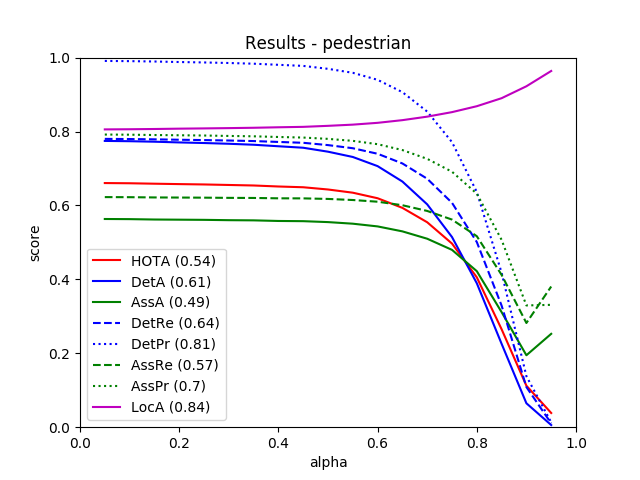
From all 29 test sequences, our benchmark computes the HOTA tracking metrics (HOTA, DetA, AssA, DetRe, DetPr, AssRe, AssPr, LocA) [1] as well as the CLEARMOT, MT/PT/ML, identity switches, and fragmentation [2,3] metrics.
The tables below show all of these metrics.
| Benchmark |
HOTA |
DetA |
AssA |
DetRe |
DetPr |
AssRe |
AssPr |
LocA |
| PEDESTRIAN |
54.04 % |
60.83 % |
49.45 % |
64.13 % |
81.47 % |
56.68 % |
70.44 % |
83.71 % |
| Benchmark |
TP |
FP |
FN |
| PEDESTRIAN |
15829 |
4868 |
463 |
| Benchmark |
MOTSA |
MOTSP |
MODSA |
IDSW |
sMOTSA |
| PEDESTRIAN |
72.89 % |
81.50 % |
74.24 % |
279 |
58.75 % |
| Benchmark |
MT rate |
PT rate |
ML rate |
FRAG |
| PEDESTRIAN |
47.41 % |
37.04 % |
15.56 % |
522 |
| Benchmark |
# Dets |
# Tracks |
| PEDESTRIAN |
16292 |
293 |
This table as LaTeX
|
[1] J. Luiten, A. Os̆ep, P. Dendorfer, P. Torr, A. Geiger, L. Leal-Taixé, B. Leibe:
HOTA: A Higher Order Metric for Evaluating Multi-object Tracking. IJCV 2020.
[2] K. Bernardin, R. Stiefelhagen:
Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. JIVP 2008.
[3] Y. Li, C. Huang, R. Nevatia:
Learning to associate: HybridBoosted multi-target tracker for crowded scene. CVPR 2009.