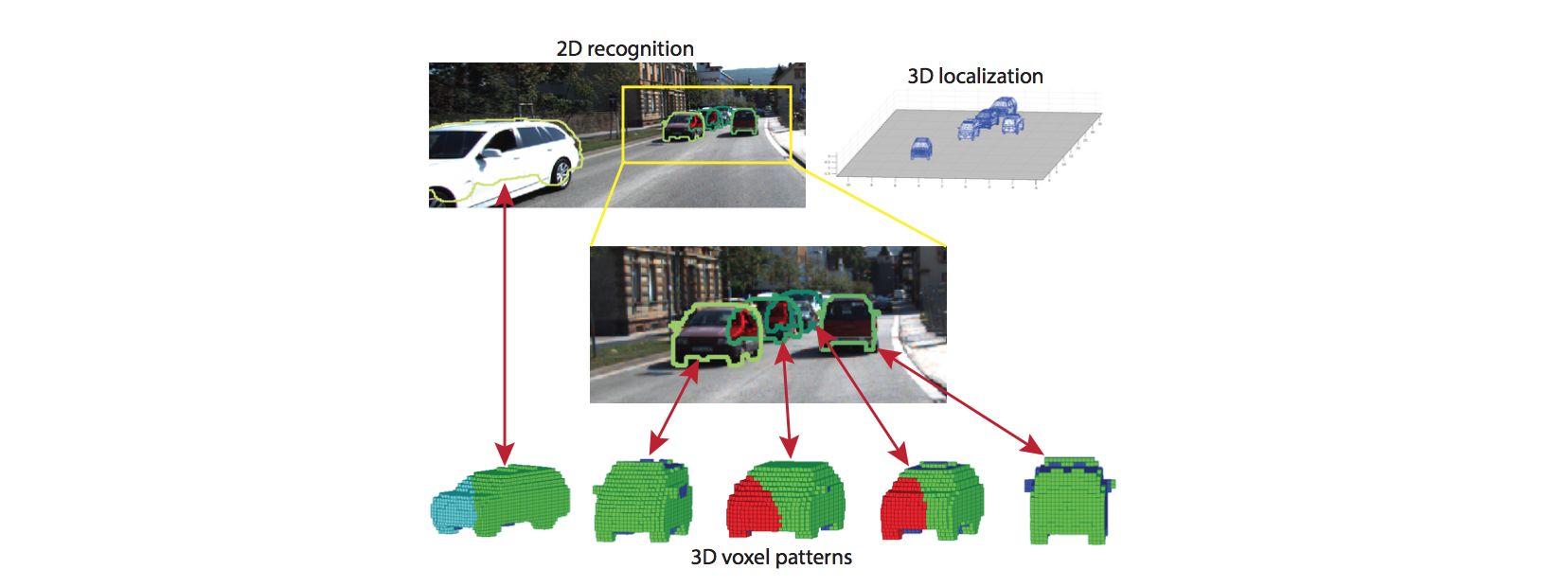
- A novel object representation: 3D Voxel Pattern (3DVP) that jointly encodes
- appearance: the RGB luminance values of the object in the image
- 3D shape: the 3D geometry of the object expressed as a collection of 3D voxels
- occlusion and truncation: the portion of the object that is visible or occluded because of self-occlusions, mutual occlusions and truncations
- Training a bank of specialized detectors for a dictionary of 3DVPs
- objects with specific visibility patterns
- transferring learned meta-data to other tasks eg 2D segmentation mask, 3D pose, occlusion or truncation boundaries
- Reasoning about object-object interactions, ie occluder-occludee
- Experiments on KITTI detection benchmark and another outdoor-scene dataset
| Semantic Segmentation Methods | |||
|
SIGGRAPH 2009
Xiao2009SIGGRAPH | |||

- Proposes an automatic approach to generate street-side 3D photo-realistic models from images captured along the streets at ground level
- Develops a multi-view semantic segmentation method that recognizes and segments each image at into semantically meaningful areas, each labeled with a specific object class, such as building, sky, ground, vegetation and car
- A partition scheme is then introduced to separate buildings into independent blocks using the major line structures of the scene
- For each block, proposes an inverse patch-based orthographic composition and structure analysis method for facade modeling that efficiently regularizes the noisy and missing reconstructed 3D data
- System has the distinct advantage of producing visually compelling results by imposing strong priors of building regularity
| Semantic Segmentation Methods | |||
|
ICCV 2009
Xiao2009ICCV | |||

- Multi view semantic segmentation framework for images captured by a car driving along streets
- Superpixel pairwise MRF over the entire sequence
- Spatial and temporal smoothness of semantic labels
- Boosting classifier as unary using image-based and geometric features from 3D reconstruction
- Training speedup and quality improvement with adaptive training that selects most similar training data for each scene from label pool
- Approach can be used for large-scale labeling in 2D and 3D space simultaneous
- Demonstration on Google Street View images
| Semantic Segmentation Methods | |||
|
CVPR 2016
Xie2016CVPR | |||
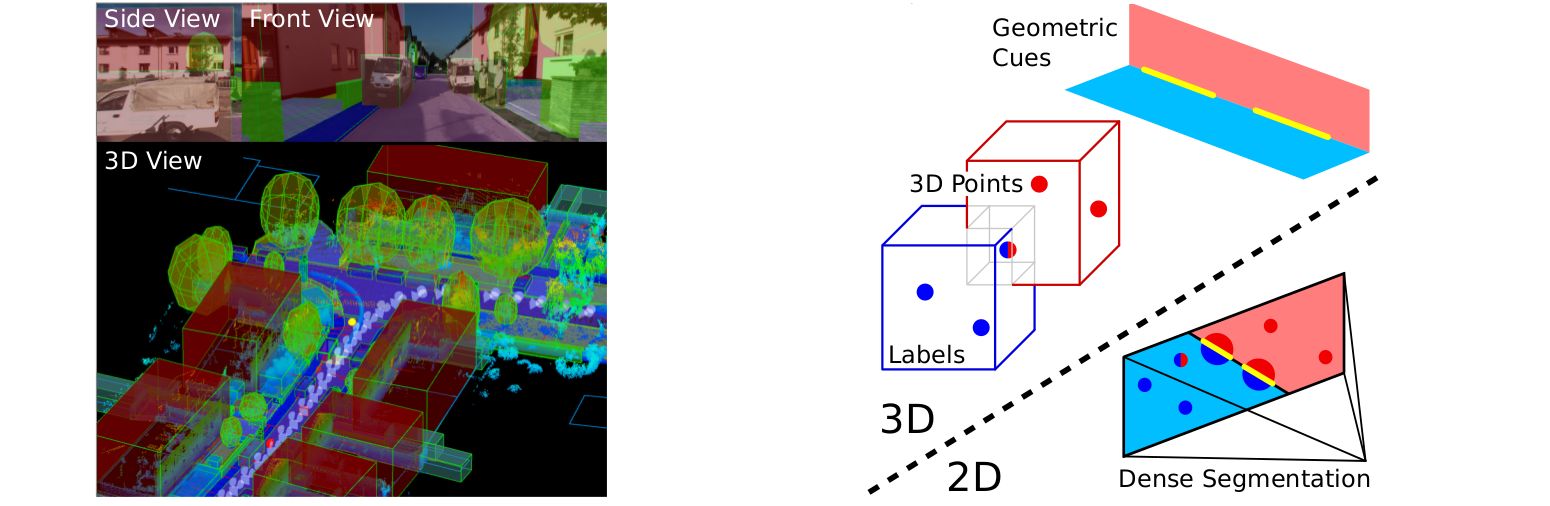
- Motivation for 3D to 2D Label Transfer:
- Objects often project into several images of the video sequence, thus lowering annotation efforts considerably.
- 2D instance annotations are temporally coherent as they are associated with a single object in 3D
- 3D annotations might be useful by themselves for reasoning in 3D or to enrich 2D annotations with approximate 3D geometry
- Contributions:
- Present a novel geo-registered dataset of suburban scenes recorded by a moving platform
- Provides semantic 3D annotations for all static scene element
- Proposes a method transfer these labels from 3D into 2D, yielding pixelwise semantic instance annotations
- The dataset comprises over 400k images and over 100k laser scans
