Monocular 3D scene understanding tasks, such as
object size estimation, heading angle estimation
and 3D localization, is challenging. Successful
modern day methods for 3D scene understanding
require the use of a 3D sensor such as a depth
camera, a stereo camera or LiDAR. On the other
hand, single image based methods have
significantly worse performance, but rightly so,
as there is little explicit depth information in
a 2D image. In this work, we aim at bridging the
performance gap between 3D sensing and 2D sensing
for 3D object detection by enhancing LiDAR-based
algorithms to work with single image input.
Specifically, we perform monocular depth
estimation and lift the input image to a point
cloud representation, which we call pseudo-LiDAR
point cloud. Then we can train a LiDAR-based 3D
detection network with our pseudo-LiDAR end-to-
end. Following the pipeline of two-stage 3D
detection algorithms, we detect 2D object
proposals in the input image and extract a point
cloud frustum from the pseudo-LiDAR for each
proposal. Then an oriented 3D bounding box is
detected for each frustum. To handle the large
amount of noise in the pseudo-LiDAR, we propose
two innovations: (1) use a 2D-3D bounding box
consistency constraint, adjusting the predicted
3D bounding box to have a high overlap with its
corresponding 2D proposal after projecting onto
the image; (2) use the instance mask instead of
the bounding box as the representation of 2D
proposals, in order to reduce the number of
points not belonging to the object in the point
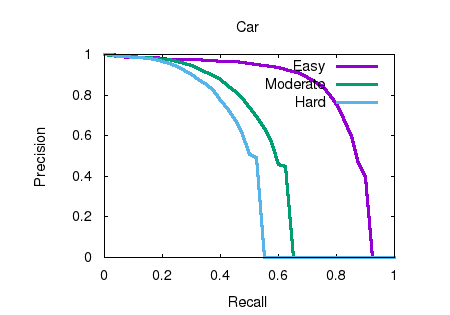
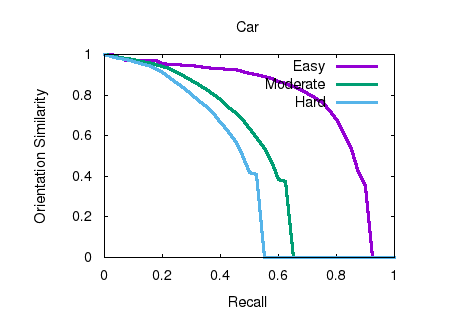
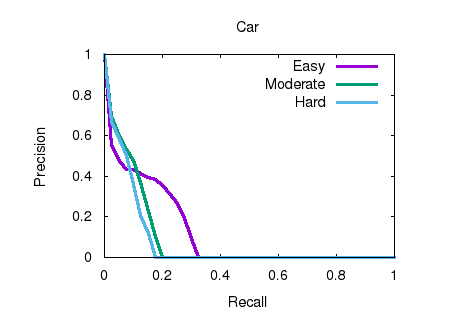
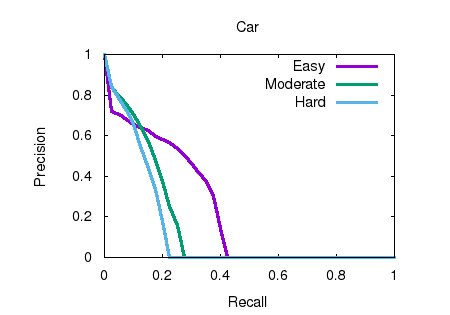
cloud frustum. Through our evaluation on the
KITTI benchmark, we achieve the top-ranked
performance on both bird’s eye view and 3D object
detection among all monocular methods,
effectively quadrupling the performance over
previous state-of-the-art. |
@article{Weng2019,
archivePrefix = {arXiv},
arxivId = {1903.09847},
author = {Weng, Xinshuo and Kitani, Kris},
eprint = {1903.09847},
journal = {arXiv:1903.09847},
title = {{Monocular 3D Object Detection with
Pseudo-LiDAR Point Cloud}},
url = {https://arxiv.org/pdf/1903.09847.pdf},
year = {2019}
}
|