Publications of Michael Niemeyer

VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel Grids
K. Schwarz, A. Sauer, M. Niemeyer, Y. Liao and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2022
K. Schwarz, A. Sauer, M. Niemeyer, Y. Liao and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2022
Abstract: State-of-the-art 3D-aware generative models rely on coordinate-based MLPs to parameterize 3D radiance fields. While demonstrating impressive results, querying an MLP for every sample along each ray leads to slow rendering. Therefore, existing approaches often render low-resolution feature maps and process them with an upsampling network to obtain the final image. Albeit efficient, neural rendering often entangles viewpoint and content such that changing the camera pose results in unwanted changes of geometry or appearance. Motivated by recent results in voxel-based novel view synthesis, we investigate the utility of sparse voxel grid representations for fast and 3D-consistent generative modeling in this paper. Our results demonstrate that monolithic MLPs can indeed be replaced by 3D convolutions when combining sparse voxel grids with progressive growing, free space pruning and appropriate regularization.
To obtain a compact representation of the scene and allow for scaling to higher voxel resolutions, our model disentangles the foreground object (modeled in 3D) from the background (modeled in 2D). In contrast to existing approaches, our method requires only a single forward pass to generate a full 3D scene. It hence allows for efficient rendering from arbitrary viewpoints while yielding 3D consistent results with high visual fidelity.
Latex Bibtex Citation:
@inproceedings{Schwarz2022NEURIPS,
author = {Katja Schwarz and Axel Sauer and Michael Niemeyer and Yiyi Liao and Andreas Geiger},
title = {VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel Grids},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Schwarz2022NEURIPS,
author = {Katja Schwarz and Axel Sauer and Michael Niemeyer and Yiyi Liao and Andreas Geiger},
title = {VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel Grids},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2022}
}

MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction
Z. Yu, S. Peng, M. Niemeyer, T. Sattler and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2022
Z. Yu, S. Peng, M. Niemeyer, T. Sattler and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2022
Abstract: In recent years, neural implicit surface reconstruction methods have become popular for multi-view 3D reconstruction. In contrast to traditional multi-view stereo methods, these approaches tend to produce smoother and more complete reconstructions due to the inductive smoothness bias of neural networks. State-of-the-art neural implicit methods allow for high-quality reconstructions of simple scenes from many input views. Yet, their performance drops significantly for larger and more complex scenes and scenes captured from sparse viewpoints. This is caused primarily by the inherent ambiguity in the RGB reconstruction loss that does not provide enough constraints, in particular in less-observed and textureless areas. Motivated by recent advances in the area of monocular geometry prediction, we systematically explore the utility these cues provide for improving neural implicit surface reconstruction. We demonstrate that depth and normal cues, predicted by general-purpose monocular estimators, significantly improve reconstruction quality and optimization time. Further, we analyse and investigate multiple design choices for representing neural implicit surfaces, ranging from monolithic MLP models over single-grid to multi-resolution grid representations. We observe that geometric monocular priors improve performance both for small-scale single-object as well as large-scale multi-object scenes, independent of the choice of representation.
Latex Bibtex Citation:
@inproceedings{Yu2022NEURIPS,
author = {Zehao Yu and Songyou Peng and Michael Niemeyer and Torsten Sattler and Andreas Geiger},
title = {MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Yu2022NEURIPS,
author = {Zehao Yu and Songyou Peng and Michael Niemeyer and Torsten Sattler and Andreas Geiger},
title = {MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2022}
}

RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs (oral)
M. Niemeyer, J. Barron, B. Mildenhall, M. Sajjadi, A. Geiger and N. Radwan
Conference on Computer Vision and Pattern Recognition (CVPR), 2022
M. Niemeyer, J. Barron, B. Mildenhall, M. Sajjadi, A. Geiger and N. Radwan
Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Abstract: Neural Radiance Fields (NeRF) have emerged as a powerful representation for the task of novel view synthesis due to their simplicity and state-of-the-art performance. Though NeRF can produce photorealistic renderings of unseen viewpoints when many input views are available, its performance drops significantly when this number is reduced. We observe that the majority of artifacts in sparse input scenarios are caused by errors in the estimated scene geometry, and by divergent behavior at the start of training. We address this by regularizing the geometry and appearance of patches rendered from unobserved viewpoints, and annealing the ray sampling space during training. We additionally use a normalizing flow model to regularize the color of unobserved viewpoints. Our model outperforms not only other methods that optimize over a single scene, but in many cases also conditional models that are extensively pre-trained on large multi-view datasets.
Latex Bibtex Citation:
@inproceedings{Niemeyer2022CVPR,
author = {Michael Niemeyer and Jonathan Barron and Ben Mildenhall and Mehdi S. M. Sajjadi and Andreas Geiger and Noha Radwan},
title = {RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}
Latex Bibtex Citation:
@inproceedings{Niemeyer2022CVPR,
author = {Michael Niemeyer and Jonathan Barron and Ben Mildenhall and Mehdi S. M. Sajjadi and Andreas Geiger and Noha Radwan},
title = {RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}