| Stereo Methods | |||
|
ECCV 2012
Yamaguchi2012ECCV | |||

- Slanted-plane model which reasons jointly about occlusion boundaries and depth
- Existing slanting plane methods involved time-consuming optimization algorithms
- Contributions:
- Novel model involving "boundary labels", "junction potentials" & "edge ownership"
- Faster inference by employing particle convex belief propagation (PCBP)
- More effective parameter training algorithm based on Primal-dual approximate inference
- Evaluates on KITTI and Middebury high resolution images
| Optical Flow Methods | |||
|
ECCV 2014
Yamaguchi2014ECCV | |||
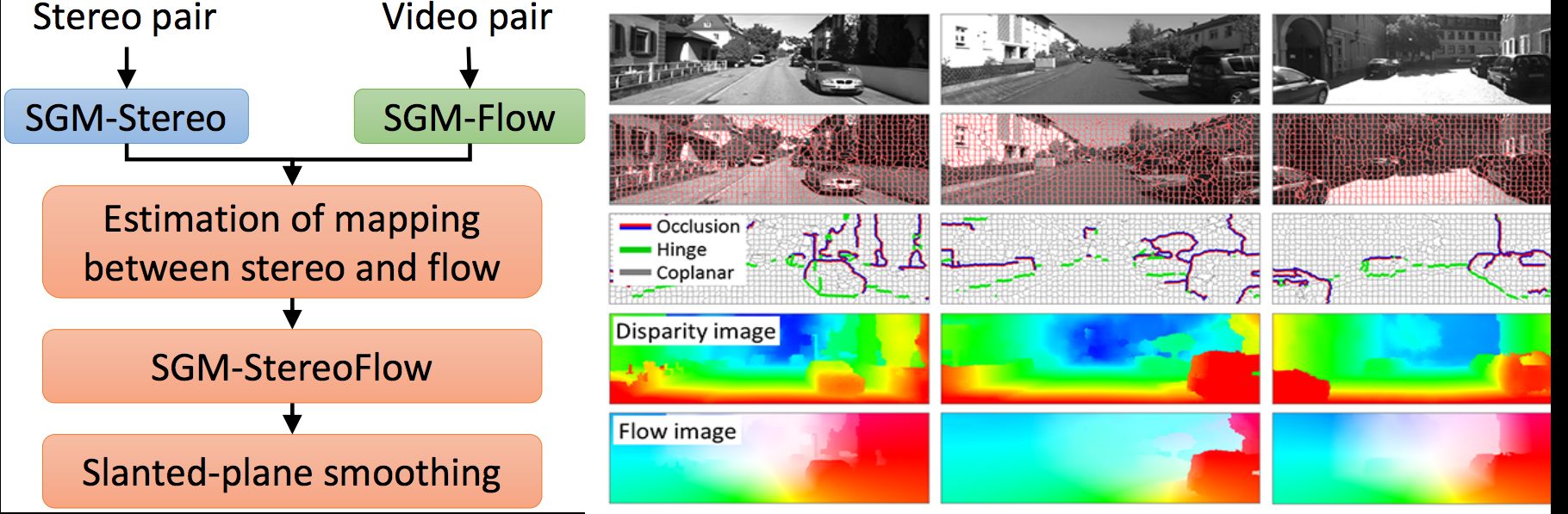
- Existing slanting plane methods involved time-consuming optimization algorithms
- Contributions:
- Exploits the fact that in autonomous driving scenarios most of the scene is static
- New SGM algorithm based on the joint evidence of the stereo and video pairs
- New fast block-coordinate descent form of inference algorithm on a total energy involving the segmentation, slanted planes and occlusion labeling
- Evaluates on stereo and flow KITTI benchmarks
- Order of magnitude faster than competing approaches
| Optical Flow Methods | |||
|
CVPR 2013
Yamaguchi2013CVPR | |||

- Limitations of existing algorithms:
- Gradient-based methods suffer in the presence of large displacements
- Matching-based methods are computationally demanding due to the large amount of candidates required
- Contributions:
- Adapts slanted plane stereo models to the problem of monocular epipolar flow estimation
- Efficient flow-aware segmentation algorithm that encourages the segmentation to respect both image and flow discontinuities
- Robust data term using a new local flow matching algorithm
- Evaluates on KITTI flow benchmark
| Object Detection Methods | |||
|
CVPR 2016
Yang2016CVPR | |||
- Current approaches (Fast RCNN):
- Problems with small objects
- Not applicable to very deep architectures due to multi-scale input
- Other time constraints due to huge number candidate bounding boxes
- Two new strategies to object detection using CNNs:
- Layer-wise cascaded rejection classifiers (CRC) to reject easy negatives in all layers
- Evaluating surviving proposals using scale-dependent pooling (SDP) Representing a candidate bounding box using the convolutional features pooled from a layer corresponding to its scale (height)
- Better accuracy compared to state-of-the-art on PASCAL, KITTI, and newly collected Inner-city dataset
| Object Detection State of the Art on KITTI | |||
|
CVPR 2016
Yang2016CVPR | |||
- Current approaches (Fast RCNN):
- Problems with small objects
- Not applicable to very deep architectures due to multi-scale input
- Other time constraints due to huge number candidate bounding boxes
- Two new strategies to object detection using CNNs:
- Layer-wise cascaded rejection classifiers (CRC) to reject easy negatives in all layers
- Evaluating surviving proposals using scale-dependent pooling (SDP) Representing a candidate bounding box using the convolutional features pooled from a layer corresponding to its scale (height)
