Object Scene Flow for Autonomous Vehicles

We propose a novel model and dataset for 3D scene flow estimation with an application to autonomous driving. Taking advantage of the fact that outdoor scenes often decompose into a small number of independently moving objects, we represent each element in the scene by its rigid motion parameters and each superpixel by a 3D plane as well as an index to the corresponding object. This minimal representation increases robustness and leads to a discrete-continuous CRF where the data term decomposes into pairwise potentials between superpixels and objects. Moreover, our model intrinsically segments the scene into its constituting dynamic components. We demonstrate the performance of our model on existing benchmarks as well as a novel realistic dataset with scene flow ground truth. We obtain this dataset by annotating 400 dynamic scenes from the KITTI raw data collection using detailed 3D CAD models for all vehicles in motion. Our experiments also reveal novel challenges which cannot be handled by existing methods. The figure above depicts from top-left to bottom-right: The input image with inferred segmentation into moving object hypotheses, the optical flow produced by our method, the disparity and optical flow ground truth of our novel scene flow dataset. More recently, we have extended our method to capture the shape of an object by jointly inferring the parameters of an active shape model. For further information, have a look at the references at the bottom of this page.
Model
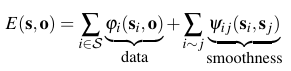
where s determines the shape and associated object of a superpixel, and o are the rigid motion parameters of all objects in the scene.
Dataset
Results
Below, we show some of our qualitative results on the proposed dataset. Each subfigure shows from top-to-bottom: disparity and optical flow ground truth in the reference view, the disparity map (D1) and optical flow map (Fl) estimated by our algorithm, and the respective error images using the color scheme described in the paper (blue = correct estimates, red = wrong estimates). The last two scenes are failure cases of our method due to extreme motions or difficult illumination conditions.







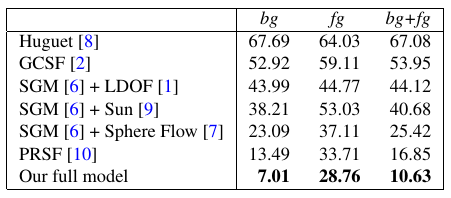
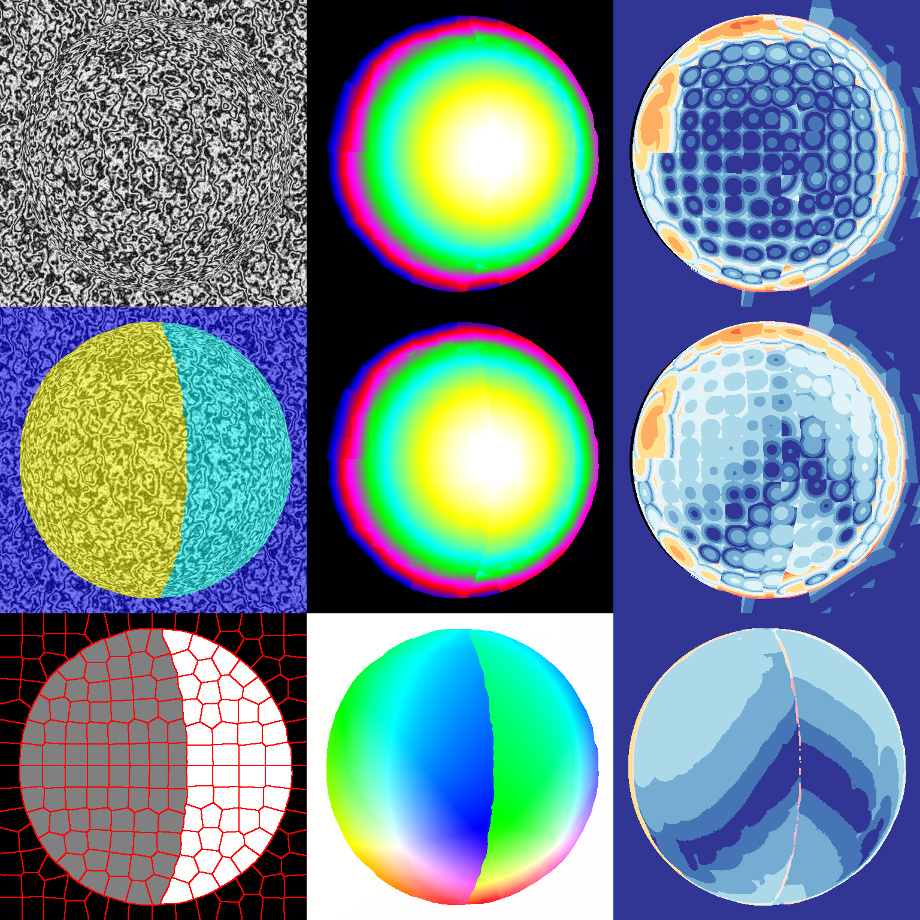
Below, we show results of our method on the Sphere dataset (Huguet et al. 2007). Due to the fundamental different properties of this dataset, we have chosen a different parameter setting and based the calculation of the superpixels on optical flow instead of intensities. Each subfigure shows from top-left to bottom-right: The input image, the estimated disparity map in the first frame, the respective disparity error, the estimated segmentation into different flow components, the estimated disparity map in the second frame, the respective disparity error, the superpixelization obtained from optical flow, the estimated optical flow, and the optical flow error.
Video
Changelog
- 26.08.2015: First version online!
Download
- Paper (pdf, 6 MB)
- Extended Abstract (pdf, 1 MB)
- Supplementary Material (pdf, 21 MB)
- Poster (pdf, 10 MB)
- Slides (pdf, 37 MB)
- Code (Matlab/C++, 4 MB)
- Datasets: Stereo 2015 / Optical Flow 2015 / SceneFlow 2015
Citation
@article{Menze2018JPRS,
author = {Moritz Menze and Christian Heipke and Andreas Geiger},
title = {Object Scene Flow},
journal = {ISPRS Journal of Photogrammetry and Remote Sensing (JPRS)},
year = {2018}
}
@inproceedings{Menze2015CVPR,
author = {Moritz Menze and Andreas Geiger},
title = {Object Scene Flow for Autonomous Vehicles},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
}
@inproceedings{Menze2015ISA,
author = {Moritz Menze and Christian Heipke and Andreas Geiger},
title = {Joint 3D Estimation of Vehicles and Scene Flow},
booktitle = {ISPRS Workshop on Image Sequence Analysis (ISA)},
year = {2015}
}