Shape As Points: A Differentiable Poisson Solver (oral)
S. Peng, C. Jiang, Y. Liao, M. Niemeyer, M. Pollefeys and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2021
S. Peng, C. Jiang, Y. Liao, M. Niemeyer, M. Pollefeys and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2021
Abstract: In recent years, neural implicit representations gained popularity in 3D reconstruction due to their expressiveness and flexibility. However, the implicit nature of neural implicit representations results in slow inference times and requires careful initialization. In this paper, we revisit the classic yet ubiquitous point cloud representation and introduce a differentiable point-to-mesh layer using a differentiable formulation of Poisson Surface Reconstruction (PSR) which allows for a GPU-accelerated fast solution of the indicator function given an oriented point cloud. The differentiable PSR layer allows us to efficiently and differentiably bridge the explicit 3D point representation with the 3D mesh via the implicit indicator field, enabling end-to-end optimization of surface reconstruction metrics such as Chamfer distance. This duality between points and meshes hence allows us to represent shapes as oriented point clouds, which are explicit, lightweight and expressive. Compared to neural implicit representations, our Shape-As-Points (SAP) model is more interpretable, lightweight, and accelerates inference time by one order of magnitude. Compared to other explicit representations such as points, patches, and meshes, SAP produces topology-agnostic, watertight manifold surfaces. We demonstrate the effectiveness of SAP on the task of surface reconstruction from unoriented point clouds and learning-based reconstruction.
Latex Bibtex Citation:
@inproceedings{Peng2021NEURIPS,
author = {Songyou Peng and Chiyu Max Jiang and Yiyi Liao and Michael Niemeyer and Marc Pollefeys and Andreas Geiger},
title = {Shape As Points: A Differentiable Poisson Solver},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Peng2021NEURIPS,
author = {Songyou Peng and Chiyu Max Jiang and Yiyi Liao and Michael Niemeyer and Marc Pollefeys and Andreas Geiger},
title = {Shape As Points: A Differentiable Poisson Solver},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}

CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields
M. Niemeyer and A. Geiger
International Conference on 3D Vision (3DV), 2021
M. Niemeyer and A. Geiger
International Conference on 3D Vision (3DV), 2021
Abstract: Tremendous progress in deep generative models has led to photorealistic image synthesis. While achieving compelling results, most approaches operate in the two-dimensional image domain, ignoring the three-dimensional nature of our world. Several recent works therefore propose generative models which are 3D-aware, ie, scenes are modeled in 3D and then rendered differentiably to the image plane. While this leads to impressive 3D~consistency, the camera needs to be modelled as well and we show in this work that these methods are sensitive to the choice of prior camera distributions. Current approaches assume fixed intrinsics and predefined priors over camera pose ranges, and parameter tuning is typically required for real-world data. If the data distribution is not matched, results degrade significantly. Our key hypothesis is that learning a camera generator jointly with the image generator leads to a more principled approach to 3D-aware image synthesis. Further, we propose to decompose the scene into a background and foreground model, leading to more efficient and disentangled scene representations. While training from raw, unposed image collections, we learn a 3D- and camera-aware generative model which faithfully recovers not only the image but also the camera data distribution. At test time, our model generates images with explicit control over the camera as well as the shape and appearance of the scene.
Latex Bibtex Citation:
@inproceedings{Niemeyer2021THREEDV,
author = {Michael Niemeyer and Andreas Geiger},
title = {CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Niemeyer2021THREEDV,
author = {Michael Niemeyer and Andreas Geiger},
title = {CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2021}
}

GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields (oral, best paper award)
M. Niemeyer and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
M. Niemeyer and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Abstract: Deep generative models allow for photorealistic image synthesis at high resolutions. But for many applications, this is not enough: content creation also needs to be controllable. While several recent works investigate how to disentangle underlying factors of variation in the data, most of them operate in 2D and hence ignore that our world is three-dimensional. Further, only few works consider the compositional nature of scenes. Our key hypothesis is that incorporating a compositional 3D scene representation into the generative model leads to more controllable image synthesis. Representing scenes as compositional generative neural feature fields allows us to disentangle one or multiple objects from the background as well as individual objects' shapes and appearances while learning from unstructured and unposed image collections without any additional supervision. Combining this scene representation with a neural rendering pipeline yields a fast and realistic image synthesis model. As evidenced by our experiments, our model is able to disentangle individual objects and allows for translating and rotating them in the scene as well as changing the camera pose.
Latex Bibtex Citation:
@inproceedings{Niemeyer2021CVPR,
author = {Michael Niemeyer and Andreas Geiger},
title = {GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Niemeyer2021CVPR,
author = {Michael Niemeyer and Andreas Geiger},
title = {GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}

GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis
K. Schwarz, Y. Liao, M. Niemeyer and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2020
K. Schwarz, Y. Liao, M. Niemeyer and A. Geiger
Advances in Neural Information Processing Systems (NeurIPS), 2020
Abstract: While 2D generative adversarial networks have enabled high-resolution image synthesis, they largely lack an understanding of the 3D world and the image formation process. Thus, they do not provide precise control over camera viewpoint or object pose. To address this problem, several recent approaches leverage intermediate voxel-based representations in combination with differentiable rendering. However, existing methods either produce low image resolution or fall short in disentangling camera and scene properties, eg, the object identity may vary with the viewpoint. In this paper, we propose a generative model for radiance fields which have recently proven successful for novel view synthesis of a single scene. In contrast to voxel-based representations, radiance fields are not confined to a coarse discretization of the 3D space, yet allow for disentangling camera and scene properties while degrading gracefully in the presence of reconstruction ambiguity. By introducing a multi-scale patch-based discriminator, we demonstrate synthesis of high-resolution images while training our model from unposed 2D images alone. We systematically analyze our approach on several challenging synthetic and real-world datasets. Our experiments reveal that radiance fields are a powerful representation for generative image synthesis, leading to 3D consistent models that render with high fidelity.
Latex Bibtex Citation:
@inproceedings{Schwarz2020NEURIPS,
author = {Katja Schwarz and Yiyi Liao and Michael Niemeyer and Andreas Geiger},
title = {GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Schwarz2020NEURIPS,
author = {Katja Schwarz and Yiyi Liao and Michael Niemeyer and Andreas Geiger},
title = {GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2020}
}

Learning Implicit Surface Light Fields
M. Oechsle, M. Niemeyer, C. Reiser, L. Mescheder, T. Strauss and A. Geiger
International Conference on 3D Vision (3DV), 2020
M. Oechsle, M. Niemeyer, C. Reiser, L. Mescheder, T. Strauss and A. Geiger
International Conference on 3D Vision (3DV), 2020
Abstract: Implicit representations of 3D objects have recently achieved impressive results on learning-based 3D reconstruction tasks. While existing works use simple texture models to represent object appearance, photo-realistic image synthesis requires reasoning about the complex interplay of light, geometry and surface properties. In this work, we propose a novel implicit representation for capturing the visual appearance of an object in terms of its surface light field. In contrast to existing representations, our implicit model represents surface light fields in a continuous fashion and independent of the geometry. Moreover, we condition the surface light field with respect to the location and color of a small light source. Compared to traditional surface light field models, this allows us to manipulate the light source and relight the object using environment maps. We further demonstrate the capabilities of our model to predict the visual appearance of an unseen object from a single real RGB image and corresponding 3D shape information. As evidenced by our experiments, our model is able to infer rich visual appearance including shadows and specular reflections. Finally, we show that the proposed representation can be embedded into a variational auto-encoder for generating novel appearances that conform to the specified illumination conditions.
Latex Bibtex Citation:
@inproceedings{Oechsle2020THREEDV,
author = {Michael Oechsle and Michael Niemeyer and Christian Reiser and Lars Mescheder and Thilo Strauss and Andreas Geiger},
title = {Learning Implicit Surface Light Fields},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Oechsle2020THREEDV,
author = {Michael Oechsle and Michael Niemeyer and Christian Reiser and Lars Mescheder and Thilo Strauss and Andreas Geiger},
title = {Learning Implicit Surface Light Fields},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2020}
}