- Better accuracy compared to state-of-the-art on PASCAL, KITTI, and newly collected Inner-city dataset
| Object Tracking Datasets | |||
|
CVPR 2016
Yang2016CVPR | |||
- Current approaches (Fast RCNN):
- Problems with small objects
- Not applicable to very deep architectures due to multi-scale input
- Other time constraints due to huge number candidate bounding boxes
- Two new strategies to object detection using CNNs:
- Layer-wise cascaded rejection classifiers (CRC) to reject easy negatives in all layers
- Evaluating surviving proposals using scale-dependent pooling (SDP) Representing a candidate bounding box using the convolutional features pooled from a layer corresponding to its scale (height)
- Better accuracy compared to state-of-the-art on PASCAL, KITTI, and newly collected Inner-city dataset
| Object Tracking State of the Art on MOT & KITTI | |||
|
WACV 2015
Yoon2015WACV | |||
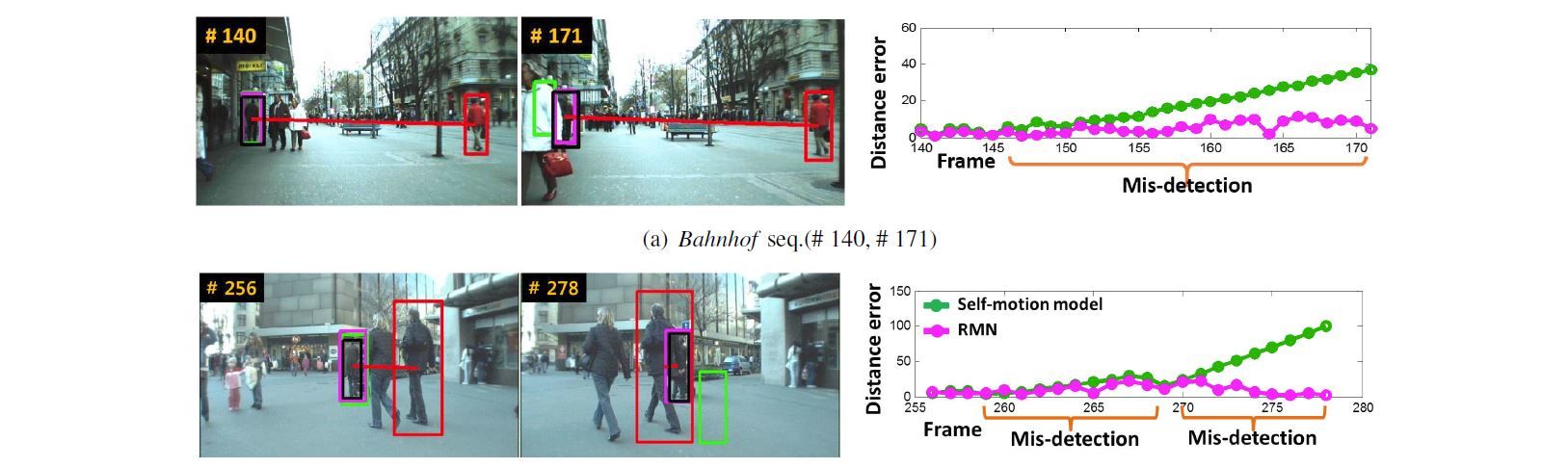
- Online multi-object tracking with a single moving camera
- 2D conventional motion models no longer hold because of global camera motion
- Consider motion context from multiple objects which describes the relative movement between objects
- Construct a Relative Motion Network to factor out the effects of unexpected camera motion
- It consists of multiple relative motion models that describe spatial relations between objects
- Can be incorporated into various multi-object tracking frameworks and is demonstrated with a tracking framework based on a Bayesian filter
- Evaluation on the ETHZ dataset
| Optical Flow Methods | |||
|
ICLR 2016
Yu2016ICLR | |||
- Convolutional network module that is specifically designed for dense prediction (semantic segmentation)
- Dilated convolutions to systematically aggregate multi-scale contextual information without losing resolution
- "The dilated convolution operator can apply the same filter at different ranges using different dilation factors."
- Front end module: VGG16 with deconvolutions (FCN) by removing the last two pooling and striding layers
- Front end is already too good: outperforms both FCN-8s and the DeepLab, and even DeepLab+CRF
- Identity initialization for the context module
- Trained on Microsoft COCO and VOC-2012 and tested on VOC-2012
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
CVPR 2015
Yu2015CVPR | |||
- Alignment of LiDAR data collected with Google Street View cars in urban environments
- Problems with current approaches:
- GPS do not work well in city environments with tall buildings
- Local tracking techniques (integration of inertial sensors, SfM, etc.) drift over long ranges, causing warped and misaligned data by many meters
- Approach: semantic features with object detectors (for facades, poles, cars, etc.) that
- can be matched robustly at different scales
- are selected for different iterations of an ICP algorithm
- Better than baselines on data from New York, San Francisco, Paris, and Rome
| Optical Flow Methods | |||
|
DAGM 2007
Zach2007DAGM | |||

- Total variation regularization in combination with robust L1 norm in the data term are among the most accurate approaches
