Publications of Aditya Prakash
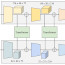
TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz and A. Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz and A. Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
Abstract: How should we integrate representations from complementary sensors for autonomous driving? Geometry-based fusion has shown promise for perception (e.g. object detection, motion forecasting). However, in the context of end-to-end driving, we find that imitation learning based on existing sensor fusion methods underperforms in complex driving scenarios with a high density of dynamic agents. Therefore, we propose TransFuser, a mechanism to integrate image and LiDAR representations using self-attention. Our approach uses transformer modules at multiple resolutions to fuse perspective view and bird's eye view feature maps. We experimentally validate its efficacy on a challenging new benchmark with long routes and dense traffic, as well as the official leaderboard of the CARLA urban driving simulator. At the time of submission, TransFuser outperforms all prior work on the CARLA leaderboard in terms of driving score by a large margin. Compared to geometry-based fusion, TransFuser reduces the average collisions per kilometer by 48%.
Latex Bibtex Citation:
@article{Chitta2022PAMI,
author = {Kashyap Chitta and Aditya Prakash and Bernhard Jaeger and Zehao Yu and Katrin Renz and Andreas Geiger},
title = {TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023}
}
Latex Bibtex Citation:
@article{Chitta2022PAMI,
author = {Kashyap Chitta and Aditya Prakash and Bernhard Jaeger and Zehao Yu and Katrin Renz and Andreas Geiger},
title = {TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2023}
}

NEAT: Neural Attention Fields for End-to-End Autonomous Driving
K. Chitta, A. Prakash and A. Geiger
International Conference on Computer Vision (ICCV), 2021
K. Chitta, A. Prakash and A. Geiger
International Conference on Computer Vision (ICCV), 2021
Abstract: Efficient reasoning about the semantic, spatial, and temporal structure of a scene is a crucial pre-requisite for autonomous driving. We present NEural ATtention fields (NEAT), a novel representation that enables such reasoning for end-to-end Imitation Learning (IL) models. Our representation is a continuous function which maps locations in Bird's Eye View (BEV) scene coordinates to waypoints and semantics, using intermediate attention maps to iteratively compress high-dimensional 2D image features into a compact representation. This allows our model to selectively attend to relevant regions in the input while ignoring information irrelevant to the driving task, effectively associating the images with the BEV representation. NEAT nearly matches the state-of-the-art on the CARLA Leaderboard while being far less resource-intensive. Furthermore, visualizing the attention maps for models with NEAT intermediate representations provides improved interpretability. On a new evaluation setting involving adverse environmental conditions and challenging scenarios, NEAT outperforms several strong baselines and achieves driving scores on par with the privileged CARLA expert used to generate its training data.
Latex Bibtex Citation:
@inproceedings{Chitta2021ICCV,
author = {Kashyap Chitta and Aditya Prakash and Andreas Geiger},
title = {NEAT: Neural Attention Fields for End-to-End Autonomous Driving},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Chitta2021ICCV,
author = {Kashyap Chitta and Aditya Prakash and Andreas Geiger},
title = {NEAT: Neural Attention Fields for End-to-End Autonomous Driving},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}

Multi-Modal Fusion Transformer for End-to-End Autonomous Driving
A. Prakash, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
A. Prakash, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Abstract: How should representations from complementary sensors be integrated for autonomous driving? Geometry-based sensor fusion has shown great promise for perception tasks such as object detection and motion forecasting. However, for the actual driving task, the global context of the 3D scene is key, e.g. a change in traffic light state can affect the behavior of a vehicle geometrically distant from that traffic light. Geometry alone may therefore be insufficient for effectively fusing representations in end-to-end driving models. In this work, we demonstrate that existing sensor fusion methods under-perform in the presence of a high density of dynamic agents and complex scenarios, which require global contextual reasoning, such as handling traffic oncoming from multiple directions at uncontrolled intersections. Therefore, we propose TransFuser, a novel Multi-Modal Fusion Transformer, to integrate image and LiDAR representations using attention. We experimentally validate the efficacy of our approach in urban settings involving complex scenarios using the CARLA urban driving simulator. Our approach achieves state-of-the-art driving performance while reducing collisions by 80% compared to geometry-based fusion.
Latex Bibtex Citation:
@inproceedings{Prakash2021CVPR,
author = {Aditya Prakash and Kashyap Chitta and Andreas Geiger},
title = {Multi-Modal Fusion Transformer for End-to-End Autonomous Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}
Latex Bibtex Citation:
@inproceedings{Prakash2021CVPR,
author = {Aditya Prakash and Kashyap Chitta and Andreas Geiger},
title = {Multi-Modal Fusion Transformer for End-to-End Autonomous Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}