Convolutional Occupancy Networks (spotlight)
S. Peng, M. Niemeyer, L. Mescheder, M. Pollefeys and A. Geiger
European Conference on Computer Vision (ECCV), 2020
S. Peng, M. Niemeyer, L. Mescheder, M. Pollefeys and A. Geiger
European Conference on Computer Vision (ECCV), 2020
Abstract: Recently, implicit neural representations have gained popularity for learning-based 3D reconstruction. While demonstrating promising results, most implicit approaches are limited to comparably simple geometry of single objects and do not scale to more complicated or large-scale scenes. The key limiting factor of implicit methods is their simple fully-connected network architecture which does not allow for integrating local information in the observations or incorporating inductive biases such as translational equivariance. In this paper, we propose Convolutional Occupancy Networks, a more flexible implicit representation for detailed reconstruction of objects and 3D scenes. By combining convolutional encoders with implicit occupancy decoders, our model incorporates inductive biases, enabling structured reasoning in 3D space. We investigate the effectiveness of the proposed representation by reconstructing complex geometry from noisy point clouds and low-resolution voxel representations. We empirically find that our method enables the fine-grained implicit 3D reconstruction of single objects, scales to large indoor scenes, and generalizes well from synthetic to real data.
Latex Bibtex Citation:
@inproceedings{Peng2020ECCV,
author = {Songyou Peng and Michael Niemeyer and Lars Mescheder and Marc Pollefeys and Andreas Geiger},
title = {Convolutional Occupancy Networks},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Peng2020ECCV,
author = {Songyou Peng and Michael Niemeyer and Lars Mescheder and Marc Pollefeys and Andreas Geiger},
title = {Convolutional Occupancy Networks},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}

Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision
M. Niemeyer, L. Mescheder, M. Oechsle and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
M. Niemeyer, L. Mescheder, M. Oechsle and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Abstract: Learning-based 3D reconstruction methods have shown impressive results. However, most methods require 3D supervision which is often hard to obtain for real-world datasets. Recently, several works have proposed differentiable rendering techniques to train reconstruction models from RGB images. Unfortunately, these approaches are currently restricted to voxel- and mesh-based representations, suffering from discretization or low resolution. In this work, we propose a differentiable rendering formulation for implicit shape and texture representations. Implicit representations have recently gained popularity as they represent shape and texture continuously. Our key insight is that depth gradients can be derived analytically using the concept of implicit differentiation. This allows us to learn implicit shape and texture representations directly from RGB images. We experimentally show that our single-view reconstructions rival those learned with full 3D supervision. Moreover, we find that our method can be used for multi-view 3D reconstruction, directly resulting in watertight meshes.
Latex Bibtex Citation:
@inproceedings{Niemeyer2020CVPR,
author = {Michael Niemeyer and Lars Mescheder and Michael Oechsle and Andreas Geiger},
title = {Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Niemeyer2020CVPR,
author = {Michael Niemeyer and Lars Mescheder and Michael Oechsle and Andreas Geiger},
title = {Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
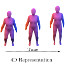
Occupancy Flow: 4D Reconstruction by Learning Particle Dynamics
M. Niemeyer, L. Mescheder, M. Oechsle and A. Geiger
International Conference on Computer Vision (ICCV), 2019
M. Niemeyer, L. Mescheder, M. Oechsle and A. Geiger
International Conference on Computer Vision (ICCV), 2019
Abstract: Deep learning based 3D reconstruction techniques have recently achieved impressive results. However, while state-of-the-art methods are able to output complex 3D geometry, it is not clear how to extend these results to time-varying topologies. Approaches treating each time step individually lack continuity and exhibit slow inference, while traditional 4D reconstruction methods often utilize a template model or discretize the 4D space at fixed resolution. In this work, we present Occupancy Flow, a novel spatio-temporal representation of time-varying 3D geometry with implicit correspondences. Towards this goal, we learn a temporally and spatially continuous vector field which assigns a motion vector to every point in space and time. In order to perform dense 4D reconstruction from images or sparse point clouds, we combine our method with a continuous 3D representation. Implicitly, our model yields correspondences over time, thus enabling fast inference while providing a sound physical description of the temporal dynamics. We show that our method can be used for interpolation and reconstruction tasks, and demonstrate the accuracy of the learned correspondences. We believe that Occupancy Flow is a promising new 4D representation which will be useful for a variety of spatio-temporal reconstruction tasks.
Latex Bibtex Citation:
@inproceedings{Niemeyer2019ICCV,
author = {Michael Niemeyer and Lars Mescheder and Michael Oechsle and Andreas Geiger},
title = {Occupancy Flow: 4D Reconstruction by Learning Particle Dynamics},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Niemeyer2019ICCV,
author = {Michael Niemeyer and Lars Mescheder and Michael Oechsle and Andreas Geiger},
title = {Occupancy Flow: 4D Reconstruction by Learning Particle Dynamics},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}