- Preserver discontinuities in the flow field
- Offers robustness against illumination changes, occlusions and noise
- This work propose a very efficient numerical scheme to solve TV-L1 formulation
- Based on dual formulation of the TV energy and employs an efficient point-wise thresholding
- Can be accelerated by modern graphics processing units
- Real-time performance (30fps) for video inputs at 320x240
| Scene Understanding Problem Definition | |||
|
ICCV 2013
Zhang2013ICCV | |||
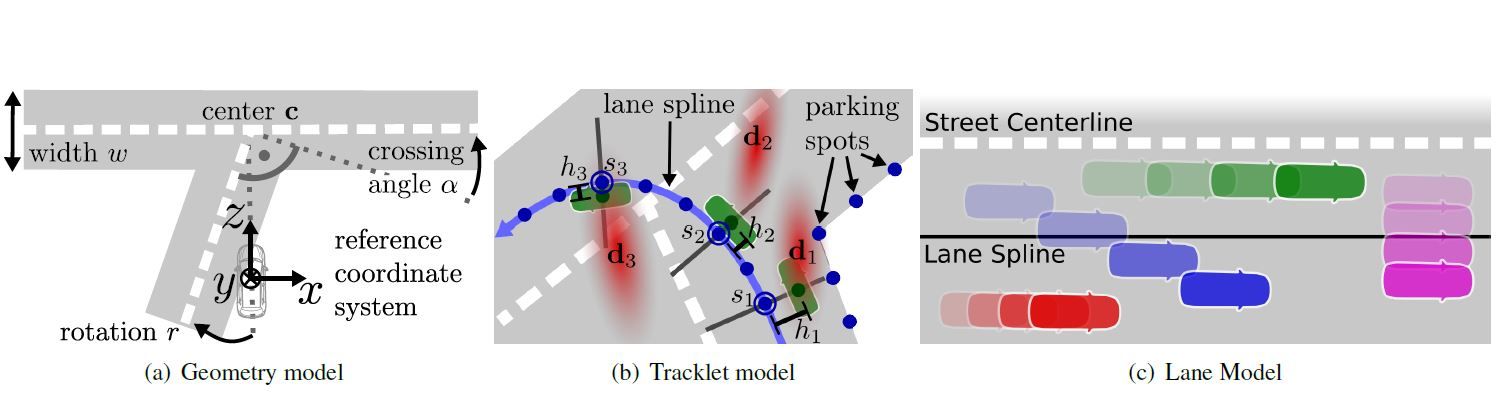
- Understanding the semantics of outdoor scenes in the context of autonomous driving
- Generative model of 3D urban scenes enables to reason about high level semantics in form of traffic patterns
- Learn the traffic patterns from real scenarios
- Novel object likelihood which models lanes much more accurately and improves the estimation of parameters such as the street orientations
- Small number of patterns is sufficient to model the vast majority of traffic scenes
- High-level reasoning significantly improves the overall scene estimation as well as the vehicle-to-lane association
| Scene Understanding Methods | |||
|
ICCV 2013
Zhang2013ICCV | |||
- Understanding the semantics of outdoor scenes in the context of autonomous driving
- Generative model of 3D urban scenes enables to reason about high level semantics in form of traffic patterns
- Learn the traffic patterns from real scenarios
- Novel object likelihood which models lanes much more accurately and improves the estimation of parameters such as the street orientations
- Small number of patterns is sufficient to model the vast majority of traffic scenes
- High-level reasoning significantly improves the overall scene estimation as well as the vehicle-to-lane association
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
ICRA 2015
Zhang2015ICRA | |||
- Combining visual and lidar odometry in a fundamental and first principle method
- Visual odometry to estimate the ego-motion and to register point clouds from a scanning lidar at a high frequency but low fidelity
- Scan matching based lidar odometry to refine the motion estimation and point cloud registration simultaneously
- Ranking first on the KITTI odometry benchmark
- Further experiments with a wide-angle camera and a fisheye camera
- Robust to aggressive motion and temporary lack of visual features
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
ICRA 2015
Zhang2015ICRA | |||
- Combining visual and lidar odometry in a fundamental and first principle method
- Visual odometry to estimate the ego-motion and to register point clouds from a scanning lidar at a high frequency but low fidelity
- Scan matching based lidar odometry to refine the motion estimation and point cloud registration simultaneously
- Ranking first on the KITTI odometry benchmark
- Further experiments with a wide-angle camera and a fisheye camera
- Robust to aggressive motion and temporary lack of visual features
| Mapping, Localization & Ego-Motion Estimation Ego-Motion Estimation | |||
|
RSS 2014
Zhang2014RSS | |||
- A real-time odometry and mapping method from a 2-axis lidar moving in 6-DOF
