https://gitlab.com/srrg-software/srrg_proslam Submitted on 20 Jan. 2019 22:24 by Dominik Schlegel (Sapienza)
|
Method
Detailed Results
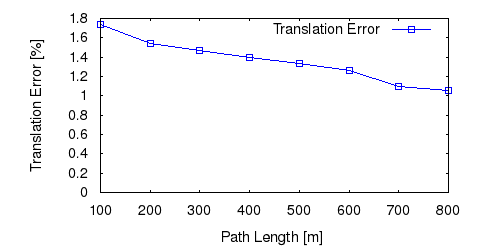
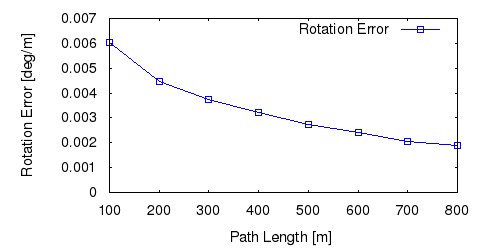
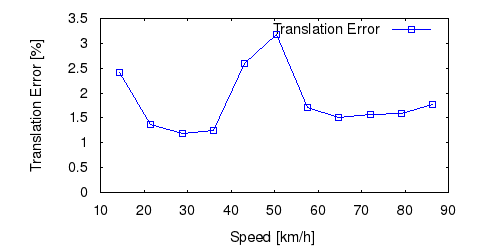
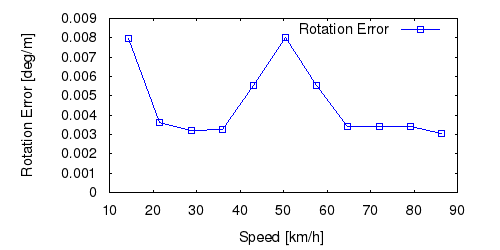