Texture Fields: Learning Texture Representations in Function Space (oral)
M. Oechsle, L. Mescheder, M. Niemeyer, T. Strauss and A. Geiger
International Conference on Computer Vision (ICCV), 2019
M. Oechsle, L. Mescheder, M. Niemeyer, T. Strauss and A. Geiger
International Conference on Computer Vision (ICCV), 2019
Abstract: In recent years, substantial progress has been achieved in learning-based reconstruction of 3D objects. At the same time, generative models were proposed that can generate highly realistic images. However, despite this success in these closely related tasks, texture reconstruction of 3D objects has received little attention from the research community and state-of-the-art methods are either limited to comparably low resolution or constrained experimental setups. A major reason for these limitations is that common representations of texture are inefficient or hard to interface for modern deep learning techniques. In this paper, we propose Texture Fields, a novel texture representation which is based on regressing a continuous 3D function parameterized with a neural network. Our approach circumvents limiting factors like shape discretization and parameterization, as the proposed texture representation is independent of the shape representation of the 3D object. We show that Texture Fields are able to represent high frequency texture and naturally blend with modern deep learning techniques. Experimentally, we find that Texture Fields compare favorably to state-of-the-art methods for conditional texture reconstruction of 3D objects and enable learning of probabilistic generative models for texturing unseen 3D models. We believe that Texture Fields will become an important building block for the next generation of generative 3D models.
Latex Bibtex Citation:
@inproceedings{Oechsle2019ICCV,
author = {Michael Oechsle and Lars Mescheder and Michael Niemeyer and Thilo Strauss and Andreas Geiger},
title = {Texture Fields: Learning Texture Representations in Function Space},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Oechsle2019ICCV,
author = {Michael Oechsle and Lars Mescheder and Michael Niemeyer and Thilo Strauss and Andreas Geiger},
title = {Texture Fields: Learning Texture Representations in Function Space},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2019}
}
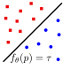
Occupancy Networks: Learning 3D Reconstruction in Function Space (oral, best paper finalist)
L. Mescheder, M. Oechsle, M. Niemeyer, S. Nowozin and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
L. Mescheder, M. Oechsle, M. Niemeyer, S. Nowozin and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Abstract: With the advent of deep neural networks, learning-based approaches for 3D~reconstruction have gained popularity. However, unlike for images, in 3D there is no canonical representation which is both computationally and memory efficient yet allows for representing high-resolution geometry of arbitrary topology. Many of the state-of-the-art learning-based 3D~reconstruction approaches can hence only represent very coarse 3D geometry or are limited to a restricted domain. In this paper, we propose Occupancy Networks, a new representation for learning-based 3D~reconstruction methods. Occupancy networks implicitly represent the 3D surface as the continuous decision boundary of a deep neural network classifier. In contrast to existing approaches, our representation encodes a description of the 3D output at infinite resolution without excessive memory footprint. We validate that our representation can efficiently encode 3D structure and can be inferred from various kinds of input. Our experiments demonstrate competitive results, both qualitatively and quantitatively, for the challenging tasks of 3D reconstruction from single images, noisy point clouds and coarse discrete voxel grids. We believe that occupancy networks will become a useful tool in a wide variety of learning-based 3D tasks.
Latex Bibtex Citation:
@inproceedings{Mescheder2019CVPR,
author = {Lars Mescheder and Michael Oechsle and Michael Niemeyer and Sebastian Nowozin and Andreas Geiger},
title = {Occupancy Networks: Learning 3D Reconstruction in Function Space},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
Latex Bibtex Citation:
@inproceedings{Mescheder2019CVPR,
author = {Lars Mescheder and Michael Oechsle and Michael Niemeyer and Sebastian Nowozin and Andreas Geiger},
title = {Occupancy Networks: Learning 3D Reconstruction in Function Space},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}