- Problems:
- Range measurements received at different times
- Mis-registration of the point cloud due to the errors in motion estimation
- Current approaches: 3D maps by offline batch methods, using loop closure for drift
- Both low-drift and low-computational complexity without the need for high accuracy ranging or inertial measurements
- Division of the complex problem of simultaneous localization and mapping:
- Odometry at a high frequency but low fidelity to estimate velocity of the lidar
- Fine matching and registration of the point cloud at a frequency of an order of magnitude lower
- Tested both indoor and outdoor, state-of-the art accuracy in real-time on KITTI odometry benchmark
| Mapping, Localization & Ego-Motion Estimation State of the Art on KITTI | |||
|
RSS 2014
Zhang2014RSS | |||
- A real-time odometry and mapping method from a 2-axis lidar moving in 6-DOF
- Problems:
- Range measurements received at different times
- Mis-registration of the point cloud due to the errors in motion estimation
- Current approaches: 3D maps by offline batch methods, using loop closure for drift
- Both low-drift and low-computational complexity without the need for high accuracy ranging or inertial measurements
- Division of the complex problem of simultaneous localization and mapping:
- Odometry at a high frequency but low fidelity to estimate velocity of the lidar
- Fine matching and registration of the point cloud at a frequency of an order of magnitude lower
- Tested both indoor and outdoor, state-of-the art accuracy in real-time on KITTI odometry benchmark
| Object Tracking Methods | |||
|
CVPR 2008
Zhang2008CVPR | |||

- Existing methods severely limit the search window and perform pruning of hypotheses
- Contributions:
- Presents a novel data association framework for multiple object tracking that optimizes the association globally using all the observations from the entire sequence
- False alarms, initialization and termination of the trajectory & inference of occlusions is modeled intrinsically in the method
- An optimal solution is provided based on the min-cost network flow algorithms
- Evaluates on the CAVIAR videos and the ETH Mobile Scene (ETHMS) datasets
| Object Tracking State of the Art on MOT & KITTI | |||
|
CVPR 2008
Zhang2008CVPR | |||
- Existing methods severely limit the search window and perform pruning of hypotheses
- Contributions:
- Presents a novel data association framework for multiple object tracking that optimizes the association globally using all the observations from the entire sequence
- False alarms, initialization and termination of the trajectory & inference of occlusions is modeled intrinsically in the method
- An optimal solution is provided based on the min-cost network flow algorithms
- Evaluates on the CAVIAR videos and the ETH Mobile Scene (ETHMS) datasets
| Semantic Instance Segmentation Methods | |||
|
CVPR 2016
Zhang2016CVPR | |||
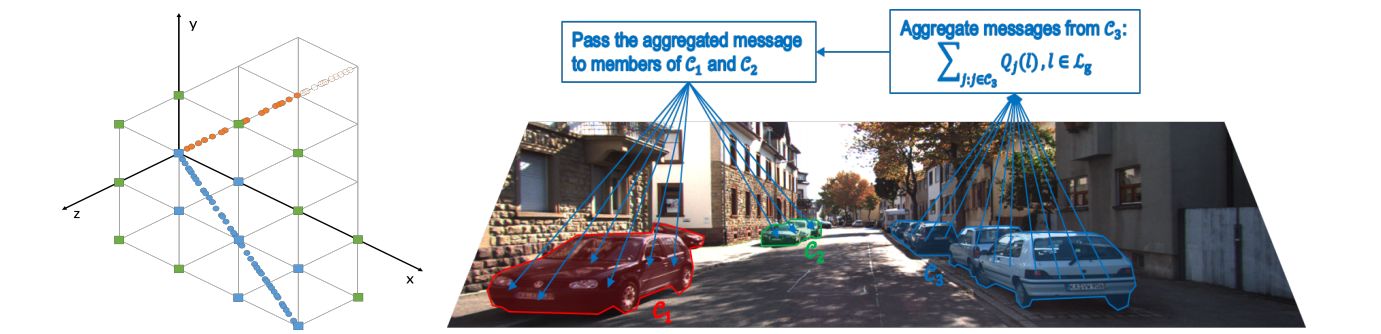
- The paper proposes a method to estimate an accurate pixel level labeling of object instances from a single monocular image in the context of autonomous driving.