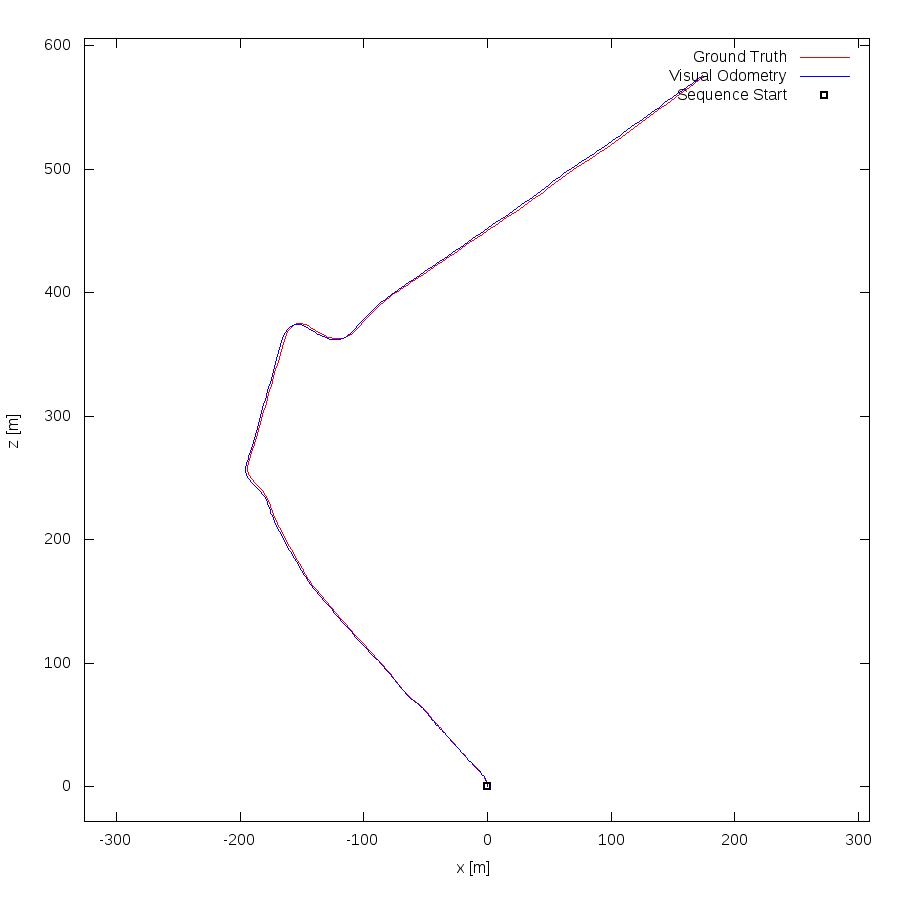
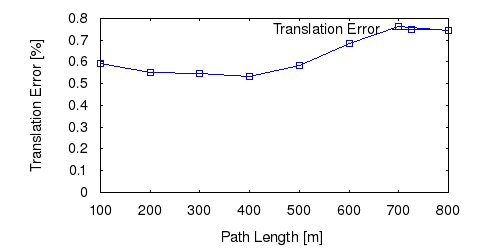
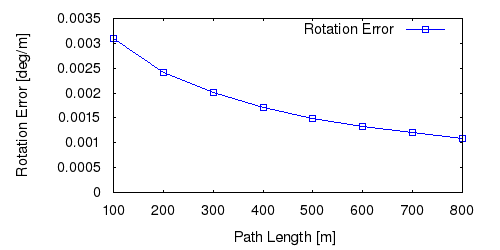
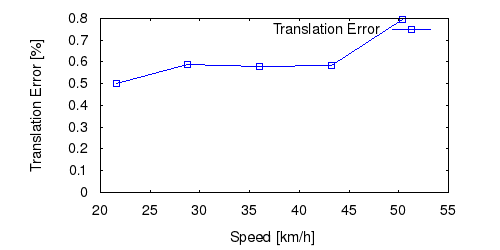
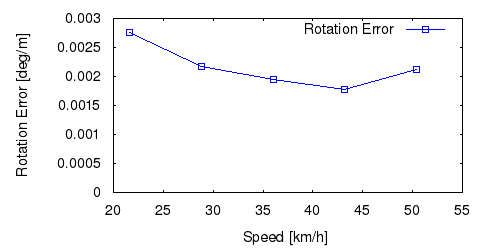
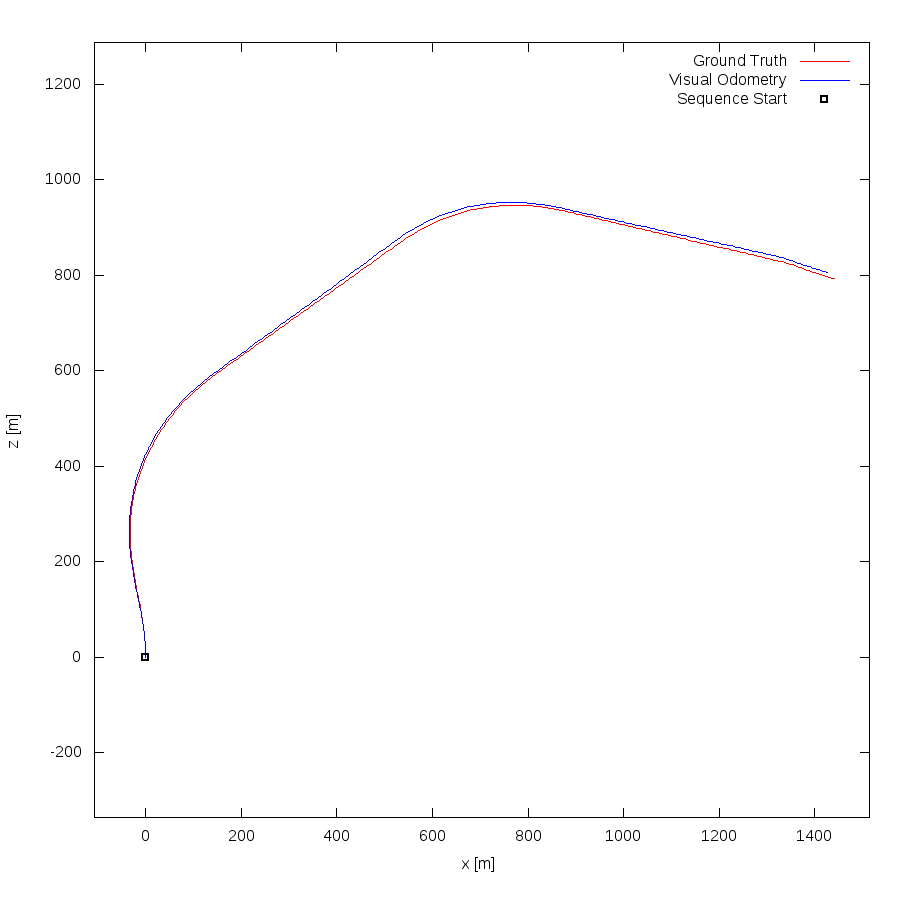
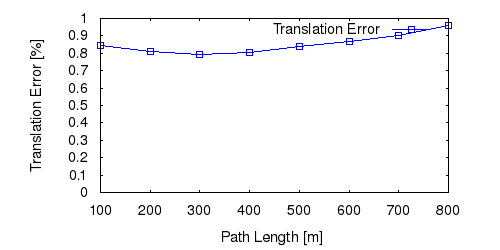
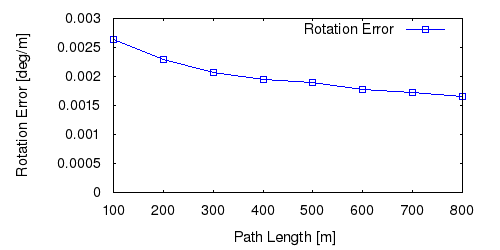