Label Efficient Visual Abstractions for Autonomous Driving
A. Behl, K. Chitta, A. Prakash, E. Ohn-Bar and A. Geiger
International Conference on Intelligent Robots and Systems (IROS), 2020
A. Behl, K. Chitta, A. Prakash, E. Ohn-Bar and A. Geiger
International Conference on Intelligent Robots and Systems (IROS), 2020
Abstract: It is well known that semantic segmentation can be used as an effective intermediate representation for learning driving policies. However, the task of street scene semantic segmentation requires expensive annotations. Furthermore, segmentation algorithms are often trained irrespective of the actual driving task, using auxiliary image-space loss functions which are not guaranteed to maximize driving metrics such as safety or distance traveled per intervention. In this work, we seek to quantify the impact of reducing segmentation annotation costs on learned behavior cloning agents. We analyze several segmentation-based intermediate representations. We use these visual abstractions to systematically study the trade-off between annotation efficiency and driving performance, ie, the types of classes labeled, the number of image samples used to learn the visual abstraction model, and their granularity (eg, object masks vs. 2D bounding boxes). Our analysis uncovers several practical insights into how segmentation-based visual abstractions can be exploited in a more label efficient manner. Surprisingly, we find that state-of-the-art driving performance can be achieved with orders of magnitude reduction in annotation cost. Beyond label efficiency, we find several additional training benefits when leveraging visual abstractions, such as a significant reduction in the variance of the learned policy when compared to state-of-the-art end-to-end driving models.
Latex Bibtex Citation:
@inproceedings{Behl2020IROS,
author = {Aseem Behl and Kashyap Chitta and Aditya Prakash and Eshed Ohn-Bar and Andreas Geiger},
title = {Label Efficient Visual Abstractions for Autonomous Driving},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Behl2020IROS,
author = {Aseem Behl and Kashyap Chitta and Aditya Prakash and Eshed Ohn-Bar and Andreas Geiger},
title = {Label Efficient Visual Abstractions for Autonomous Driving},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2020}
}
Learning Situational Driving
E. Ohn-Bar, A. Prakash, A. Behl, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
E. Ohn-Bar, A. Prakash, A. Behl, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Abstract: Human drivers have a remarkable ability to drive in diverse visual conditions and situations, e.g., from maneuvering in rainy, limited visibility conditions with no lane markings to turning in a busy intersection while yielding to pedestrians. In contrast, we find that state-of-the-art sensorimotor driving models struggle when encountering diverse settings with varying relationships between observation and action. To generalize when making decisions across diverse conditions, humans leverage multiple types of situation-specific reasoning and learning strategies. Motivated by this observation, we develop a framework for learning a situational driving policy that effectively captures reasoning under varying types of scenarios. Our key idea is to learn a mixture model with a set of policies that can capture multiple driving modes. We first optimize the mixture model through behavior cloning, and show it to result in significant gains in terms of driving performance in diverse conditions. We then refine the model by directly optimizing for the driving task itself, i.e., supervised with the navigation task reward. Our method is more scalable than methods assuming access to privileged information, e.g., perception labels, as it only assumes demonstration and reward-based supervision. We achieve over 98% success rate on the CARLA driving benchmark as well as state-of-the-art performance on a newly introduced generalization benchmark.
Latex Bibtex Citation:
@inproceedings{Ohn-Bar2020CVPR,
author = {Eshed Ohn-Bar and Aditya Prakash and Aseem Behl and Kashyap Chitta and Andreas Geiger},
title = {Learning Situational Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Ohn-Bar2020CVPR,
author = {Eshed Ohn-Bar and Aditya Prakash and Aseem Behl and Kashyap Chitta and Andreas Geiger},
title = {Learning Situational Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}

Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving
A. Prakash, A. Behl, E. Ohn-Bar, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
A. Prakash, A. Behl, E. Ohn-Bar, K. Chitta and A. Geiger
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Abstract: Data aggregation techniques can significantly improve vision-based policy learning within a training environment, e.g., learning to drive in a specific simulation condition. However, as on-policy data is sequentially sampled and added in an iterative manner, the policy can specialize and overfit to the training conditions. For real-world applications, it is useful for the learned policy to generalize to novel scenarios that differ from the training conditions. To improve policy learning while maintaining robustness when training end-to-end driving policies, we perform an extensive analysis of data aggregation techniques in the CARLA environment. We demonstrate how the majority of them have poor generalization performance, and develop a novel approach with empirically better generalization performance compared to existing techniques. Our two key ideas are (1) to sample critical states from the collected on-policy data based on the utility they provide to the learned policy in terms of driving behavior, and (2) to incorporate a replay buffer which progressively focuses on the high uncertainty regions of the policy's state distribution. We evaluate the proposed approach on the CARLA NoCrash benchmark, focusing on the most challenging driving scenarios with dense pedestrian and vehicle traffic. Our approach improves driving success rate by 16% over state-of-the-art, achieving 87% of the expert performance while also reducing the collision rate by an order of magnitude without the use of any additional modality, auxiliary tasks, architectural modifications or reward from the environment.
Latex Bibtex Citation:
@inproceedings{Prakash2020CVPR,
author = {Aditya Prakash and Aseem Behl and Eshed Ohn-Bar and Kashyap Chitta and Andreas Geiger},
title = {Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Latex Bibtex Citation:
@inproceedings{Prakash2020CVPR,
author = {Aditya Prakash and Aseem Behl and Eshed Ohn-Bar and Kashyap Chitta and Andreas Geiger},
title = {Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}