- Propose a method that combines the soft predictions of a neural net run on many overlapping patches into a consistent global labeling of the entire image.
- Formulate the problem as a densely connected MRF with several potentials encoding consistency with local patches, contrast-sensitive smoothness as well as the fact that separate regions form different instances.
- The formulation encodes all potentials in a way that is amenable to efficient mean field inference including Potts potentials.
- Demonstrate performance on KITTI benchmark.
| Semantic Instance Segmentation Methods | |||
|
ICCV 2015
Zhang2015ICCV | |||
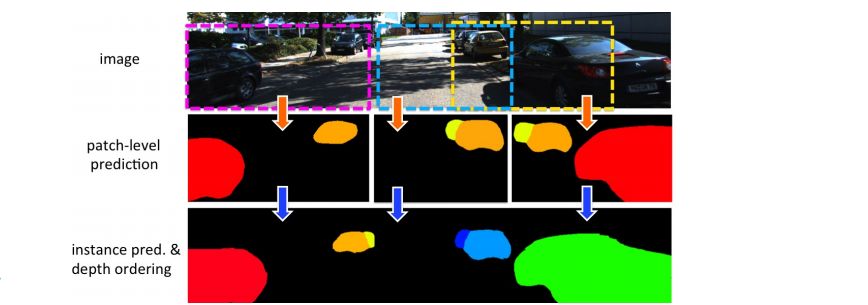
- The paper proposes to tackle the problem of instance-level segmentation and depth ordering from a single monocular image.
- They take advantage of convolutional neural nets and train them to directly predict instance-level segmentations where the instance ID encodes the depth ordering within image patches.
- To provide a coherent single explanation of an image we develop a Markov random field which takes as input the predictions of convolutional neural nets applied at overlapping patches of different resolutions, as well as the output of a connected component algorithm.
- Demonstrate performance on KITTI benchmark.
| Mapping, Localization & Ego-Motion Estimation Localization | |||
|
NIPS 2014
Zhou2014NIPS | |||

- Current deep features trained from ImageNet are not competitive enough for scene recognition.
- A new scene-centric database called Places
- Over 7 million labeled pictures from 476 place categories
- The details of building the database
- Comparison of scene-centric databases using novel density and diversity metrics
- Training a CNN to learn deep features for scene recognition
- A visualization of differences in the internal representations of object-centric and scene-centric networks
| Multi-view 3D Reconstruction Multi-view Stereo | |||
|
ICCV 2015
Zhou2015ICCV | |||
- Challenges: low frame rates, occlusions, large distortions, and difficult lighting conditions
- Learning volumetric shape models for objects of similar type such as vehicles, buildings to complete missing surfaces and improve the reconstruction
- Initial reconstruction by SfM and volumetric fusion using TSDF
- 3D object detection by exemplar SVMs on TSDF representation
- BCD for joint inference of different blocks:
- Optimization of object poses
- Assigning proposals to shape models
- Learning shape model parameters
- Improving compared to the initial reconstruction and PMVS2, especially in completeness
- A novel multi-view reconstruction dataset from fisheye cameras
| Object Detection Methods | |||
|
ACCV 2016
Zhu2016ACCV | |||
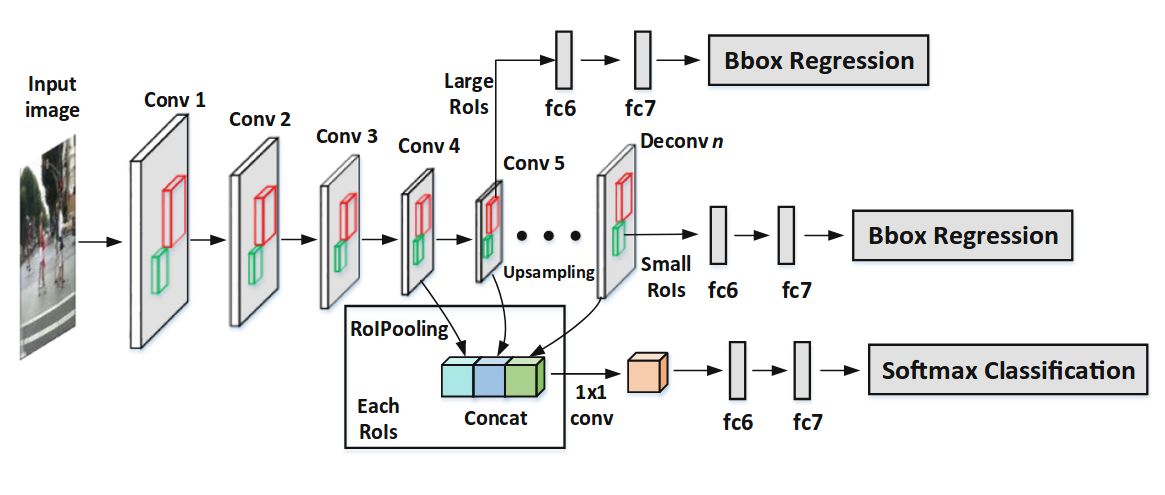
- R-CNN still face great challenges for task-specific detection, e.g. pedestrian detection
- Large variations of pedestrians and insufficient discriminative power of features
- Scale-Adaptive Deconvolutional Regression network effectively detects pedestrians
- Selects which feature layer to regress object location according to pedestrian height
- Fusion of features from multiple layers provide both local and global information
- Extensive experiments outperforming state-of-the-art on Calteach and KITTI
| Object Detection Methods | |||
|
PAMI 2013
Zia2013PAMI | |||
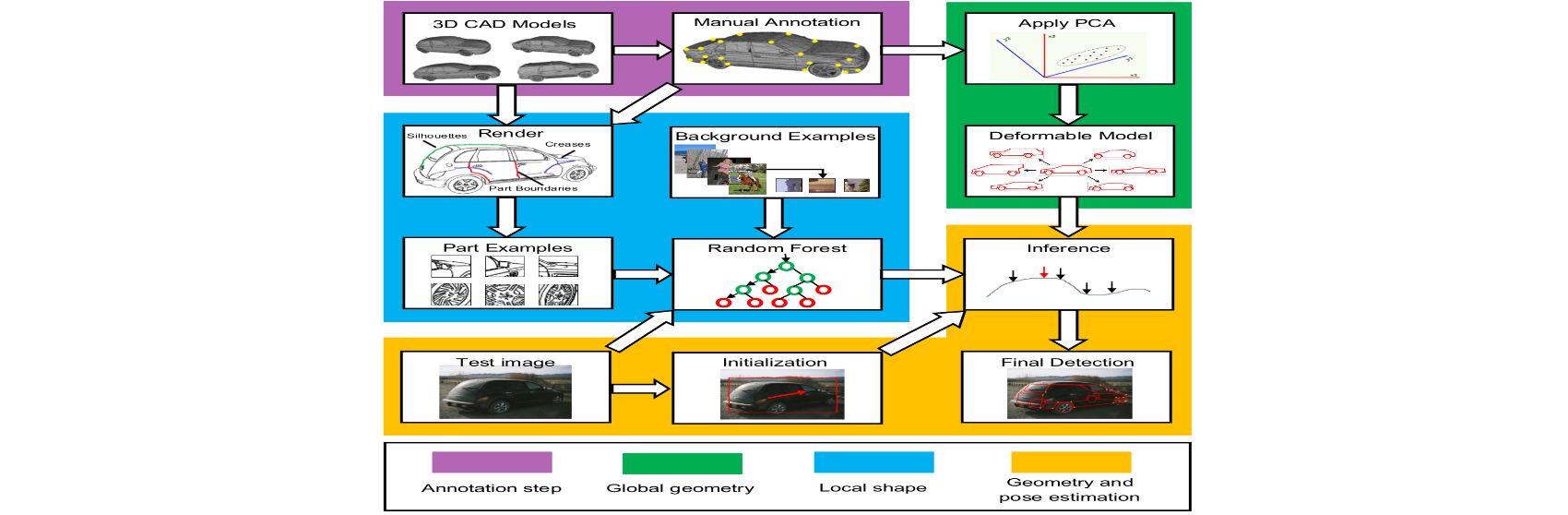
- Combines detailed models of 3D geometry with modern discriminative appearance models into a richer and more fine-grained object representation
- Method overview:
- Starts from a database of 3D computer aided design (CAD) models of the desired object class as training data
- Applies principal components analysis to obtain a coarse 3-dimensional wireframe model which captures the geometric intra-class variability
- Trains detectors for the vertices of the wireframe, which they call `parts'
- At test time, generates evidence for the parts by densely applying the part detectors to the image
- Explores the space of possible object geometries and poses by guided random sampling from the shape model, in order to identify the ones that best agree with the image evidence
- Evaluates on 3D Object Classes and EPFL Multi-view cars datasets
| Object Detection Methods | |||
|
IJCV 2015
Zia2015IJCV | |||
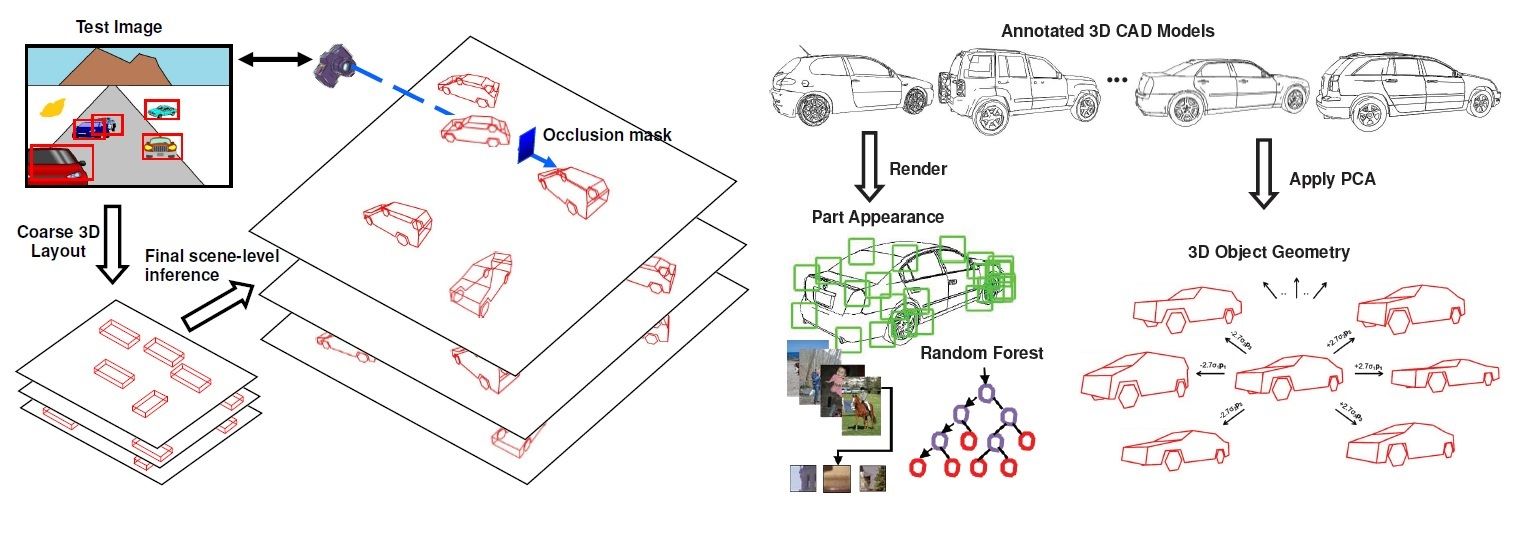
- Simple object representations such as bounding boxes used so far for semantic image and scene understanding
- Propose to base scene understanding on a high-resolution object representation
- Object class (cars) are modeled as a deformable 3D wireframe
- Viewpoint-invariant method for 3D reconstruction of severely occluded objects
- From single view joint estimation of the shapes and poses of multiple objects
- Reconstruct scenes in a single inference framework including geometric constraints between the objects