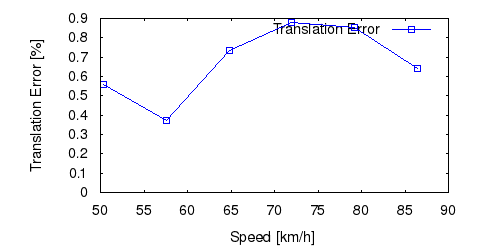
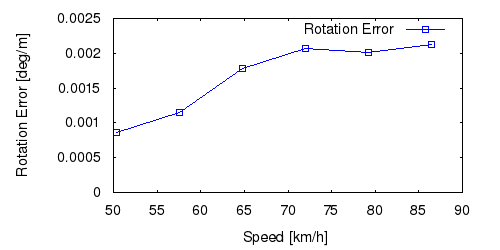
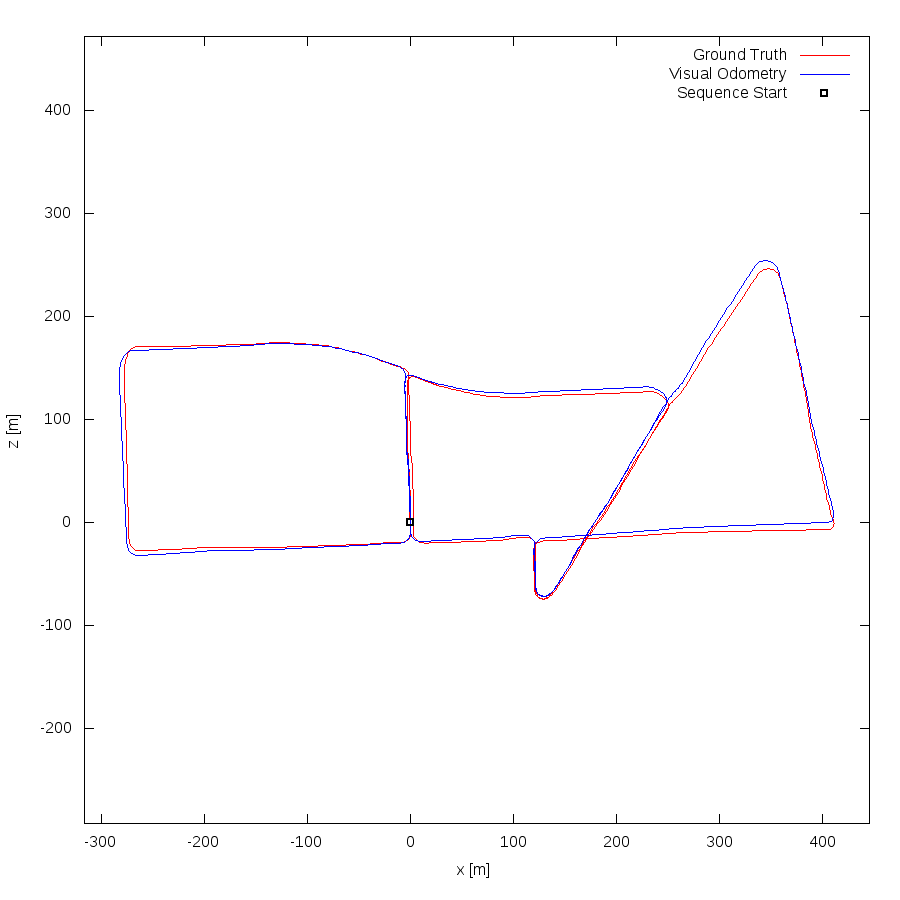
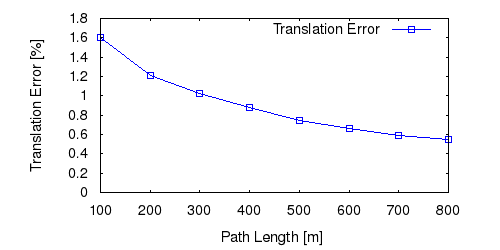
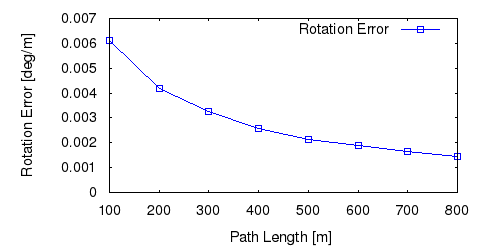
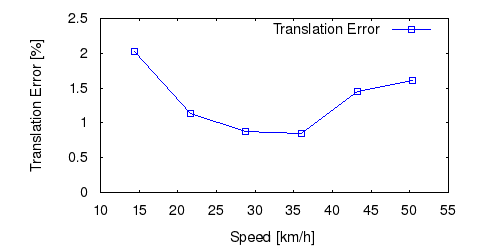
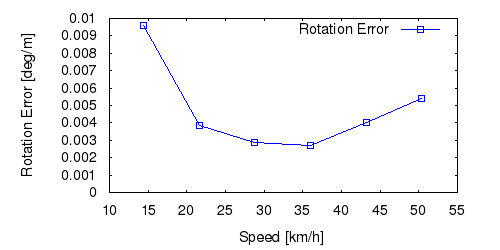
