3D Urban Scene Understanding
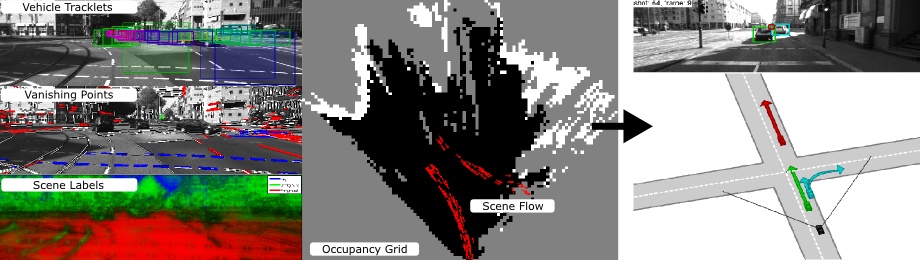
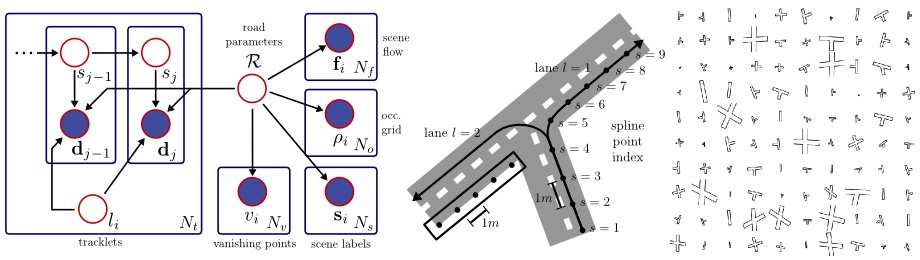
In this project, we investigate probabilistic generative model for multi-object traffic scene understanding from movable platforms which reason jointly about the 3D scene layout as well as the location and orientation of objects in the scene. In particular, we are interested in inferring the scene topology, geometry and traffic activities from short video sequences. Inspired by the impressive driving capabilities of humans, our models do not rely on GPS, lidar or map knowledge. Instead, they take advantage of a diverse set of visual cues in the form of vehicle tracklets, vanishing points, semantic scene labels, scene flow and occupancy grids. For each of these cues we propose likelihood functions that are integrated into a probabilistic generative model. We learn all model parameters from training data using contrastive divergence. Experiments conducted on videos of 113 representative intersections show that we are able to successfully infer the correct layout in a variety of very challenging scenarios. To evaluate the importance of each feature cue, experiments using different feature combinations are conducted. Furthermore, we show how by employing context we are able to improve over the state-of-the-art in terms of object detection and object orientation estimation in challenging and cluttered urban environments.
Here is a short overview of the relevant publications. For bibtex citations please scroll further down this page!
- 3D Traffic Scene Understanding from Movable Platforms (PAMI 2014): This is a summary paper of the NIPS and CVPR 2011 papers, combining monocular and stereo cues for intersection understanding and proposing to learn parameters via contrastive divergence. The code provided on this page has been used to generate the results in this paper.
- Probabilistic Models for 3D Urban Scene Understanding from Movable Platforms (PhD Thesis 2013): This is my PhD thesis, containing the same material as the PAMI 2014 paper, but with more details about each individual part of the proposed approach and more experimental results.
- Understanding High-Level Semantics by Modeling Traffic Patterns (ICCV 2013): This is an extension of our initial models that doesn't model tracklets independently, but takes into account traffic patterns and uses a more precise lane representation model.
- Joint 3D Estimation of Objects and Scene Layout (NIPS 2011): The original paper on monocular 3D traffic scene understanding.
- A Generative Model for 3D Urban Scene Understanding from Movable Platforms (CVPR 2011): The original paper using stereo features.
Downloads
- intersection_code.zip (1 MB): Code for learning and inference, includes readme.txt.
- tracking by detection code (only the 2D part)
- intersection_shots.zip (72 MB): Pre-computed features.
- intersection_experiments.zip (111 MB): Learned parameters and experimental results.
- intersection_sequences.zip (5 GB): Full input stereo image sequences (optional).
Citation
@article{Geiger2014PAMI,
author = {Andreas Geiger and Martin Lauer and Christian Wojek and Christoph Stiller and Raquel Urtasun},
title = {3D Traffic Scene Understanding from Movable Platforms},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2014}
}
@phdthesis{Geiger2013,
author = {Andreas Geiger},
title = {Probabilistic Models for 3D Urban Scene Understanding from Movable Platforms},
school = {KIT},
year = {2013}
}
@inproceedings{Zhang2013ICCV,
author = {Hongyi Zhang and Andreas Geiger and Raquel Urtasun},
title = {Understanding High-Level Semantics by Modeling Traffic Patterns},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2013}
}
@inproceedings{Geiger2011NIPS,
author = {Andreas Geiger and Christian Wojek and Raquel Urtasun},
title = {Joint 3D Estimation of Objects and Scene Layout},
booktitle = {Advances in Neural Information Processing Systems (NIPS)},
year = {2011}
}
@inproceedings{Geiger2011CVPR,
author = { GeigerandAndreas and LauerandMartin and UrtasunandRaquel},
title = {A Generative Model for 3D Urban Scene Understanding from Movable Platforms},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2011}
}