- Leverage rich detail of the 3D representation for occlusion reasoning at the individual vertex level
- Ground plane is estimated by consensus among different objects
- Systematic evaluation on KITTI dataset
| History of Autonomous Driving | |||
|
ITSM 2014
Ziegler2014ITSM | |||

- Gives an overview of the autonomous vehicle which completed the route from Mannheim to Pforzheim, Germany, in fully autonomous manner
- The autonomous vehicle was equipped with close-to-production sensor hardware in terms of cost and technical maturity than in many autonomous robots presented earlier
- Presents details on vision and radar-based perception, digital road maps and video-based self-localization, as well as motion planning in complex urban scenarios
- The key features of the system are:
- Radar and stereo vision sensing for object detection and free-space analysis
- Monocular vision for traffic light detection and object classification
- Digital road maps complemented with vision-based map-relative localization
- Versatile trajectory planning and reliable vehicle control
| Optical Flow Methods | |||
|
IJCV 2011
Zimmer2011IJCV | |||

- Most variational optic flow approaches consist of a data term and a smoothness term
- Present an approach that harmonises these two components
- Develop an advanced data term robust under outliers and varying illumination newline Using constraint illumination conditions and HSV color representation
- Anisotropic smoothness designed to work complementary to the data term newline Incorporates directional information from data constraints
- Spatial as well as spatio-temporal smoothness
- Simple method to automatically determine optimal smoothness weight
- Evaluation on Middlebury dataset
| 3D Scene Flow Methods | |||
|
Bounding Boxes, Segmentations and Object Coordinates: How Important is Recognition for 3D Scene Flow Estimation in Autonomous Driving Scenarios?[scholar]
|
ICCV 2017
Behl2017ICCV | ||
| 3D Scene Flow State of the Art on KITTI | |||
|
Bounding Boxes, Segmentations and Object Coordinates: How Important is Recognition for 3D Scene Flow Estimation in Autonomous Driving Scenarios?[scholar]
|
ICCV 2017
Behl2017ICCV | ||
| Optical Flow Methods | |||
|
Back to Basics: Unsupervised Learning of Optical Flow via Brightness Constancy and Motion Smoothness[scholar]
|
ECCV 2016
Yu2016ECCV | ||