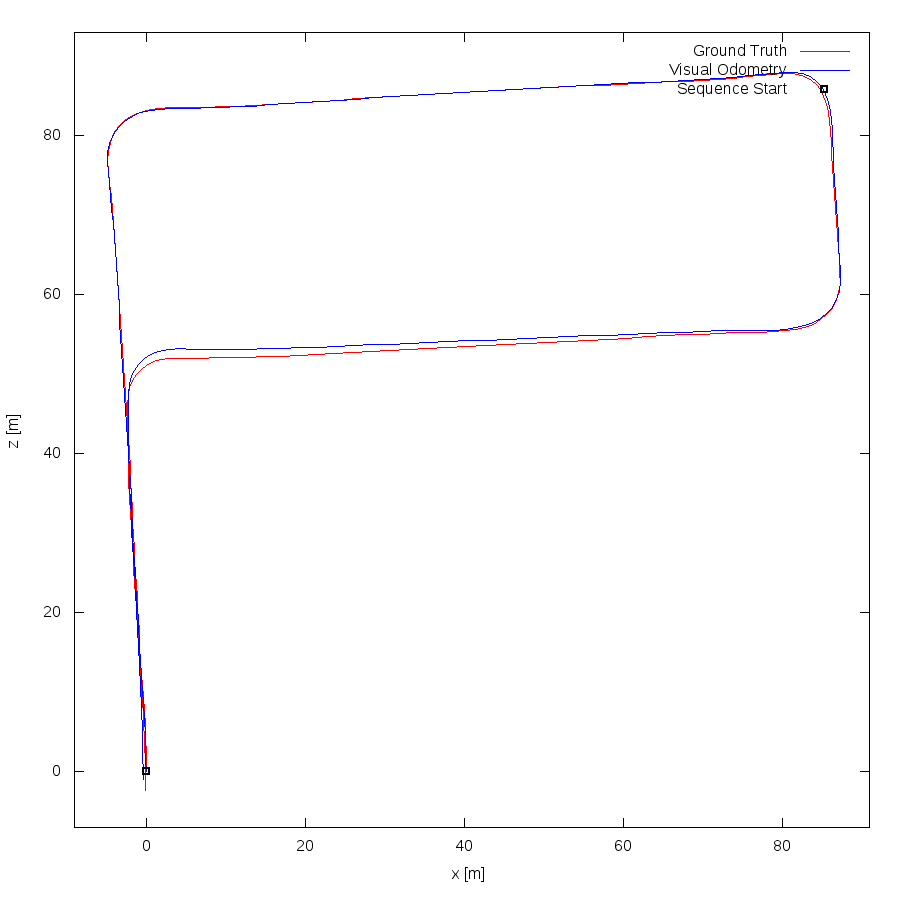
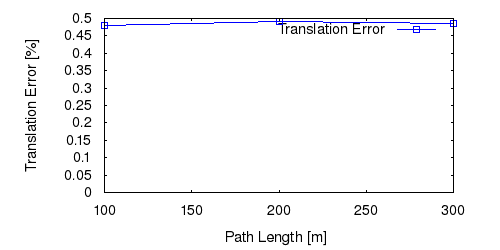
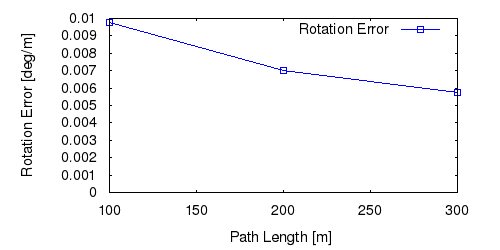
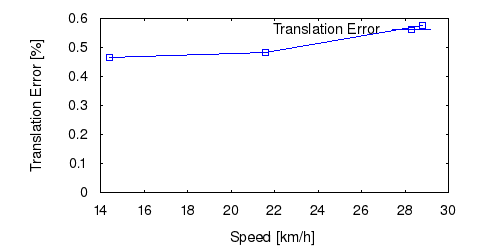
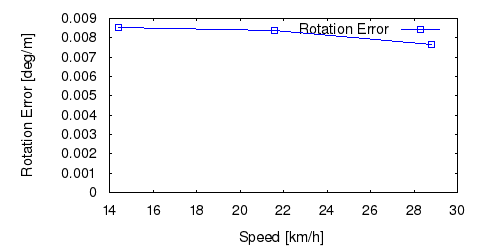
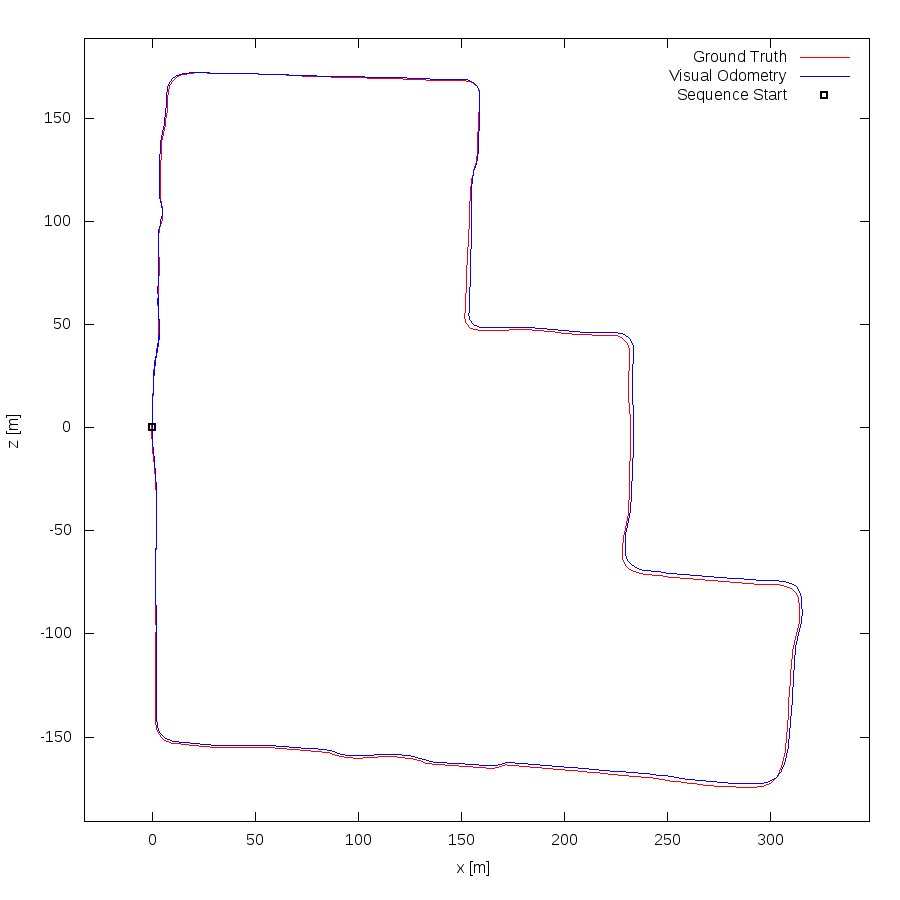
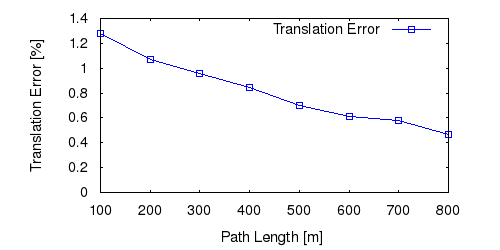
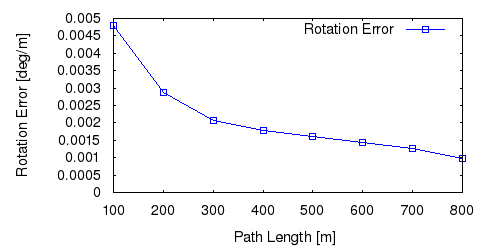
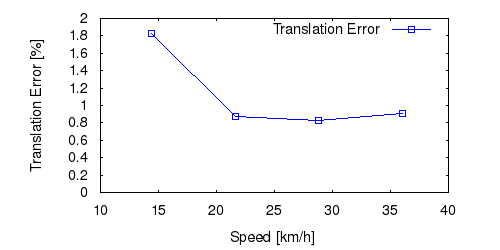
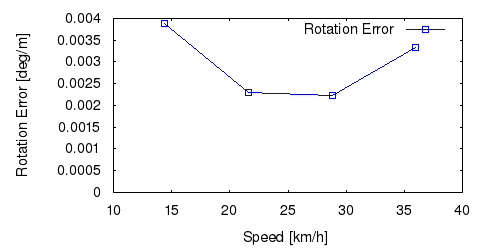
From all test sequences (sequences 11-21), our benchmark computes translational and rotational errors for all possible subsequences of length (5,10,50,100,150,...,400) meters. Our evaluation ranks methods according to the average of those values, where errors are measured in percent (for translation) and in degrees per meter (for rotation). Details for different trajectory lengths and driving speeds can be found in the plots underneath. Furthermore, the first 5 test trajectories and error plots are shown below.